对于张的单输入单输出的非线性函数,用黄的程序,隐层神经元的个数并没有太大的影响,而输入权重和偏置的范围有很大的影响。
隐层神经元数50
InputWeight=rand(NumberofHiddenNeurons,NumberofInputNeurons);
BiasofHiddenNeurons=rand(NumberofHiddenNeurons,1);

InputWeight=rand(NumberofHiddenNeurons,NumberofInputNeurons)*2-1;
BiasofHiddenNeurons=rand(NumberofHiddenNeurons,1)*2-1;

InputWeight=rand(NumberofHiddenNeurons,NumberofInputNeurons)*30-10;
BiasofHiddenNeurons=rand(NumberofHiddenNeurons,1)*10-5;

输入权重和偏置的范围的多少对结果影响很大。
1、那么到底应该怎么选择输入权重和偏置的范围呢?
看了很多论文中全是[-1,1],或者随机给的。
张的非线性函数,我把范围给的大了才行了,是不是数据没有归一化?
通过用黄的程序,即使数据归一化也不行。
2、那么到底应该怎么选择输入权重和偏置的范围呢?
发现了一篇论文谈到了输入权重和偏置范围的设置问题:
Insights into randomized algorithms for neural networks:Practical issues and common pitfalls
Ming Li, Dianhui Wang
doi.org/10.1016/j.ins.2016.12.007
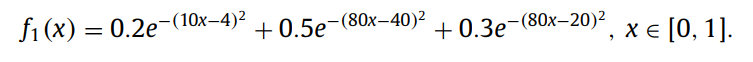

通过表1和表2可以看出输入权重和偏置的范围在[-1,1]并没有[-200,200]的效果好,从红色的圈可以看出[-200,200]的误差更小。这说明把输入权重和偏置的范围固定为[-1,1]并不是最好的。上面是对非线性函数f1来说。
对于f2也有同样的结果,如下:
意思是,输入权重和偏置取[-1,1]会出现隐层输出权重H不满秩的情况,训练以及测试性能很差。而范围固定在[-5,5],则会表现出很好的结果。
总结:这篇论文只是说了给定输入权重和偏置的范围是不合理的,然而并没有给出如何设定输入权重和偏置范围设定的方法。
3、下面这篇论文继续探讨的这一问题。
Generating random weights and biases in feedforward neural networks with random hidden nodes
DOI:10.1016/j.ins.2018.12.063
总结:这篇论文探讨的是神经元激活函数的权重a和偏置b是和输入神经元的权重和偏置范围不同的!!但是不得不说这方面也要考虑。
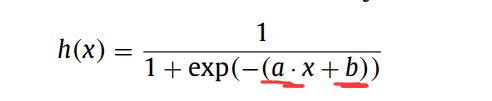
4、隐层神经元的数量和输入权重和偏置的范围是对应的,隐层神经元的数量也需要确定,但是如何确定呢?
A Study on Extreme Learning Machine for Gasoline Engine Torque Prediction中提到了隐层神经元数目如何选择。

4、通过一些使用ELM的论文,看看别人怎么设定的范围?
5、找到一篇专门讨论关于参数的论文
Some Tricks in Parameter Selection for Extreme Learning Machine
doi:10.1088/1757-899X/261/1/012002
该论文回答了几个问题
(1)是不是隐层节点数的数量越多越好呢?
作者通过对几个函数进行试验,只有隐层节点数发生变化而其他参数保持不变。
最后得到结论:并不是隐层节点数越多越好。
那么隐层节点数到底应该取多少呢?作者给出了几个参考文献用来选择隐层节点数。
one recommended is to automatically deduce the initial number of hidden nodes by using incremental constructive methods such as incremental ELM (I-ELM) [10], enhanced incremental ELM (EI-ELM) [20], bidirectional ELM (B-ELM) [21], pruned ELM (P-ELM) [22], error minimized ELM (EM-ELM) [23], etc… And then optimize the initial model to obtain the optimal network model
(2)输入节点到隐层节点的范围取经验范围[-1,1],以及偏置的范围取[0,1]是不是最好的呢?
作者值改变输入乘到隐层的取值范围分别取[-1, 1], [-10, 10], [-20, 20], and [-30, 30],而其他的参数保持不变,即 隐层节点数固定为200,偏置固定在[0,1],用Sigmoid 函数作为激活函数。对其性能进行了分析。
结论是:不同类型的数据,并不一定在范围[-1,1]上取得最优性能。我们可以改调整该范围来获取最优的性能。
One recommendation is to use the grid search or random search to obtain the best parameters for ELM model.
作者建议用网格搜索或者随机搜索的方法来求最优范围。
(3)偏置取为[0,1]是不是最好的呢?偏置范围依次选择 [0, 1], [0, 5], [0, 10], and [0, 15],其他参数不变。
结论:有好几个非线性函数的近似,最佳范围并不是[0,1]。所以可以通过调整范围获取最优值。
(4)激活函数类型不同是否影响最优性能?
结论:虽然大多数是sigmod函数性能最好,但是也存在别的函数最好的时候。
总结:这篇论文发表于2017,可以通过查找引用该文章的相关论文,继续看看这方面的进展。
如何找到的?百度学术搜Extreme Learning Machine 关键词找到了下面应用极限学习机的论文
A Study on Extreme Learning Machine for Gasoline Engine Torque Prediction
这篇论文中提到了上面的论文。
5、由于我的数据是工业数据,去找一下相关工业数据用极限学习的论文。
Robust extreme learning machine for modeling with unknown noise
https://doi.org/10.1016/j.jfranklin.2020.06.027
2019年发表的,这篇论文中指出ELM对隐层参数的范围比较敏感,它的变化会对神经网络性能有很大的影响。

6、我是如何找到这篇专门研究输入权重和偏置范围的论文的?
答:通过随机神经网络综述论文,它里面解释了随机神经网络相关论文都做了什么事情,我是这样发现的。所以找东西先看看综述论文,看看综述论文中有没有自己想要的,然后根据找到的文章再 去找相关的论文。
我只是想解决范围问题,对于具体的方法探究可能不需要,我只需要用他们的结论,要明确自己的目标。
方法:1、可以通过继续找该作者的相关论文看看有没有更深入的研究2、看看引用该论文的相关论文有没有相关的进展。