一、基础知识
1.1卷积神经网络(CNN)
CNN新出现了卷积层(Convolution层)和池化层(Pooling层), 这两种不同类型的层通常是交替的, 最后通常由一个或多个全连接层组成
卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样(池化)这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性.
诺贝尔奖获得者神经生理学家Hubel和Wie-sel早在1960年代发现了大脑视觉处理的开始阶段对视觉域的所有部分都作用了同样的局部滤波器,而在视觉处理过程进行时,信息由输入变得更广的部分整合起来的,这个工作通过层次完成. 在卷积神经网络中也遵循同样的模式, 随着我们传递到网络更深层次,每个卷积层或者池化层将会看到图像的更大范围,全连接层作为最高层的视觉层,处理全局的信息,所以为什么CNN后面一般都有全连接层.CNN 最后输出的是类别的概率值。
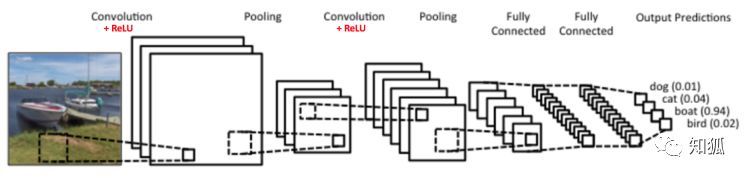
CNN 的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征。较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。
先来感受卷积神经网络的魅力
此处我参考的是https://blog.csdn.net/dengheCSDN/article/details/77848246
下图左:如果我们有1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话(每个隐层神经元都连接图像的每一个像素点),就有1000x1000x1000000=1012个连接,也就是1012个权值参数, 参数很多训练起来十分困难.然而我们知道图像的空间联系是局部的,就像人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样,我们就可以减少连接的数目,也就是减少神经网络需要训练的权值参数的个数了。如下图右:假如局部感受野是10x10,隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。比原来减少了四个0(数量级),这样训练起来就没那么费力了,但还是感觉很多的啊,那还有啥办法没?

我们知道,隐含层的每一个神经元都连接10x10个图像区域,也就是说每一个神经元存在10x10=100个连接权值参数。那如果我们每个神经元的100个参数是相同的呢?也就是说每个神经元用的是同一个卷积核去卷积图像。这样我们就只有多少个参数??只有100个参数啊!不管你隐层的神经元个数有多少,两层间的连接我只有100个参数啊!这就是权值共享。其实就是我们经常看到的下图,输出数据的每个神经元(元素)都是通过同一个卷积核(共享权重)去卷积图像然后加上同一个偏置(共享偏置)得到的.这样参数更小了,本来一个神经元对应一个卷积核一个偏置,现在是每个神经元都对应同一个卷积核同一个偏置

好了,这时我们会想,一个卷积核只提取一个特征(feature map),这样提取不靠谱吧.没事啊,我们加多几个卷积核不就行了!所以假设我们加到100种滤波器(卷积核),每种滤波器的参数不一样,表示它提出输入图像的不同特征,例如不同的边缘。这样每种滤波器去卷积图像就得到对图像的不同特征的放映,我们称之为Feature Map。所以100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元(一层网络)。到这个时候明了了吧。我们这一层有多少个参数了?100种卷积核x每种卷积核共享100个参数=100x100=10K,也就是1万个参数。才1万个参数
1.2卷积层
1.2.1卷积运算
卷积层中进行的处理时卷积运算,它相当于图像处理中的“滤波器运算”
用来作卷积运算的东西叫卷积核(核滤波器过滤器)
卷积核上的参数就对应之前的权重,此外,应用了卷积核后的数据中每个元素也加上偏置.
1.2.2填充(padding)
在进行卷积运算之前,有时要向输入数据的周围填入固定的数据(比如0等),这称为填充(padding).填充主要目的是为了调整输出的大小,不同的填充会影响输出的大小.
1.2.3步幅(stride)
向输入数据应用滤波器时,移动的位置间隔称为步幅(stride).
1.2.4如何确定输出特征图的大小
增大步幅后,输出大小会变小.而增大填充后,输出大小会变大.那么确定输出的大小呢?这里,假设输入大小为(H,W),滤波器大小为(FH,FW),输出大小为(OH,OW),填充为P,步幅为S.此时OH =( (H+2P-FH)/S ) + 1 ; OW = ((W+2P-FW)/S ) + 1
1.2.5一个卷积核做卷积
某一个卷积层中的卷积核的通道只能设定为该层输入数据的通道,而大小可自定义.
假设输入数据为(C,H,W)经过一个卷积核(C,FH,FW)后得到的输出数据为(1,OH,OW). 如下图所示:

1.2.6多个卷积核做卷积
某一个卷积层中的卷积核的数量==输出特征图(output feature map)的数量(即输出数据的通道数)
如果想输出数据是多个通道的,那么就需要用到多个卷积核(一个卷积核对应一个特征图),此外卷积核的通道需要和输入数据的通道保持一致, 例如输入数据为(C,H,W)经过FN个卷积核(C,FH,FW)后得到的输出数据为(FN,OH,OW).如下图所示:

每一个输出的通道只有一个偏置进行加法运算.如下图所示:

1.2.7批处理
卷积运算也可以进行批处理,即对N个数据进行卷积运算,也就是说批处理将N次的处理汇总成了1次进行,能够实现处理的高效化.例如N个输入数据为(C,H,W),每个数据分别经过FN个卷积核(C,FH,FW)后,得到N个输出数据为(FN,OH,OW).如下图所示

1.3池化层 (pooling层)
pooling层,也叫下采样层或子采样层(subsampling)
卷积层之后一般是pooling层,它是利用图像局部相关性的原理,对图像进行子抽样,这样在保留有用信息的同时可以减少数据处理量。pooling层不会减少feature maps的数量,只会缩减其尺寸。
没有要学习的参数 ; 经过池化运算,输入数据和输出数据的通道数不会发生变化 ; 对微小的位置变化具有鲁棒性(健壮), 输入数据发生微小偏差时, 池化仍会返回相同的结果
常用的pooling方法有两种,一种是取最大值,一种是取平均值。
1.4特征图(feature map)
有时将卷积层或者池化层的输入输出数据称为特征图(feature map),输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)
卷积核的数量==输出特征图(output feature map)的数量, 即一个卷积核提取特征
1.5感受野(Receptive Field)
1.5.1定义
感受野(Receptive Field)的定义是卷积神经网络中输出特征图上每个元素在输入特征图上映射的区域大小
感受野的大小和滤波器大小(kernel size)和步长(stride)有关,而涉及到这两个参数的有卷积层和池化层(pooling),因此经过卷积层和池化层时,感受野的大小会变化,但是填充(Padding)参数是不影响感受野大小
1.5.2意义
感受野的值越大表示其能接触到的原始图像(指输入特征图)范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次.
1.5.3感受野的计算
原文来自:https://www.jianshu.com/p/9997c6f5c01e
公式(k_n, s_n, r_n分别表示第n层的kernel_size,stride,receptive_field)
r_0 = 1 (最原始图像的每个单元的感受野默认为1)
r_1 = k_1
r_n = r_n-1 * k_n - (k_n - 1) * (r_n - s_0*…*s_n-1) 在n>2情况下
在原文例子AlexNet中,通过每一层的卷积和池化后, 感受野的大小也越来越大, 这也验证了我对CNN之前的理解,即随着我们传递到网络更深层次,每个卷积层或者池化层将会看到图像的更大范围
1.6共享权重和偏置
共享权重和偏置权值共享权值复制==参数共享
输出数据的每个神经元(元素)都是通过同一个卷积核(共享权重)去卷积图像然后加上同一个偏置(共享偏置)得到的.这样参数更小了,本来一个神经元对应一个卷积核一个偏置,现在是每个神经元都对应同一个卷积核同一个偏置
