前言
一个月前曾学习过爬取腾讯动漫全站的示例代码,现在再用scrapy尝试
过程
新建spider爬虫
编写普通selenium爬虫爬取漫画
观察网页,确定目标
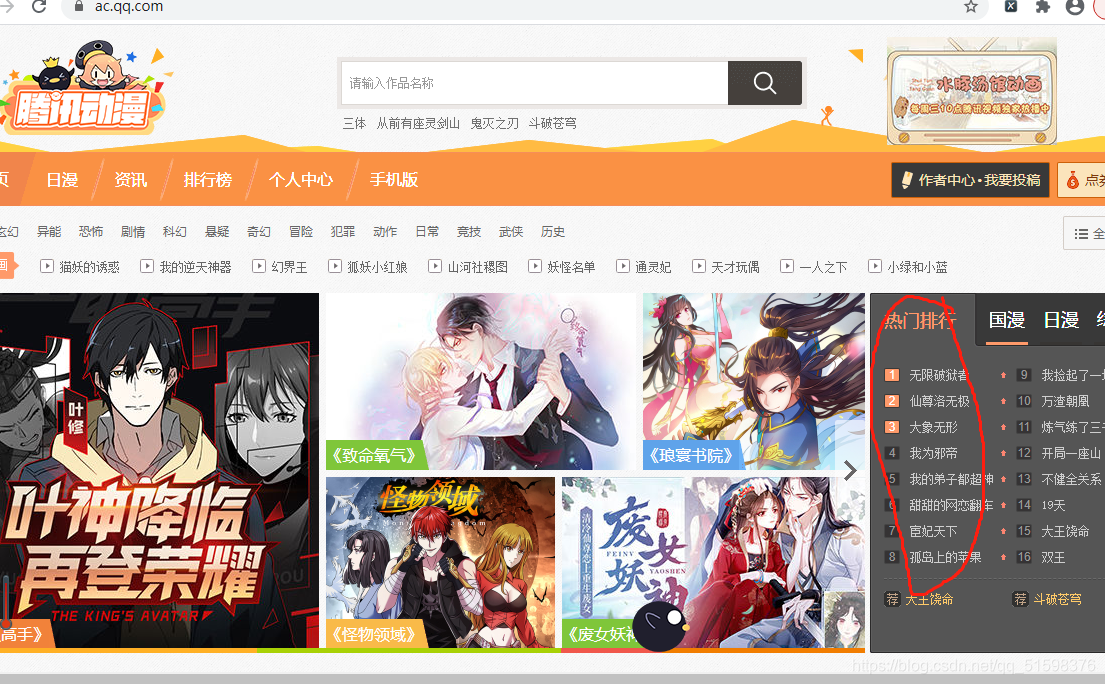
本次目标是爬取热门排行下的漫画
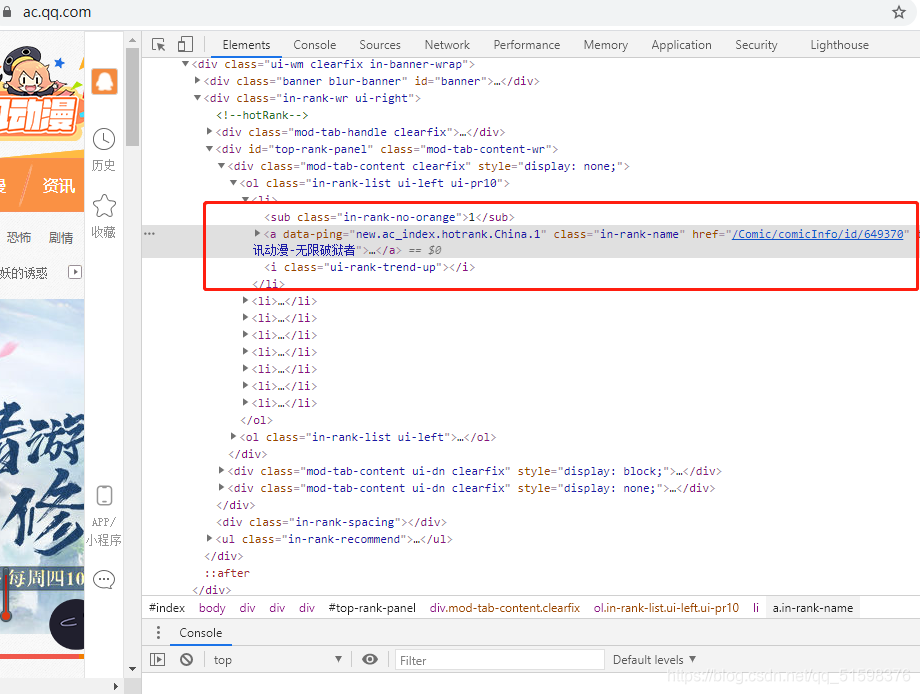
右键检查可以发现漫画标题和链接可以轻松获取(前提是用selenium)
爬取内容
主要目的是为了练习scrapy的selenium,方便起见,只爬取第一部漫画`的少量信息
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import time
driver = webdriver.Chrome()
url = "https://ac.qq.com/"
driver.get(url)
#显示等待
time.sleep(2)
subjects = driver.find_elements_by_xpath("//a[contains(@class,'in-rank-name')]")
subject = subjects[0]
title = subject.text
print(title)
href = subject.get_attribute("href")
print(href)
爬取得到
无限破狱者
https://ac.qq.com/Comic/comicInfo/id/649370
然后用selenium进入该漫画网址并点击阅读
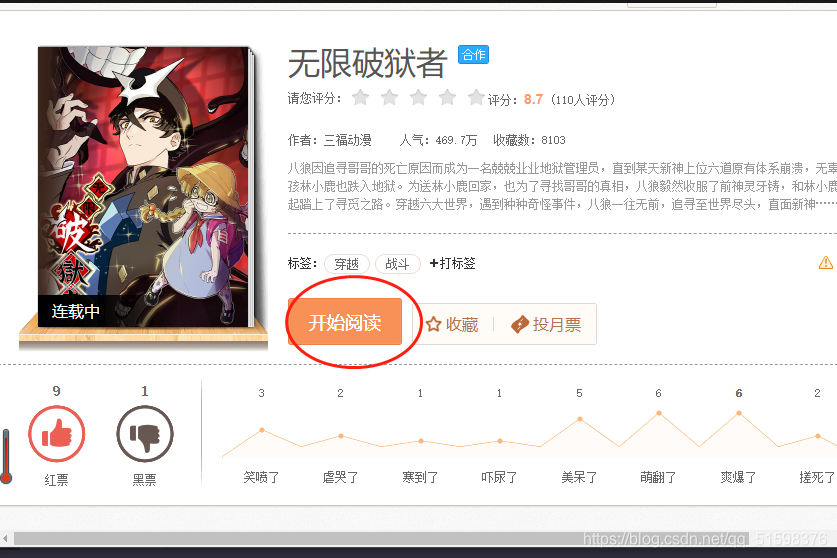
driver.get(manhua_url)
time.sleep(2)
driver.find_element_by_xpath("/html/body/div[3]/div[3]/div/div/div[2]/em/div/div[1]/div/a").click()
time.sleep(2)
#操作滚动条
js = 'var q=document.getElementById("mainView").scrollTop = ' + str(100 * 1000)#这个不知如何找是重点
#执行滑动选项
driver.execute_script(js)
#延时,使图片充分加载
time.sleep(2)
img_list = driver.find_elements_by_xpath("//img[contains(@class,'loaded')]")
for i in img_list:
print(i.get_attribute("src"))
得到
https://manhua.acimg.cn/manhua_detail/0/03_16_24_a7ac725928a655f2f8538a2ee1e46b8f5_115731672.jpg/0
https://manhua.acimg.cn/manhua_detail/0/03_16_24_a62281dd035262f3a21ef4f03fc92e411_115731695.jpg/0
https://manhua.acimg.cn/manhua_detail/0/03_16_24_ac9393b3d58918890d808c3139a91f840_115731692.jpg/0
https://manhua.acimg.cn/manhua_detail/0/03_16_24_a668de4c3ad19e491aa91f561b890e395_115731723.jpg/0
https://manhua.acimg.cn/manhua_detail/0/03_16_24_a3b706d347a1317b9a9a3ecea4688afc5_115731699.png/0
此时selenium爬取主要思路已经完成,接下来是用scrapy完成这个思路
使用scrapy
流程梳理和重点分析
- 重点是midderware的改写
- settings.py先打开下载中间件
- 然后midderwares.py改写
- 接着tengxun.py编写爬虫,其中LinkExtractor的规则制定是重点
- 过程中的bug可能不好找到排除
过程
改写midderwares.py
from scrapy import signals
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from scrapy.http.response.html import HtmlResponse
class ManhuaDownloaderMiddleware:
def __init__(self):
self.driver = webdriver.Chrome()
def process_request(self, request, spider):
self.driver.get(request.url)
response = HtmlResponse(request.url, body=self.driver.page_source, request=request, encoding='utf-8')
return response
settings.py打开中间件
DOWNLOADER_MIDDLEWARES = {
'manhua.middlewares.ManhuaDownloaderMiddleware': 543,
}
编写爬虫
2021-02-21
腾讯动漫网页好像有变化

现在图片url从网页直接获取不到
用selenium也没用,也许只能通过分析接口获取
不过增加了了scrapy加selenium的熟练度
放一下已经没用了的代码,改一下domains,start_urls,Rule也能爬取别的东西,scrapy框架一招鲜吃遍天
from scrapy.spiders import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
class TengxunSpider(CrawlSpider):
name = 'tengxun'
allowed_domains = ['ac.qq.com']
start_urls = [r'https://ac.qq.com/']
rules = [
Rule(link_extractor=LinkExtractor(allow=r'https://ac.qq.com/Comic/comicInfo/id/648421'), follow=True),
Rule(link_extractor=LinkExtractor(allow=r'https://ac.qq.com/ComicView/index/id/648421/cid/1'), callback="parse_detail", follow=False),
]
def parse_detail(self, response):
title = response.xpath("//text()").get()
print(title)
总结
1.scrapy+selenium比单纯的用selenium强了无数倍,速度极快,简化操作,无需等待无需定位,可以专心解析
2.有时parse_detail函数没有被调用,此疑问待解决