0. 引言
这篇文章的起因是在于之前考察cross entroy相关的内容的时候,发现工具调用的太多了导致很多基础的内容被搞得生疏了,因此,就打算整两篇笔记来好好整理一下激活函数、损失函数等一些比较基础的概念性的东西,打算是分这几个模块来着:
- 常用激活函数;
- 常用损失函数;
- 常用优化器;
这篇文章,我们主要来看一下一些常用的激活函数以及他们使用的场景。
不过,由于我的方向主要是NLP方向的,因此在图像以及asr领域难免会有不少不了解的内容,因此,如果有什么遗漏的内容还望见谅,也希望读者可以在下方的评论区中随时进行相关内容的补充。
感激不尽!
1. 常用激活函数
1. sigmoid
sigmoid算是最为经典的一个激活函数了,其定义公式为:
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1
给出pytorch官网上给出的sigmoid函数曲线如下:
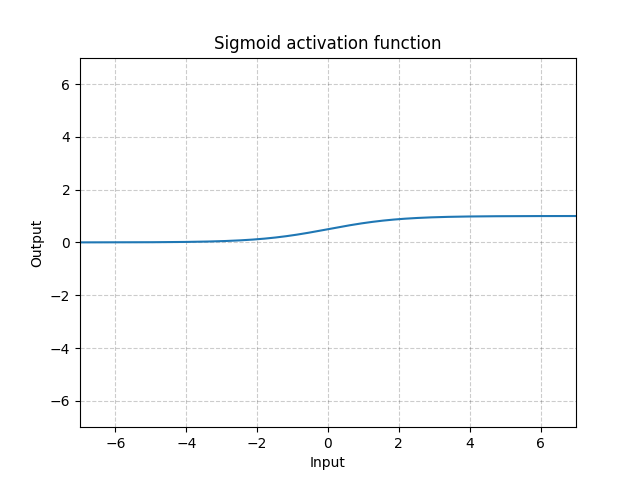
这个激活函数给我的使用感受有点像是一个万金油式的激活函数,它主要的功能除了使得输入非线性化之外,还能够使输入映射到 0 0 0到 1 1 1的取值范围之间,但是缺点在于他只对于0附近的元素变化敏感,当元素本身很大或者很小时,他就常常会引发后续的梯度弥散现象。
目前,就我所知的sigmoid激活函数的使用场景感觉已经不是很多了,反正transformer系列模型之中并没有用到,而LSTM当中虽然有用到,但是更多的还是侧重其在 0 1 0~1 0 1之间的映射关系。
不过这终究是一个经典的激活函数,还是有必要放在这里一说的。
2. softmax
softmax严格来说事实上不算是一个激活函数,更多的情况下是用于概率上的归一化操作,他的计算公式表达如下:
s o f t m a x ( x ⃗ ) = e x i ∑ e x i softmax(\vec{x}) = \frac{e^{x_{i}}}{\sum{e^{x_i}}} softmax(x)=∑exiexi
它最大的作用是将一个非归一化的向量转换为总和为1的概率分布。
因此,他常常用于分类问题的最后一层作为激活函数。
但事实上,但凡涉及到概率的地方基本都会用到softmax,典型的就比如attention layer当中,都会使用softmax来计算attention值。
3. relu系列
relu系列大约是现今被使用最多的激活函数系列了,本质上来说,他们都是一些分段线性函数,从transformer到cnn网络当中,他们都有着极为广泛的应用,这里,我们就来整体看一下这一系列的激活函数。
1. relu
relu是这一些列函数的最基础版本,他的定义公式如下:
r e l u ( x ) = { x x ≥ 0 0 x < 0 relu(x) = \begin{cases} x & & {x \geq 0} \\ 0 & & {x < 0} \end{cases} relu(x)={ x0x≥0x<0
即是说,当x大于0时,他是一个线性函数;当x小于0时,他退化为一个常数。
同样,给出pytorch官网中给出的relu函数曲线图如下:

relu函数较之sigmoid函数的一个优点在于他的梯度是一个常数,因此,即使对于极深的网络结构,relu激活函数也不太容易出现梯度弥散的情况,这大约也就是为什么在深层网络当中relu才是主流激活函数的核心原因吧。
2. leaky relu
leaky relu是relu函数的一个变体,它主要针对x小于0的部分进行优化。在relu当中,它令所有小于0的输入的函数输出均为0,其相应的梯度也全都是0,因此梯度回传回被截断。
而leaky relu对此进行了优化,他将小于零的部分变成了一个小梯度的线性函数,从而避免了其梯度为0的情况。
给出leaky relu的函数表达如下:
L e a k y R e l u ( x ) = { x x ≥ 0 α ⋅ x x < 0 LeakyRelu(x) = \begin{cases} x & & {x \geq 0} \\ \alpha \cdot x & & {x < 0} \end{cases} LeakyRelu(x)={ xα⋅xx≥0x<0
同样给出其函数曲线如下:
3. elu
elu同样是relu函数的一个变体,他的函数表达如下:
e l u ( x ) = { x x ≥ 0 α ⋅ ( e x − 1 ) x < 0 elu(x) = \begin{cases} x & & {x \geq 0} \\ \alpha \cdot (e^{x}-1) & & {x < 0} \end{cases} elu(x)={ xα⋅(ex−1)x≥0x<0
同样给出pytorch官网中的函数曲线图如下。
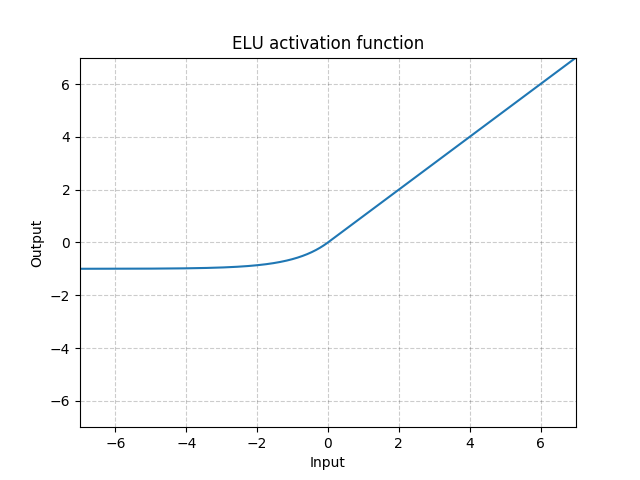
可以看到,较之relu函数,elu函数最主要的优化点有二:
- 函数的斜率曲线从原先的分段函数变成了连续函数,间断点位置进行了平滑处理;
- 当输入值远小于0时,输出不再为0,而变成了一个预设的常值 − α -\alpha −α。
4. selu
selu同样也是relu的一个变体,算是久闻其大名吧,不过selu在nlp领域里面感觉用的不多,所以这里仅仅给出一些我粗浅的了解。
首先,我们同样给出selu的函数表达式如下:
s e l u ( x ) = λ ⋅ { x x ≥ 0 α ⋅ ( e x − 1 ) x < 0 selu(x) = \lambda \cdot \begin{cases} x & & {x \geq 0} \\ \alpha \cdot (e^{x}-1) & & {x < 0} \end{cases} selu(x)=λ⋅{ xα⋅(ex−1)x≥0x<0
其中:
- λ = 1.0507009873554804934193349852946 \lambda = 1.0507009873554804934193349852946 λ=1.0507009873554804934193349852946
- α = 1.6732632423543772848170429916717 \alpha = 1.6732632423543772848170429916717 α=1.6732632423543772848170429916717
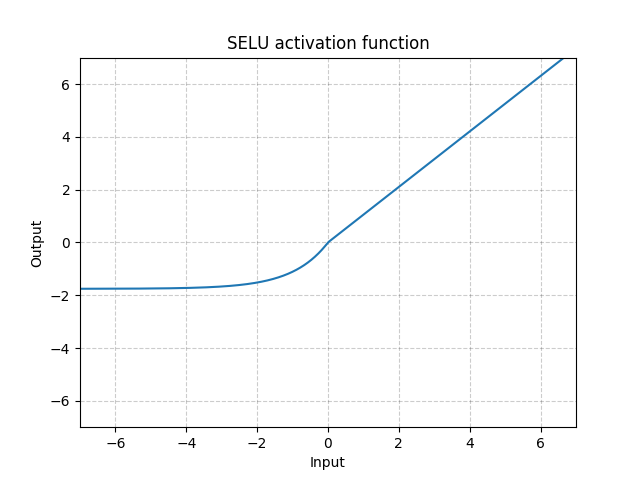
selu来源于paper: Self-Normalizing Neural Networks。
他的核心思路在于:
- 在调用了selu激活函数之后,希望生成的结果自动归一化到均值为0而方差为1的情况。
给出其函数曲线图如下:
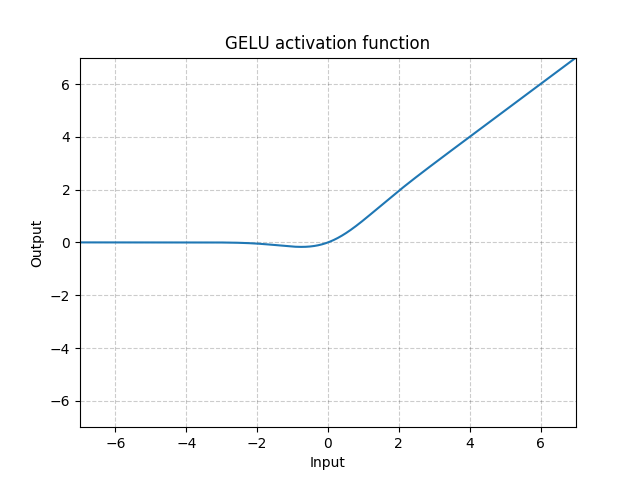
5. gelu
gelu作为relu的一个变体,同样是久闻其名,他来源于paper: GAUSSIAN ERROR LINEAR UNITS (GELUS)。
其函数定义公式如下:
g e l u ( x ) = x ⋅ Φ ( x ) gelu(x) = x \cdot \Phi(x) gelu(x)=x⋅Φ(x)
其中, Φ ( x ) \Phi(x) Φ(x)的定义为:
Φ ( x ) = ∫ − ∞ x 1 2 π e − t 2 2 d t \Phi(x) = \int_{-\infty}^{x}{\frac{1}{\sqrt{2\pi}}e^{-\frac{t^2}{2}}}dt Φ(x)=∫−∞x2π1e−2t2dt
即正态分布的累积分布。
给出其整体的函数曲线图如下:
6. 其他
除了上述这些比较常见的relu系列函数之外,relu还有其他一些各种各样的变种,比如celu,softplus,relu6等等,这里,就简单罗列一些pytorch官网上给出的相关激活函数的表达公式如下,但是细节就不过多展开了,有兴趣的读者可以自行去研究一下。
-
celu
c e l u ( x ) = { x x ≥ 0 α ⋅ ( e x α − 1 ) x < 0 celu(x) = \begin{cases} x & & x \geq 0 \\ \alpha \cdot (e^{\frac{x}{\alpha}} - 1) & & x < 0 \end{cases} celu(x)={ xα⋅(eαx−1)x≥0x<0
-
softplus
s o f t p l u s ( x ) = 1 β ⋅ l o g ( 1 + e β ⋅ x ) softplus(x) = \frac{1}{\beta} \cdot log(1 + e^{\beta \cdot x}) softplus(x)=β1⋅log(1+eβ⋅x)
-
relu6
r e l u 6 ( x ) = { 6 x ≥ 6 x 0 ≤ x < 6 0 x < 0 relu6(x) = \begin{cases} 6 & & {x \geq 6} \\ x & & {0 \leq x < 6} \\ 0 & & {x < 0} \end{cases} relu6(x)=⎩⎪⎨⎪⎧6x0x≥60≤x<6x<0
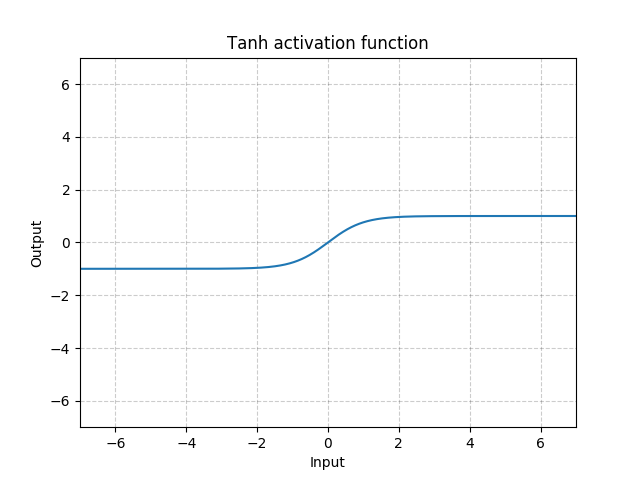
4. tanh
tanh激活函数主要用于lstm网络当中,用于生成输入的状态更新向量,但除此之外,似乎鲜见tanh函数作为激活函数的应用,而随着transformer的崛起,tanh的地位总感觉愈发的尴尬。。。
但是,whatever,这里,还是给出其公式定义如下:
t a n h ( x ) = e x − e − x e x + e − x tanh(x) = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} tanh(x)=ex+e−xex−e−x
5. 其他
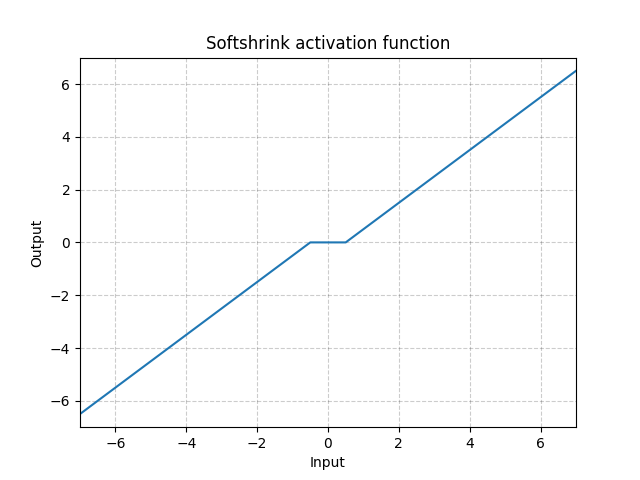
除了上述提及的这些激活函数之外,还有许许多多的激活函数,很多也是我今天整理的时候看了pytorch的官网上才知道的,比如说soft shrink和tanh shrink这两个激活函数,简至崩碎了我的三观,他们的定义分别如下:
-
soft shrink
S o f t S h r i n k ( x ) = { x − λ x > λ 0 − λ < x < λ x + λ x < − λ SoftShrink(x) = \begin{cases} x - \lambda & & x > \lambda \\ 0 & & -\lambda < x < \lambda \\ x + \lambda & & x < -\lambda \end{cases} SoftShrink(x)=⎩⎪⎨⎪⎧x−λ0x+λx>λ−λ<x<λx<−λ
-
tanh shrink
S o f t S h r i n k ( x ) = x − e x − e − x e x + e − x SoftShrink(x) = x - \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} SoftShrink(x)=x−ex+e−xex−e−x
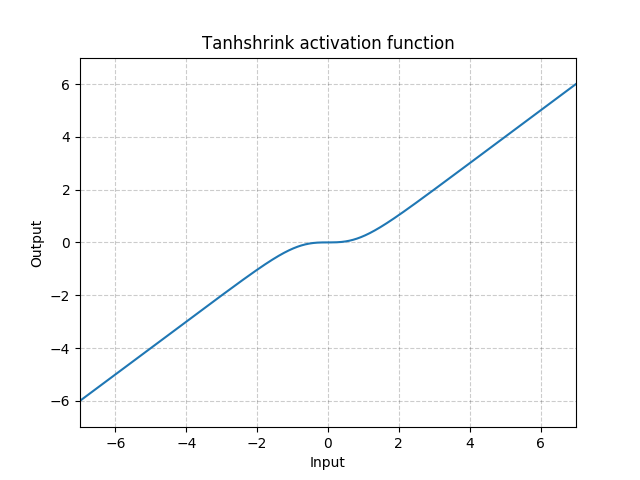
可以看到,他们在当输入在0附近时,梯度近乎为0,而在输入极大或极小时,梯度反而为正常梯度,这就和我们平时的使用经验非常的不一致,反正我个人从未见过这两个激活函数的使用场景,如果有了解的朋友请务必在评论区里面告知一下,感谢!
2. 总结
至此,我们便大致整理了一下一些常见的激活函数,整理得到表格如下:
| 激活函数 | 表达式 | 常见使用场景 | 特点 |
|---|---|---|---|
| sigmoid | s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1 | 浅层网络 | 当输入很大或很小时,梯度很小,容易出现梯度弥散的情况 |
| relu系列 (以relu为例) |
r e l u ( x ) = { x x ≥ 0 0 x < 0 relu(x) = \begin{cases}x & & {x \geq 0} \\ 0 & & {x < 0} \end{cases} relu(x)={ x0x≥0x<0 | 深层神经网络 | 梯度比较稳定,不会因为输入太大或太小而出现梯度弥散的情况 |
| tanh | t a n h ( x ) = e x − e − x e x + e − x tanh(x) = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} tanh(x)=ex+e−xex−e−x | rnn系列网络 | |
| softmax | s o f t m a x ( x ⃗ ) = e x i ∑ e x i softmax(\vec{x}) = \frac{e^{x_{i}}}{\sum{e^{x_i}}} softmax(x)=∑exiexi | 概率相关场景 1.输出层; 2.attention层 |