文章目录
前言
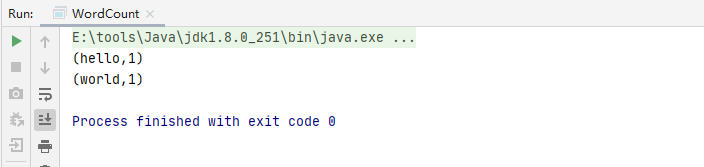
1.txt
hello world
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local")
.appName("wordCount")
.getOrCreate()
val value = spark.sparkContext.textFile("data/wordcount/1.txt")
.flatMap(w => w.split(" ")).map((_, 1)).reduceByKey(_ + _);
value.collect.foreach(println);
}
执行时,很多日志打印,很乱,这些日志一般不需要看的。想要寻找想要的信息,翻来翻去翻半天。
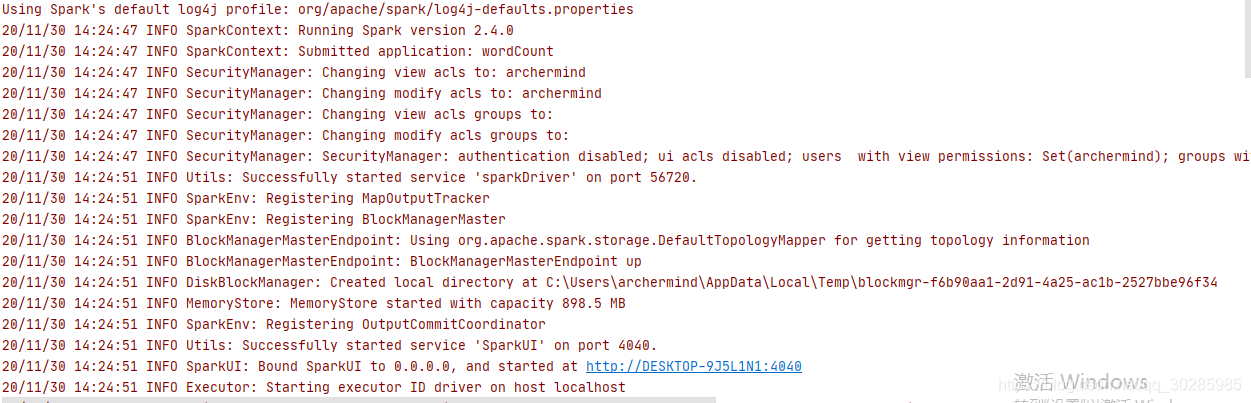
接下来关闭这些日志的打印
1.新建log4j.properties
在resource目录下新建log4j.properties文件。
代码如下(填写):
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd
HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell,
the
# log level for this class is used to overwrite the root logger's log level, so
that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent
UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
注意目录位置,目录错了 就没作用了。
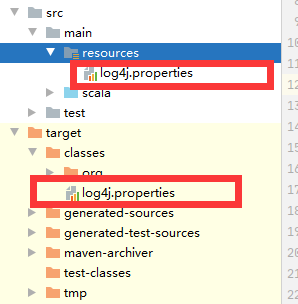
新建完成之后,再次请求,如下: