本地使用scala开发spark,首先需要安装和配置scala,spark以及hadoop环境。
scala安装
在scala官网下载,https://www.scala-lang.org/download/ 我选择的是scala 2.13版本,下载完成后,scala配置到系统的path中去,配置方法像jdk那种。
spark和hadoop环境安装
下载spark的地址:http://spark.apache.org/downloads.html ,入下图所示,我下载是图中的spark-3.0.3-bin-hadoop2.7.tgz,根据文件名称我们可以知道,下载hadoop必须要hadoop 2.7才可以。

下载hadoop地址: https://archive.apache.org/dist/hadoop/common/hadoop-2.7.1/ 。

spark与hadoop下载完毕后,他们两者放到指定目录下解压即可,然后对应的bin配置在path中。
解压spark,我的spark解压的路径为:C:\workspace\spark-3.0.3-bin-hadoop2.7
解压hadoop,解压路径为: C:\workspace\hadoop-2.7.1
然后在系统中的环境变量中配置SPARK_HOME为
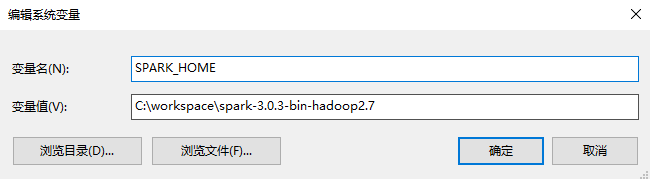
在path中添加
%SPARK_HOME%\bin,%SPARK_HOME%\sbin
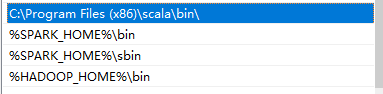
Hadoop也是如此,在环境变量中HADOOP_HOME,然后在path中添加%HADOOP_HOME%\bin即可。

在配置完成后,在cmd中运行spark-shell时会出现没有winutils.exe的错误,根据如下的链接,下载被拷贝到hadoop的bin目录下(我的拷贝到C:\workspace\hadoop-2.7.1\bin目录下了)
https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
idea中运行demo程序
pom文件中需要引入如下的依赖
<spark.version>2.3.1</spark.version>
<hadoop.version>2.7.1</hadoop.version>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.47.Final</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.10</version>
</dependency>
创建项目选择的scala版本要与pom中指定的scala版本要保持一致,否则会报错

如下是在idea中创建的demo程序,程序是读取文件中的十行内容并打印出来
import org.apache.spark.{
SparkConf, SparkContext}
object CountJob {
def main(args: Array[String]): Unit = {
println(System.getenv("HADOOP_HOME"))
val conf = new SparkConf().setAppName("countJob").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd5 = sc.textFile("data/access.log")
rdd5.take(10).foreach(println(_))
}
}