1 Spark内核概述
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制、Spark任务调度机制、Spark内存管理机制、Spark核心功能的运行原理。
1.1 Spark核心组件
(1)Yarn(RM & NM)
(2)Spark(AM & Driver & Executor)
①Driver
SparK驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责:
- 将用户程序转化为作业(Job)
- 在Executor之间调度任务(Task)
- 跟踪Executor的执行情况
- 通过UI展示查询运行情况
②Executor
Spark Executor是通过ExecutorBackend创建一个Executor对象。
– Spark应用启动时,ExecutorBackend节点被同时启动,并且始终伴随整个Spark应用的生命周期。如果有ExecutorBackend节点发生了故障或崩溃,Spark应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能:
- 负责运行组成Spark应用的任务,并将结果返回给驱动器(Driver)
- 他们通过自身的块管理(Block Manger)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
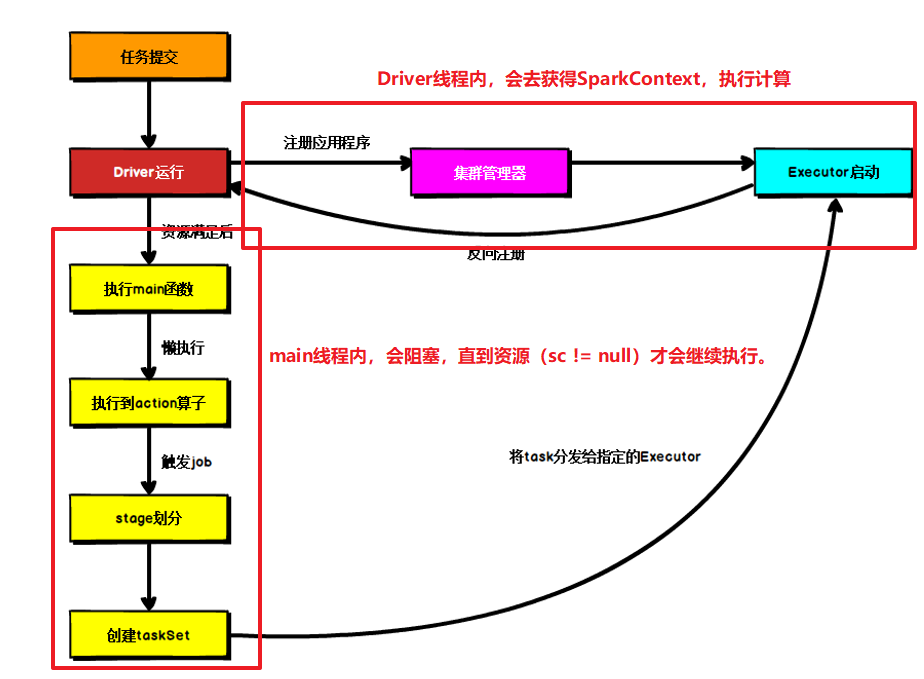
1.2 Spark运行流程
-
步骤1:SparkSubmit提交任务后,会根据prepareSubmitEnvironment()中的childMainClass决定提交的是什么类型的SparkApplication,如果没有SparkApplication,会new一个JavaMainApplication它继承SparkApplication。
如果是Yarn模式,会启动一个org.apache.spark.deploy.yarn.YarnClusterApplication的SparkApplication的进程。
-
步骤2:在YarnClusterApplication这个进程中,会new一个yarnClient的客户端对象。
在这个yarnClient中会new一个YarnClientImpl,它里面有一个属性rmClient,ResourceMangerClient
这样就建立了yarnClient和ResourceManger之间的通信联系。
-
步骤3:yarnClient提交应用程序的时候,会准备容器启动的环境。然后启动一个bin/java org.apache.spark.deploy.yarn.ApplicationMaster的进程。
-
步骤4:容器的环境准备好之后,会new一个ApplicationMaster。
-
步骤5:在ApplicationMaster之内会new一个YarnRMClient它其中有一个属性–amClient: AMRMClient。
AMRMClient用来AM和RM之间相互通信。
-
步骤6:在ApplicationMaster.run时会判断如果是集群模式,会启动一个Driver线程。
Driver线程通过类加载器加载自己写的WordCount类里面的main方法。
-
步骤6.1:这个时候main线程会阻塞 ThreadUtils.awaitResult(),等待获得Driver线程中的sc环境对象。
-
步骤7:获得sc环境对象后,AMRM会向RM申请资源
-
步骤8:RM会分配可用的资源列表给AM。runAllocatedContainers(containersToUse)
遍历可用的容器,每一个容器内都会执行一个ExecutorRunnable
-
步骤9:在每个容器内,会new一个NMClient,用来发送一个commands给NodeManger
集群模式:会启动一个bin/java org.apache.spark.executor.YarnCoarseGrainedExecutorBackend进程
-
步骤10:启动ExecutorBackend进程会创建一个YarnCoarseGrainedExecutorBackend。
-
步骤11:YarnCoarseGrainedExecutorBackend会向Driver进行注册。
-
步骤12:Driver中的SparkContext有一个SchedulerBackend //参数后台通信调度器。在接收到YarnCoarseGrainedExecutorBackend的注册消息后,会发送一个true。
-
步骤13:YarnCoarseGrainedExecutorBackend接收到这个true会给自己发一个消息,然后创建一个Executor对象。
-
步骤14:SparkContext中的DAGScheduler会划分阶段:根据是否有Shuffle将阶段划分为:ShuffleMapStage和ResultStage。
-
步骤15:会根据宽依赖的最后一个RDD的分区数划分Task。
-
步骤16:Task会被封装成TaskSet,通过TaskManger调度TastSet
(TaskManager会被放到FIFO调度器中进行)
-
步骤17:对每个任务根据本地化级别选择将序列化了的Task发送的Executor。
-
步骤18:Executor接收到Task后会解码,放到线程池中,每个线程启动一个Task。
-
步骤19:Executor会执行计算,shuffle等操作。
2 Spark部署模式
Spark支持多种集群管理器:
Standalone:独立部署模式,Spark原生简单集群管理器。
Hadoop Yarn:统一的资源管理机制,根据Driver在集群中的位置不同,分为:
yarn client:Driver在集群外
yarn cluster:Driver在集群内
childMainClass = args.mainClass //也就是WordCount,所在的位置应该是图片中的SparkApplication的位置。所以说Driver就跑到了Yarn集群之外。Apache Mesos模式
K8S模式:容器式部署环境
Windows环境模式
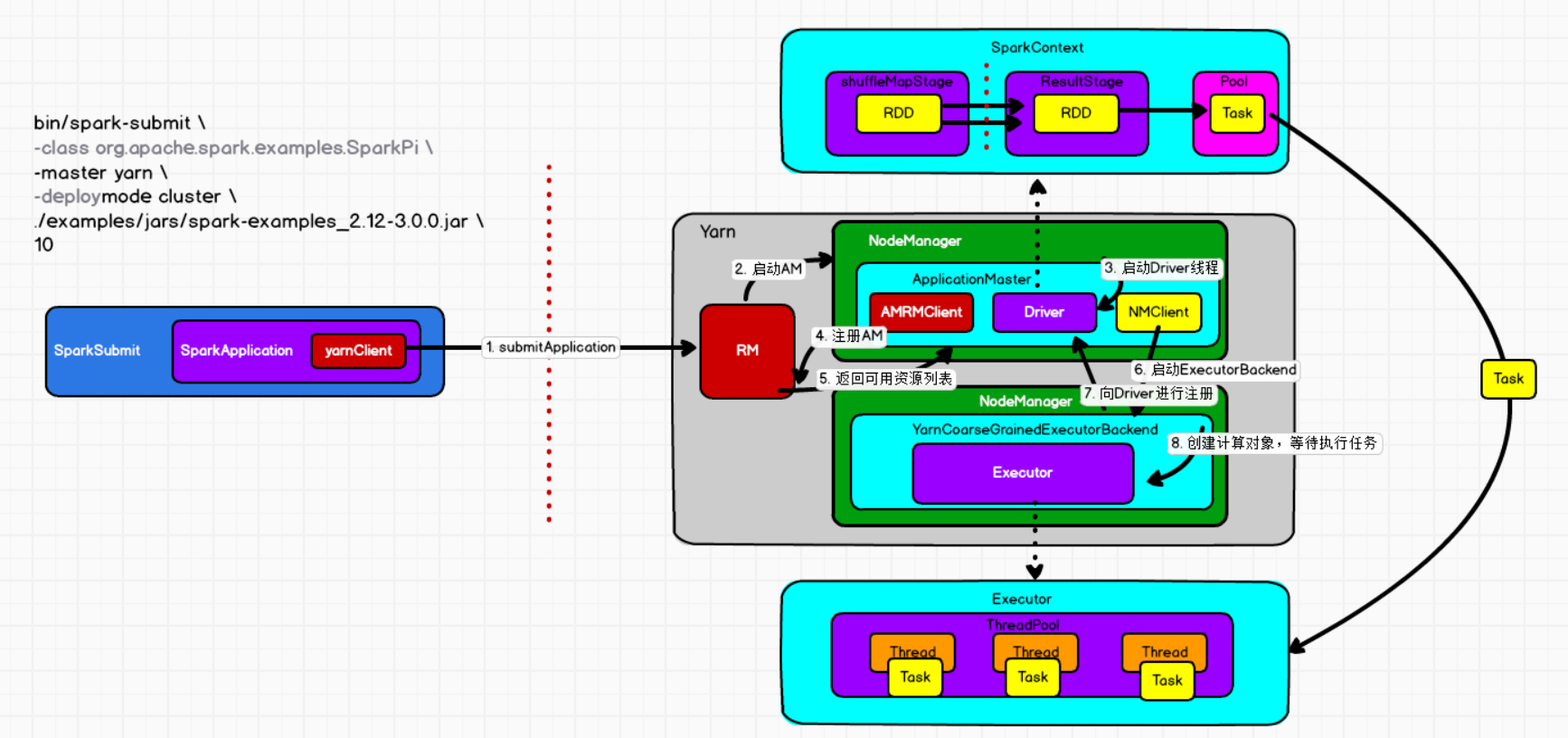
2.1 Yarn cluster模式运行机制
1) 执行脚本提交任务,实际上是启动一个SparkSubmit的JVM进程
2) SparkSubmit类中的main方法反射调用YarnClusterApplication的main方法
3) YarnClusterApplication创建Yarn客户端,然后向Yarn服务器发送执行指令:/bin/java/ApplicationMaster
4) Yarn框架收到指令后会在指定的NM中启动ApplicationMaster
5) ApplicationMaster是一个进程,会启动一个Driver线程,执行用户的作业(WordCount中的main)
6) AM向RM注册,申请资源(AMRMClient)
7) 获取资源后AM向NM发送指令:bin/java YarnCoarseGrainedExecutorBackend
8) CoarseGrainedExecutorBackend进程会接收消息,和Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务
9) Driver线程继续执行完成作业的调度和任务的执行
10) Driver分配任务并监控任务的执行
1) 执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
2) SparkSubmit类中的main方法反射调用YarnClusterApplication的main方法;
3) YarnClusterApplication创建Yarn客户端,然后向Yarn服务器发送执行指令:bin/java ApplicationMaster;
4) Yarn框架收到指令后会在指定的NM中启动ApplicationMaster;
5) ApplicationMaster启动Driver线程,执行用户的作业;
6) AM向RM注册,申请资源;
7) 获取资源后AM向NM发送指令:bin/java YarnCoarseGrainedExecutorBackend;
8) CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务
9) Driver线程继续执行完成作业的调度和任务的执行。
10) Driver分配任务并监控任务的执行。
--注意:SparkSubmit、ApplicationMaster和CoarseGrainedExecutorBackend是独立的进程;Driver是独立的线程;Executor和YarnClusterApplication是对象。
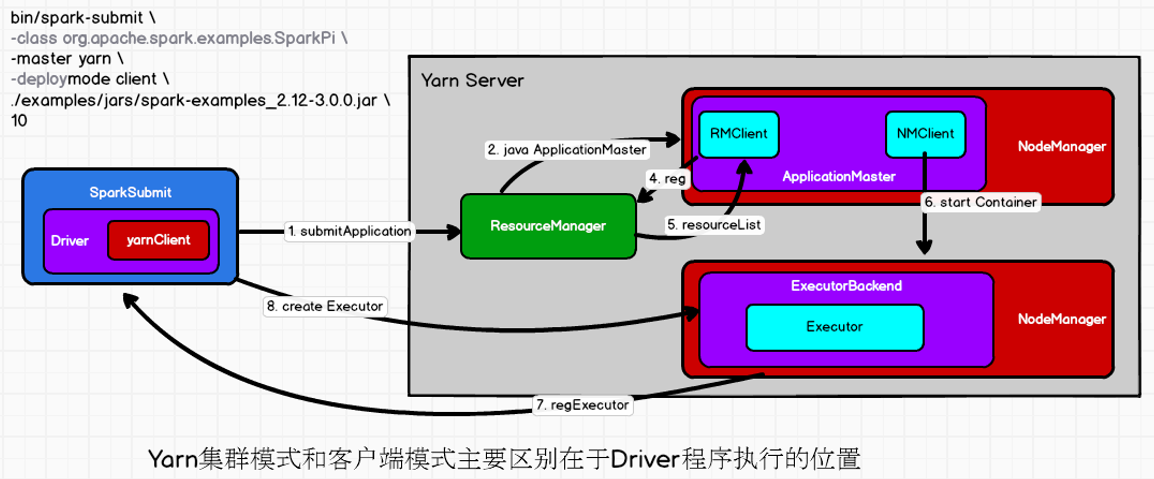
2.2 Yarn Client模式运行机制
1) 执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
2) SparkSubmit类中的main方法反射调用用户代码的main方法;
3) 启动Driver线程,执行用户的作业,并创建ScheduleBackend;
4) YarnClientSchedulerBackend向RM发送指令:bin/java ExecutorLauncher;
5) Yarn框架收到指令后会在指定的NM中启动ExecutorLauncher(实际上还是调用ApplicationMaster的main方法);
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}
6) AM向RM注册,申请资源;
7) 获取资源后AM向NM发送指令:bin/java CoarseGrainedExecutorBackend;
8) CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务
9) Driver分配任务并监控任务的执行。
-- 注意:SparkSubmit、ApplicationMaster和YarnCoarseGrainedExecutorBackend是独立的进程;Executor和Driver是对象。
2.3 Standalone模式运行机制
Standalone集群有两个重要组成部分:
- Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责
- Worker(NM):是一个进程,一个Worker运行在集群中的一太服务器上,主要负责两个责任:1是用自己的内存存储RDD的某个或某些partition;2 是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算
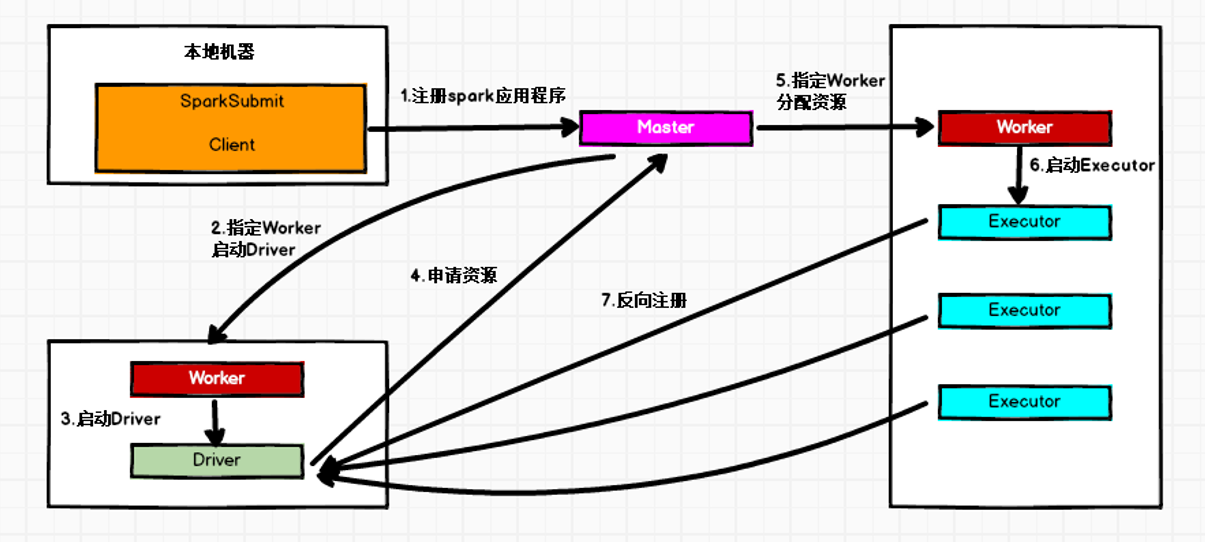
①Standalone Cluster模式
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver。
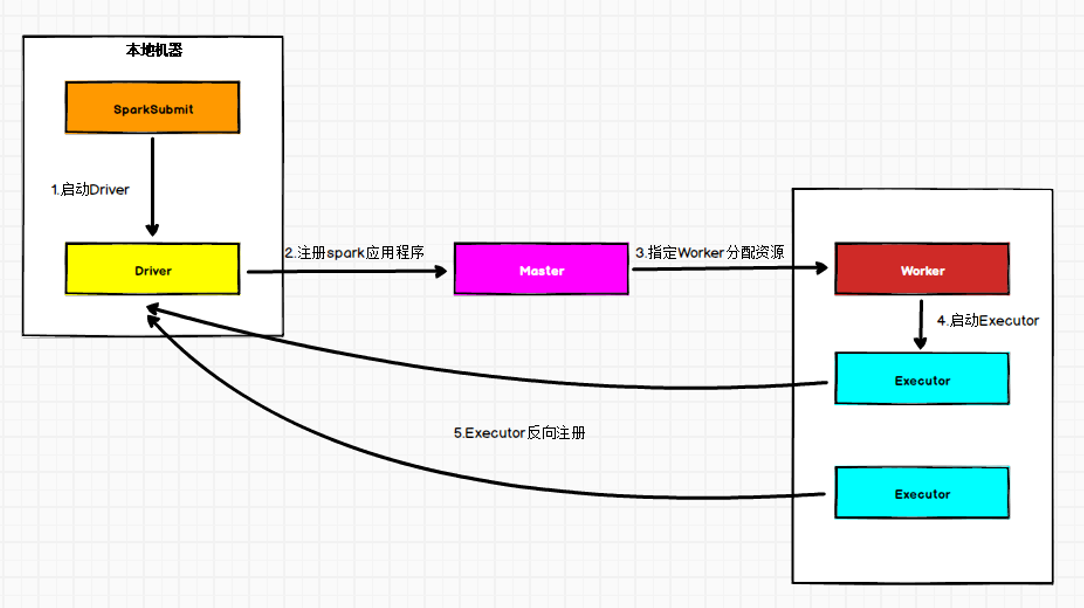
②Standalone Client模式
在Standalone Client模式下,Driver在任务提交的本地机器上运行。
2.4 YarnCluster模式源码分析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U7gzZlwo-1607962819198)(内核代码.assets/image-20201207200855902.png)]
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
①SparkSubmit
SparkSubmit://程序的入口:object SparkSubmit(注意是object伴生对象,因为调用静态的main方法)
--main //(985)
//这个是SparkSubmit伴生对象的doSubmit
--doSubmit //(1016) => 调用main()中doSubmit
--doSubmit //(80)(private[spark] class SparkSubmit,这个是包对象)
--parseArguments(args) //(85)(解析参数)
--new SparkSubmitArguments(args) //(98),参数封装成一个类
--parse(args.asJava) //(108)[类:SparkSubmitArguments]
--case SparkSubmitAction.SUBMIT => submit //(93)
--submit() //(156)循环,直到参数的代理用户不等于null
--doRunMain() //(158)
--runMain(args, uninitLog) //(165)
//★准备提交的环境val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
//org.apache.spark.deploy.yarn.YarnClusterApplication
--prepareSubmitEnvironment(args) //(871)
//★根据字符串 通过反射获取类的对象
--mainClass = Utils.classForName(childMainClass) //(893)
//判断mainclass是否是SparkApplication的子类,如果是就new SparkApplication的对象
--if (classOf[SparkApplication].isAssignableFrom(mainClass)) //(911)
//如果不是,那就new JavaMainApplication extends SparkApplication
--new JavaMainApplication(mainClass) //(914)
//★拿到参数和环境,在SparkApplication内启动程序
--app.start(args, conf) //(41)[类SparkApplication]
//从mainClass中获取静态的main方法
-- mainMethod = mainClass.getMethod("main") //(42)[类SparkApplication]
//获得main方法后,调用WordCount中类的静态main方法
--mainMethod.invoke(null, args) //(52)[类SparkApplication]
submit提交的是什么模式的程序,是根据prepareSubmitEnvironment(args)的返回值中的childMainClass所决定的!
if (args.isStandaloneCluster) {
childMainClass = REST_CLUSTER_SUBMIT_CLASS} //683
//因为yarn又分为cluster集群模式和client客户端模式
if (deployMode == CLIENT) {
childMainClass = args.mainClass} //626
//我们当前的集群为org.apache.spark.deploy.yarn.YarnClusterApplication模式
//YARN_CLUSTER_SUBMIT_CLASS=org.apache.spark.deploy.yarn.YarnClusterApplication
if (isYarnCluster) {
childMainClass = YARN_CLUSTER_SUBMIT_CLASS} //715,模式是cluster模式
if (isMesosCluster) {
childMainClass = REST_CLUSTER_SUBMIT_CLASS} //734
if (isKubernetesCluster) {
childMainClass = KUBERNETES_CLUSTER_SUBMIT_CLASS} //755
②YarnClusterApplication
程序通过Yarn模式向yarn的集群提交程序
app.start启动,然后就向Yarn提交应用程序。这里的app就是org.apache.spark.deploy.yarn.YarnClusterApplication
YarnClusterApplication:是一个包对象,继承SparkApplication,在类Client中。
--start() //1577
//new了一个客户端,里面new了一个客户端参数的对象
--client = new Client(new ClientArguments(args)).run() //1583
--new ClientArguments(args)
--parseArgs(args.toList) //23[类ClientArguments]
--里面就是具体的解析参数,比如--class => userClass,就是WordCount
--new Client() //里面有很多参数,其中:create了一个YarnClient
--yarnClient = YarnClient.createYarnClient //72
--createYarnClient() //74[类YarnClient]
--YarnClient client = new YarnClientImpl() //75[类YarnClient]
//创建YarnClientImpl里面调用父类YarnClient的构造器
//其中有一个属性rmClient,ResourceMangerClient,就建立了yarnClient和RM的关系。关系是yarnClient向RM提交应用程序!
--client.run()
--submitApplication() //1177
--launcherBackend.connect() //170与后台建立连接
--yarnClient.init(hadoopConf) //171根据hadoop的环境初始化yarnClient
--yarnClient.start() //172启动yarnClient,也就是和服务器建立连接
//创建容器启动时的环境参数
//★启动java的一个进程
//【command】: bin/java org.apache.spark.deploy.yarn.ApplicationMaster
--createContainerLaunchContext(newAppResponse) //196
--if (isClusterMode) {
下面一行//980}
--classForName("org.apache.spark.deploy.yarn.ApplicationMaster")
//创建应用程序启动时的环境
--createApplicationSubmissionContext(newApp, containerContext) //197
--yarnClient.submitApplication(appContext) //201提交app(app的环境)
--rmClient.submitApplication(request) //253[类YarnClientlmpl]向RM提交应用
③ApplicationMaster
RM创建容器的环境,然后NM申请一个容器,在容器内启动一个java的进程,也就是上面的ApplicationMaster程序。
bin/java org.apache.spark.deploy.yarn.ApplicationMaster启动了一个java进程,一定会有main()
ApplicationMaster:object ApplicationMaster找到伴生对象中的main()
--main() //840
--new ApplicationMasterArguments(args)//842,把参数封装,然后解析参数
//--class => userClass,还是上面的WordCount
--parseArgs(args.toList) //31[类ApplicationMasterArguments]
--master = new ApplicationMaster() //859,创建了一个applicationMaster对象
--new YarnRMClient() //99
//☆YarnRMClient其中有一个属性:
--amClient: AMRMClient //39[类YarnRMClient],表示AM和RM和连接的客户端
--master.run() //890
--if (isClusterMode) {
runDriver()} //262,如果时集群模式就runDriver-->490
//启动用户的应用程序Driver线程
--userClassThread = startUserApplication() //492
//★Driver是一个线程,Driver线程通过类加载器加载WordCount类里面的main()
--mainMethod = userClassLoader.loadClass(args.userClass).getMethod("main") //718
--new Thread().run( mainMethod.invoke ) //728
--userThread.setName("Driver") //758
--userThread.start() //759
//这里就体现出资源和计算的两条线执行。Driver线程是计算-线,主线程是资源-线
//★等待SparkContext对象的创建,如果SC对象没有创建,那么当前线程会阻塞(主线程)
sc = ThreadUtils.awaitResult() //499
//阻塞线程获得sc环境对象后,其中host是Driver的ip,port是Driver的端口号
--registerAM(host, port, userConf) //507
-amClient.registerApplicationMaster //其实是Driver通过AMRM向RM注册APPlicationMaster ==> 建立关系
//注册的目的是为了申请资源!
--createAllocator() //512,分配资源,返回可用的资源列表。
--allocator.allocateResources() //479,收集资源
//如果可用的容器数量大于0,那么就处理收集的容器
--handleAllocatedContainers() //274[类YarnAllocator]
//运行分配的可用的容器
--runAllocatedContainers(containersToUse) //481[类YarnAllocator]
//遍历所有可用的容器
--for (container <- containersToUse) //532[类YarnAllocator]
//每个容器会对应一个Executor
launcherPool.execute(new ExecutorRunnable).run()
//每个容器也就是AM中会有一个NMClient和其他NM打交道
--nmClient = NMClient.createNMClient()
--startContainer() //启动容器
//启动容器,会准备一个指令,发送给NM
//【command】 => bin/java org.apache.spark.executor.YarnCoarseGrainedExecutorBackend
--commands = prepareCommand()
//启动容器,发送给NM指令
--nmClient.startContainer
所以说WordCount自己写的应用程序就可以称为Driver类,因为自己写的类就运行在Driver的线程中。
也可以把自己写的应用程序,称为Driver程序。所以说算子之外的程序,都是在Driver端执行的!
主线程是用来申请资源,分配资源的。Driver线程内写自己的计算代码。
当阻塞的main线程,获得了Driver线程的SparkContext对象后,会继续执行。会向RM申请资源
RM会收集可用的容器,遍历所有可用的容器,每个容器都会创建一个NMClient,和其他的NM打交道。启动容器会其他的NM发送一个YarnCoarseGrainedExecutorBackend指令。
④YarnCoarseGrainedExecutorBackend
NMClient会建立和其他NodeManger之间的通信,通过YarnCoarseGrainedExecutorBackend这个执行器后台,来和其他的NodeManger通信。
- YarnCoarseGrainedExecutorBackend是一个进程。所以有main方法。
其中RpcEnvEndpoint,是通信环境终端。也就是Executor
- 所有的通信终端都有一个生命周期:constructor -> onStart -> receive* -> onStop
YarnCoarseGrainedExecutorBackend:Executor后台执行器,用来和NodeManager通信
-- main() //72
//run的第二个参数,创建一个Yarn集群Executor通信终端
--new YarnCoarseGrainedExecutorBackend() //75
//onStart在CoarseGrainedExecutorBackend中
--onStart() //82[类CoarseGrainedExecutorBackend]
//★向Driver报告,当前的Executor准备好了
-- drvier.ask( RegisterExecutor )//93[类CoarseGrainedExecutorBackend]
--CoarseGrainedExecutorBackend.run(backendArgs, createFn) //81
//也就是创建了一个环境通信终端的对象
--env.rpcEnv.setupEndpoint("Executor",backendCreateFn(env.rpcEnv, arguments, env, cfg.resourceProfile)) //334[类CoarseGrainedExecutorBackend]
//既然ExecutorBackend向Driver说准备好了Executor,也就是说注册Executor
//那么Driver一定也会有和它通信的方法。Driver的环境准备都是在SparkContext中的。
SparkContext:
--SchedulerBackend //参数后台通信调度器
-- override def receiveAndReply() //205[类CoarseGrainedExecutorBackend]
--case RegisterExecutor //如果收到ExecutorBackend发送的RegisterExecutor
--context.reply(true) //收到后会给ExecutorBackend发送一个true
//Driver会回复一个true,说可以申请成功!那么ExecutorBackend一定会接收到这个消息。
CoarseGrainedExecutorBackend:
--onStart() //82
--case Success(_) => self.send(RegisteredExecutor)//注册成功会自己给自己发一条消息
--receive = {
case RegisteredExecutor}//注册完毕 //147
//★当注册成功才会创建一个Executor计算对象!!!
--executor = new Executor() //151
3 Spark通讯架构
3.1 Spark通讯架构概述
- Spark早起使用Akka架构
- Spark2.x版本以后就使用:Netty通讯架构
(1) 环境
-- Server & Client
(2) 方式(发邮件)
-- Scala:Akka
-- Spark:Netty
(3) 原理:
--BIO:阻塞式IO,性能不高,只能等着完成服务器完成 才能继续执行其他任务
--NIO:非阻塞式IO,性能稍微高一点,一心二用,需要而外花时间轮询的方式查看是否完成
--AIO:异步非阻塞式IO,性能很高,约定好了时间,不需要轮询交互
没有办法在Linux下面,只能使用Windows环境下,Linux为了能够使用异步操作,模拟了一种epoll方式来进行处理
4) 通信组件:
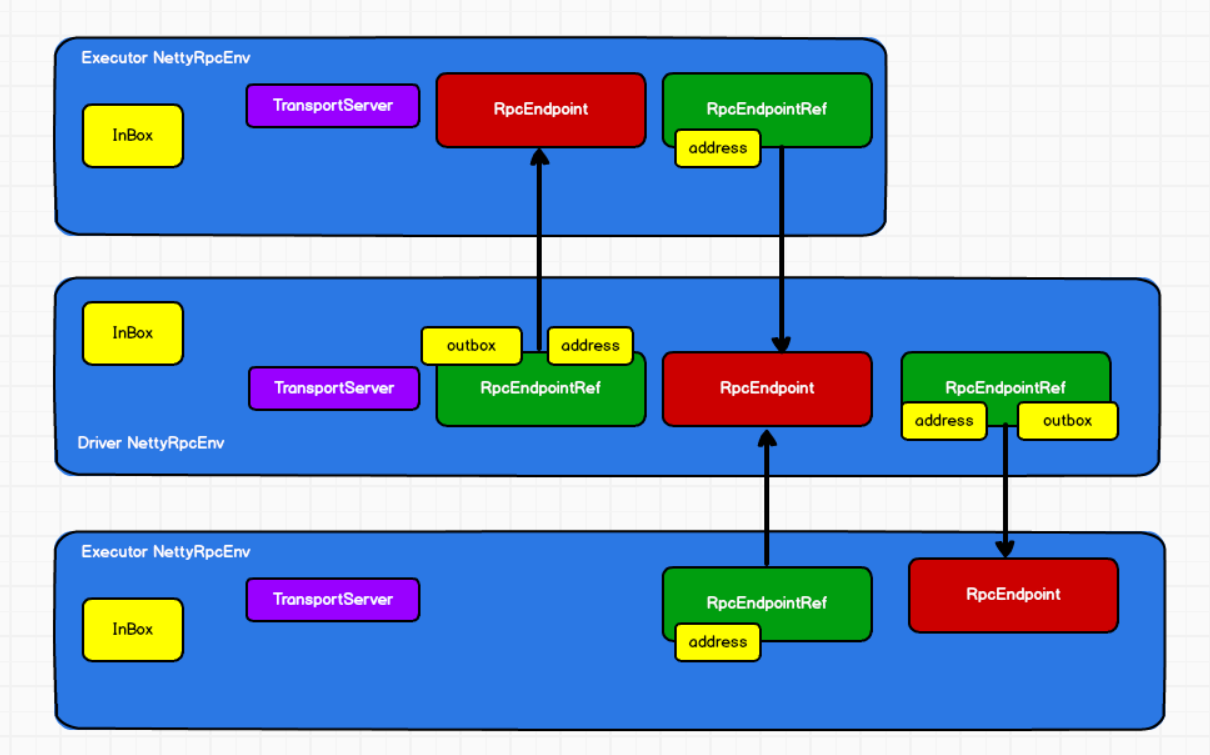
RpcEnv:RPC上下文环境,当前版本使用NettyRpcEnv
RpcEndpoint:RPC通信终端(收消息)
RpcEndpointRef:通信终端的引用(发消息)
InBox:消息收件箱
OutBox:消息发件箱
Dispatcher:消息调度(分发)器
RpcAddress:表示远程的RpcEndpointRef的地址,Host + Port
TransportClient:Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer
TransportServer:Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱
5) 通信终端Endpoint有1个InBox和N个OutBox
6) Driver: class DriverEndpoint extends IsolatedRpcEndpoint
Executor: class CoarseGrainedExecutorBackend extends IsolatedRpcEndpoint
7) 所有的终端都有生命周期:
- Constructor
- onStart
- receive*
- onStop
3.2 源码分析
CoarseGrainedExecutorBackend:
//安装通信终端之间就提前准备好Executor的Env
--val env = SparkEnv.createExecutorEnv()
SparkEnv:
-- env = create()
--val rpcEnv = RpcEnv.create()
RpcEnv:
//创建RpcEnv通信环境
--new NettyRpcEnvFactory().create(config)
--new NettyRpcEnv()
//想当于Server,启动Server,Driver和Executor就可以通信了
--startService = nettyEnv.startServer
--server = transportContext.createServer()
--return new TransportServer
--init()
--getServerChannelClass(ioMode)
//★这里就是NIO和Epoll两种方式!!!
case NIO:
return NioServerSocketChannel.class;
case EPOLL:
return EpollServerSocketChannel.class;
--Utils.startServiceOnPort(startService)
--startService(tryPort)//这个startServer是上一个函数传来的。
//有创建Executor的Env就会有创建Driver的Env
--createDriverEnv()
--create()
//向通信环境中安装一个通信终端
--env.rpcEnv.setupEndpoint("Executor")
--setupEndpoint是一个抽象方法,而实现的就是我们的通信环境:
class NettyRpcEnv()
⑤SparkContext
SparkContext:
--属性:SchedulerBackend:Driver用来和Executor端进行通信的。通信调度器。
TaskScheduler:任务调度器。
DAGScheduler:阶段调度器。
--RDD.collect()
--sc.runJob()
--runJob() //好几次的runJob
--dagScheduler.runJob()
--submitJob()
--eventProcessLoop.post(JobSubmitted)
--eventQueue.put(event) //把event放到队列中
//创建的是一个阻塞队列,链表阻塞式双端队列
--eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
--eventThread = new Thread(name).run()
--eventQueue.take() //从队列中拿数据
--onReceive(event)
//eventProcessLoop = new DAGSchedulerEventProcessLoop(),上面eventProcessLoop post了一个JobSubmitted,它其实继承了 DAGSchedulerEvent。那么就能够收到这个Event
DAGSchedulerEventProcessLoop
--onReceive(event: DAGSchedulerEvent)
--doOnReceive(event)
//如果接收到了这个JobSubmitted
--case JobSubmitted()
//那么就处理
--dagScheduler.handleJobSubmitted()
//阶段的划分
--finalStage = createResultStage()
//提交阶段
--submitStage(finalStage)
--submitMissingTasks()
//ShuffleMapStage ==> ShuffleMapTask --> write
//shuffleWriterProcessor.write写数据
--case stage: ShuffleMapStage
//封装task,根据分区数去计算task个数
--partitionsToCompute.map
--new ShuffleMapTask()
//ResultStage ==> ResultTask --> read
//这里的rdd是当前阶段的最后一个RDD,这个RDD一定是ShuffledRDD,所以一定有SparkEnv.get.shuffleManager.getReader(read()),来读取数据。
//rdd.iterator(partition, context)
--case stage: ResultStage
--partitionsToCompute.map
--new ResultTask()
--if (tasks.nonEmpty) {
taskScheduler.submitTasks}
--schedulableBuilder.addTaskSetManager
//有两种调度器:
//①先进先出调度器FIFOSchedulableBuilder //默认
//②公平调度器FairSchedulableBuilder
//把任务放到任务池中!
--rootPool.addSchedulable(manager)
//从任务池中把任务取出来
--backend.reviveOffers()
//driver的通信终端发送一个ReviveOffers消息
--driverEndpoint.send(ReviveOffers)
//CoarseGrainedSchedulerBackend会收到这个消息
--receive()
--case ReviveOffers =>makeOffers()
//从池子中取出任务
--val taskDescs = withLock{
}
//如果取出的任务不为空,那么就启动任务
--if(taskDescs.nonEmpty){
launchTasks(taskDescs)}
//因为把task封装到集合中,扁平化拿到每个task
--for (task <- tasks.flatten) {
//将每个task编码:序列化
--serializedTask = TaskDescription.encode(task)}
//Driver端的执行器终端,发送消息的同时,将我们序列化好的task也一起发过去了。
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))
//因为Driver端发送了一个task,所以CoarseGrainedExecutorBackend会收到这个task和消息
CoarseGrainedExecutorBackend:
--receive()
--case LaunchTask(data)
//解码:反序列化Task
--val taskDesc = TaskDescription.decode(data.value)
//Executor计算器就会启动这个task
--executor.launchTask()
//Executor启动Task
Executor
--val tr = new TaskRunner(context, taskDescription)
--run()
--task.run()
--runTask(context) //执行Task
--runningTasks.put(taskDescription.taskId, tr)
//线程池执行一个TaskRunner,就会启动一个线程执行一个Task
--threadPool.execute(tr)
4 Spark任务调度机制
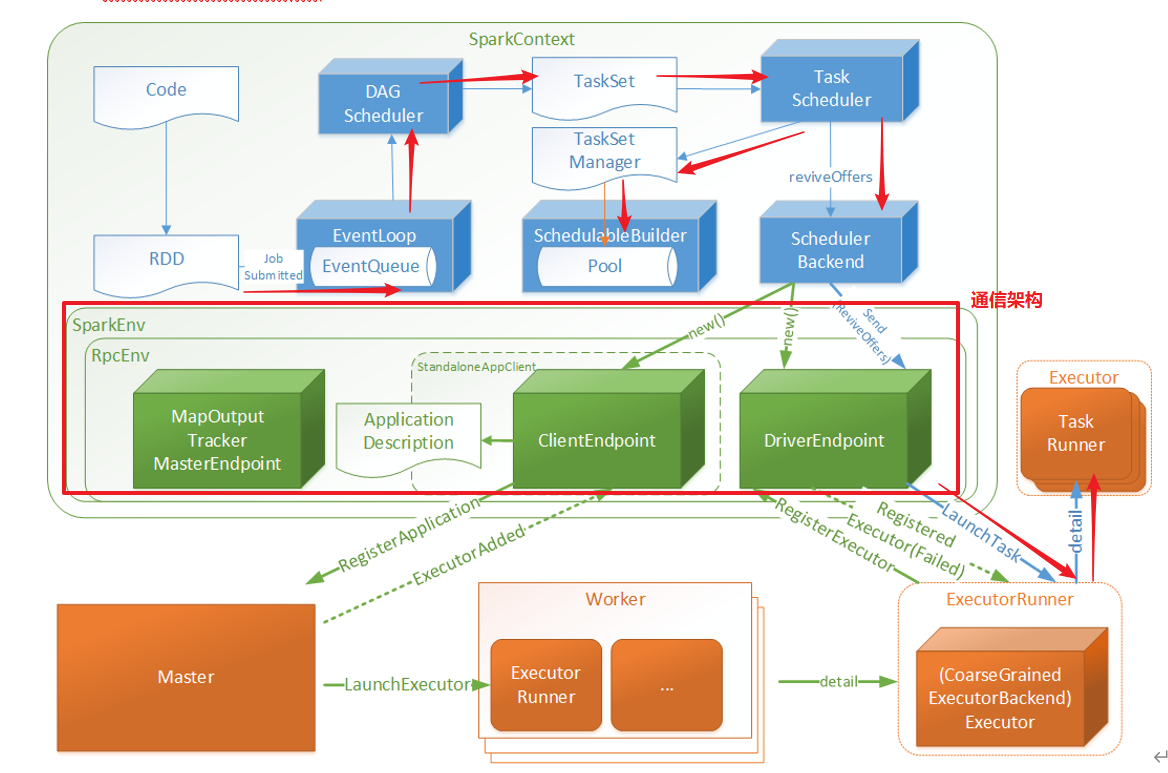
1)
-- Job:是以Action算子为界,遇到一个Action算子触发一个Job
-- Stage:是以RDD宽依赖为界,遇到一个shuffle划分一个阶段,是根据DAG划分的
-- Task:是一个Stage阶段的最后一个RDD的分区数量
2)
--执行过程中会有两个调度器DAGScheduler和TaskScheduler
DAGScheduler负责Stage的调度,负责将Job切分成若干个Stages,并将Stage打包TaskSet交给TaskScheduler
TaskScheduler负责Task的调度,将DAGScheduler发过来的TaskSet按照指定的调度策略分到Executor执行。
3)
--TaskScheduler支持两种调度策略:
FIFO,先进先出策略,(默认):直接简单地将TaskSetManager按照先来先到的方式入队,出队时直接拿出最先进队的TaskSetManager
FAIR,公平调度策略
4)
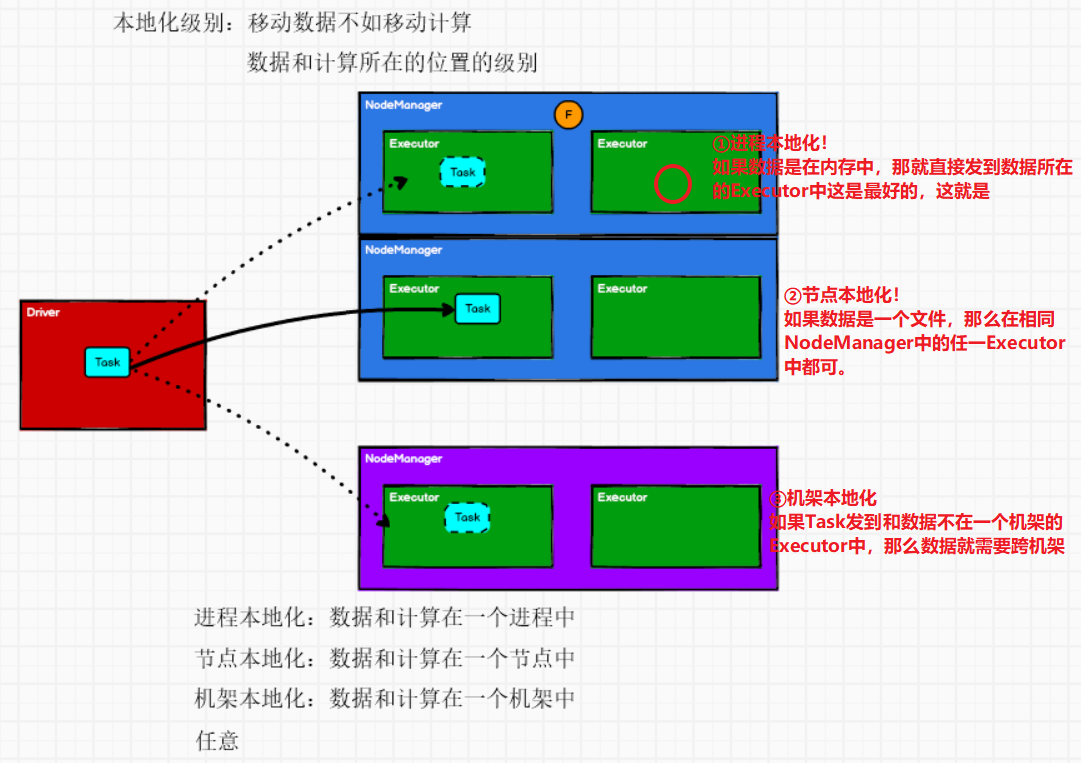
--本地化级别调度
PROCESS_LOCAL 进程本地化,task和数据在同一个Executor中,性能最好。
NODE_LOCAL 节点本地化,task和数据在同一个节点中,但是task和数据不在同一个Executor中,数据需要在进程间进行传输。
RACK_LOCAL 机架本地化,task和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。
NO_PREF 对于task来说,从哪里获取都一样,没有好坏之分。
ANY task和数据可以在集群的任何地方,而且不在一个机架中,性能最差。
5)
--失败重试与黑名单机制
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态,对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
在记录Task失败次数过程中,会记录它上一次失败所在的Executor Id和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的Executor Id和Host,以及其对应的“拉黑”时间,“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
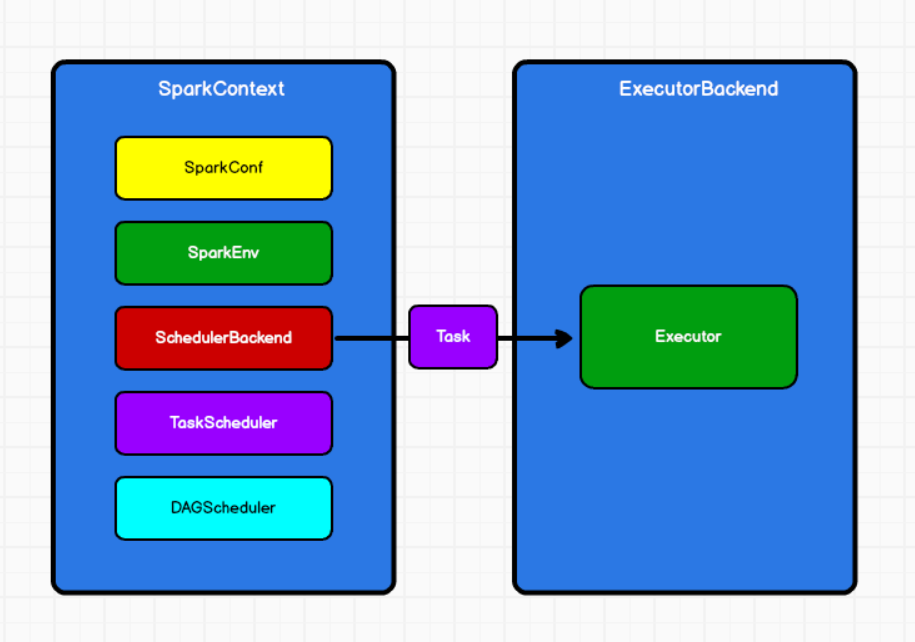
4.1 阶段的划分源码
- 分类:ResultStage & ShuffleMapStage
- 数量:1(ResultStage) + N(Shuffle依赖的数量)
任务提交过程源码:
--RDD.collect()
-- 一连串的runJob()
//到达SparkContext:
//DAG调度器,运行job
--dagScheduler.runJob(rdd)
--submitJob(rdd)
//事件进程循环的一个对象,放一个JobSubmitted的事件进去。
--eventProcessLoop.post(JobSubmitted(rdd))
//创建了一个链表的阻塞式双端队列,往里面放事件。
--eventQueue.put(event) //new LinkedBlockingDeque[E]()
//还会启动一个事件的线程
--enentThread.run()
//线程运行的过程中会接收消息
--onReceive(event)
//onReceive()是一个抽象方法,==>DAGSchedulerEventProcessLoop
--doOnReceive(event)
//DAG的事件进程循环调度器接收到这个消息之后,会模式匹配发现传进来的是JobSubmitted这样的一个消息
--case JobSubmitted()
--dagScheduler.handleJobSubmitted() //★专门的阶段的划分
//★创建Result阶段(如果没有shuffle,就只有这一个阶段)
--finalStage = createResultStage()
//获取或创建上一级的阶段
--val parents = getOrCreateParentStages
//返回作为给定RDD的直接父级的shuffle依赖项
--getShuffleDependencies(rdd)//★重点!!
//如果有shuffle依赖,那就创建shuffleMapStage
--getOrCreateShuffleMapStage()
//如果有shuffle那就会有上一级阶段。是一种包含关系~
//也就是说不管怎样都会有一个ResultStage
--val stage = new ResultStage(parents)
//根据依赖关系,向上找parent当有一个shuffle依赖就会多产生一个阶段,也就是产生一个ShuffleMapStage
//getShuffleDependencies(rdd)
// toVisit.dependencies.foreach{
// 如果是shuffle依赖就向parents的haasSet中放,返回parent
// case shuffleDep =>parents += shuffleDep
// case dependency =>waitingForVisit.prepend(dependency.rdd)
//getOrCreateShuffleMapStage
// case Some(stage) => stage
// case None => createShuffleMapStage(shuffleDep, firstJobId)
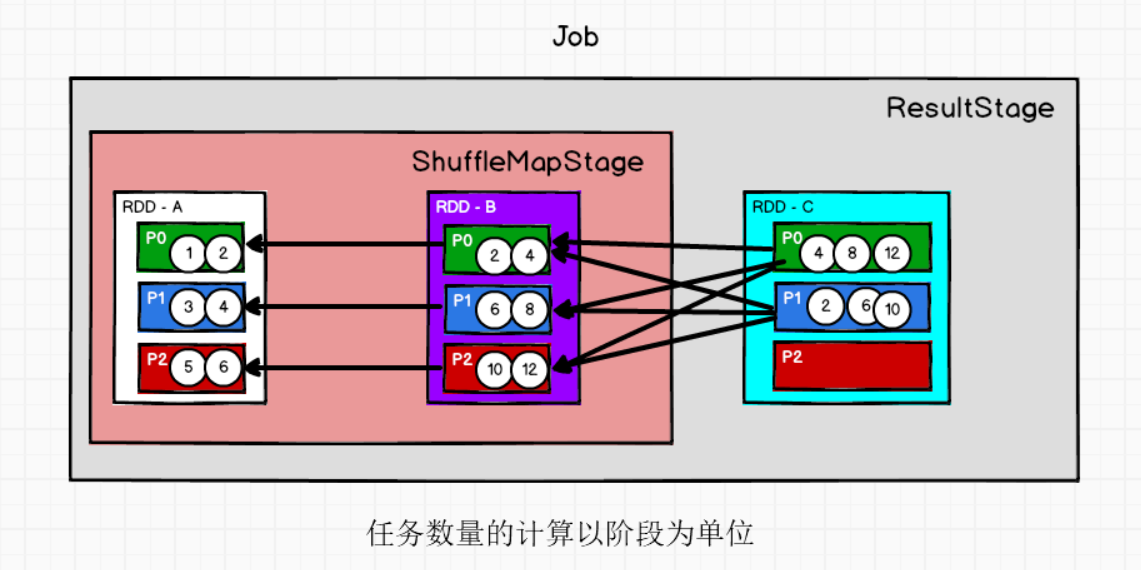
4.2 任务的切分源码
ShuffleMapTask和ResultTask
- 任务切分原理:通过分区进行任务的计算
- 数量:所有的阶段最后一个RDD的分区数量总和
//DAG调度器接收到JobSubmitted这个消息后会处理提交的消息。
handleJobSubmitted()
//提交阶段的时候会把最后一个阶段传进去了,也就是说把ResultStage传进去了
--submitStage(finalStage)
//获取没有上一级的那个阶段,根据当前阶段的id排序。也就是stage0,stage1排序。
--val missing = getMissingParentStages(stage).sortBy(_.id)
-- for (dep <- rdd.dependencies) {
dep match {
//如果是一个宽依赖就创建一个ShuffleMapStage
case shufDep: ShuffleDependency =>
getOrCreateShuffleMapStage
missing += mapStage
case narrowDep: NarrowDependency =>
waitingForVisit.prepend}}
//提交阶段
--submitMissingTasks(stage)
// 任务来自阶段!!!
-- val tasks: Seq[Task[_]] = try{
stage match {
//如果是shuffleMapStage
case stage: ShuffleMapStage =>
partitionsToCompute //计算当前阶段最后一个RDD的分区的数量,得到一个分区的索引编号,如0 1 2
new ShuffleMapTask(stage.id)
//如果是ResultStage
case stage: ResultStage =>
partitionsToCompute
new ResultTask(stage.id)
4.3 任务的调度源码
生产环境下,Spark集群的部署方式一般为Yarn-Cluster模式。Spark Cluster模式下任务提交流程,其中还有一部分是Driver的工作流程。
- Driver线程主要是初始化SparkContext对象,准备运行所需的上下文
- 然后一方面保持与ApplicationMaster的RPC连接,通过Application申请资源
- 另一方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲的Executor上
- 当ResourceManger向Application返回可用的Container资源时,ApplicationMaster就会尝试在对应的Container上启动Executor进程,Executor进程起来后,会向Driver反向注册,注册成功后会保持与Driver的心跳,同时等待Driver分发任务,当分发的任务执行完毕后,将任务状态上报给Driver。
new ShuffleMapTask(stage.id, stage,taskBinary, part, ... )
-- var taskBinary: Broadcast[Array[Byte]] = null
--taskBinary = sc.broadcast(taskBinaryBytes)
--closureSerializer.serialize //闭包的序列化器,闭包用广播变量的方式传给Executor
//任务调度:
submitMissingTasks()
//如果任务不为空
--if (tasks.nonEmpty) {
//★任务调度器会提交一个Task,首先会把Task封装成TaskSet任务集。
taskScheduler.submitTasks(new TaskSet)}
//这个方法是一个抽象的,然后找到TaskSchedulerlmpl中的实现方法:
--submitTasks(taskSet: TaskSet)
//★构建了一个任务集管理器:TaskSetManager用来调度TaskSet用的!
--manager = createTaskSetManager(taskSet)
//★把TaskSeManager放到任务调度器中去
--schedulableBuilder.addTaskSetManager(manager)
//这里的调度器:可以看到有两个:
//FIFOSchedulableBuilder:先进先出调度器(默认)
//FairSchedulableBuilder:公平调度器
//★进入到FIFO的调度器中:把TaskManger放到了任务池中去
//TaskPool:rootPool
--rootPool.addSchedulable(manager)
//上面一步把TaskManger都放到了任务池中,然后就应该是从池子中取出任务
--backend.reviveOffers()
//找到CoarseGrainedSchedulerBackend中的
--reviveOffers => makeOffers()
//★取出任务,具体实现取出在resourceOffers内。
--scheduler.resourceOffers(workOffers)
//根据首选位置发送Task,如果位置相同的话会轮询的发,如果挂掉的话就会拉入到黑名单里面,下一次就不会再找它了
--blacklistTrackerOpt.foreach(_.applyBlacklistTimeout())
//根据FIFO调度算法取得TaskSet
--sortedTaskSets = rootPool.getSortedTaskSetQueue
//会根据调度模式,也就是FAIR或者FIFO选择调度算法
--schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
//取得TsekSet任务集之后
--for (taskSet <- sortedTaskSets) {
//★对每个任务根据本地化级别选择Task发送的Executor
//有PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY这五个级别
//还有一个等待时间的概念localityWaits,默认是3秒
for (currentMaxLocality <- taskSet.myLocalityLevels)
}
return tasks//返回Task
//★启动任务的调度
--launchTasks(taskDescs)
--for (task <- tasks.flatten) {
//对获取的任务数据进行编码(序列化)
val serializedTask = TaskDescription.encode(task)
//发送了一个LaunchTask的消息,同时把序列化了的Task传给了Executor
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
//Driver发送了一个LaunchTask的消息给Executor,所以ExecutorBackend一定能够recieve到这个消息
CoarseGrainedExecutorBackend:
--receive()
//这里拿到的data就是serializedTask
case LaunchTask(data)
//远程的Executor将任务数据进行解码(反序列化)
val taskDesc = TaskDescription.decode(data.value)
//解码之后,就通过计算对象Executor启动任务
executor.launchTask(this, taskDesc)
4.4 任务的执行源码
任务Task从Driver发送给Executor端之后,就会通过Executor进行计算了。
//Executor解码序列化的Task数据后,就通过Executor进行计算
--executor.launchTask(this, taskDesc)
//首先将Task包装起来
-- val tr = new TaskRunner(context, taskDescription)
//★线程池执行Task
--threadPool.execute(tr)
-- run()
//调用任务的run方法
-- task.run()
//通过模板方法设计模式调用具体子类的实现逻辑
//这里的子类是ResultTask里面的runTask()
--runTask(context)
5 Spark Shuffle解析
shuffle一定会落盘!但是溢写有可能落盘有可能不落盘!!不要搞混了!!
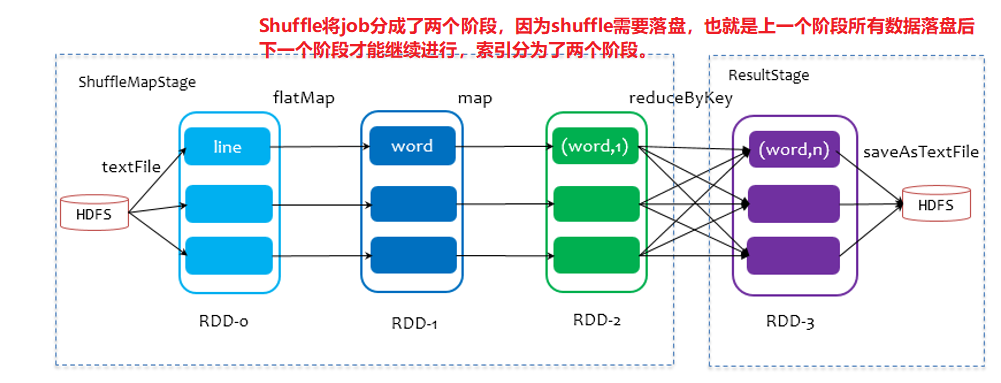
Shuffle会落盘,提升Shuffle的性能会极大的提升Spark的性能
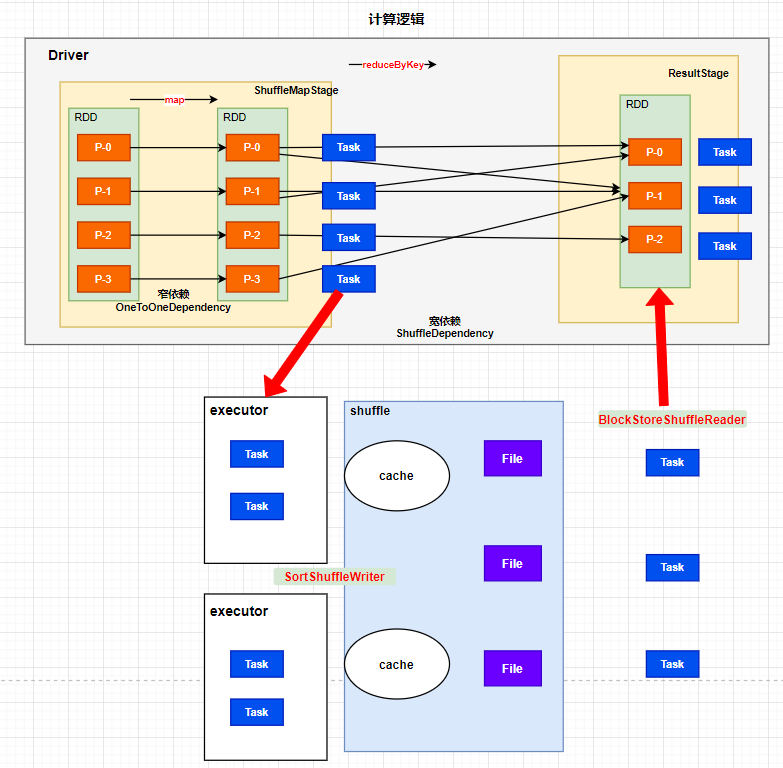
在划分stage时,最后一个stage称为finalStage,它本质上是一个ResultStage对象,前面的所有的stage称为ShuffleMapStage
- ShuffleMapStage的结束伴随着shuffle文件的写磁盘;即能读数据,又能写数据
- ResultStage基本上对应代码中的action算子,即将一个函数应用在RDD的各个partition的数据集上,意味着一个job的运行结束;只能读数据
5.1 HashShuffle和SortShuffle
我们的Spark采用的就是SortShuffle
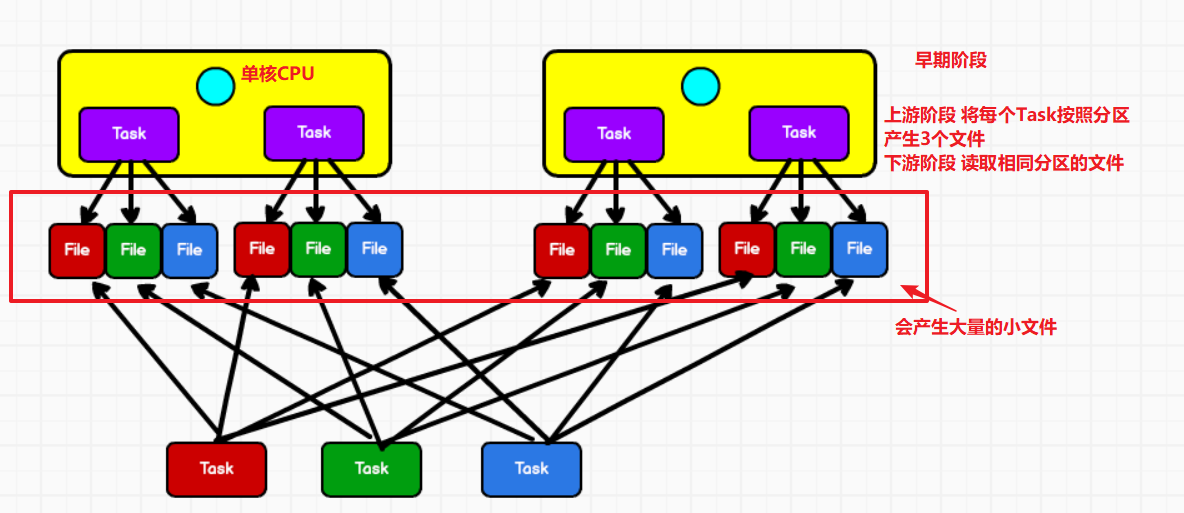
①未优化的HashShuffle
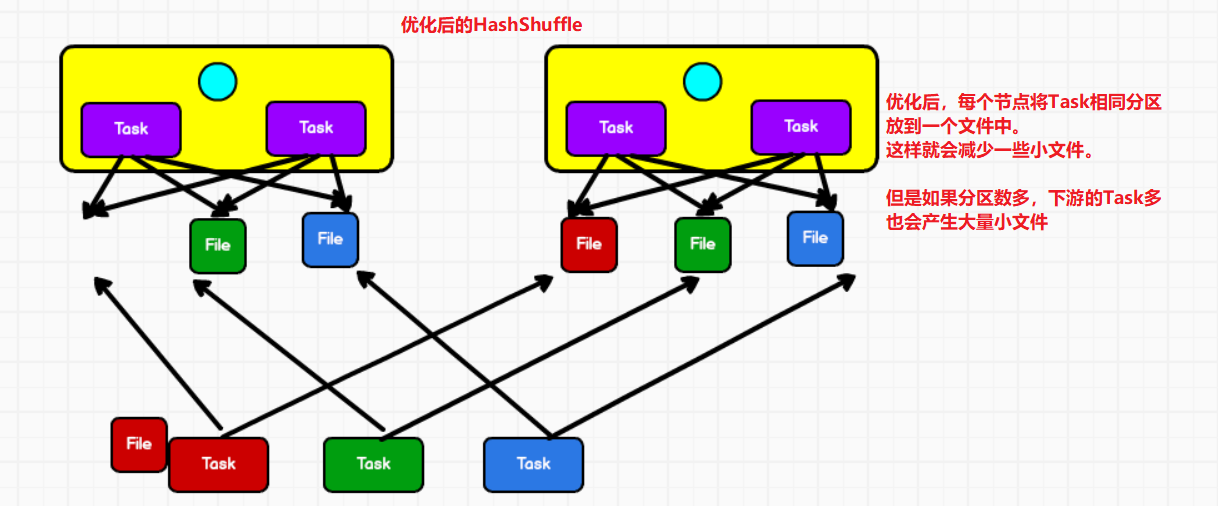
②优化后的HashShuffle
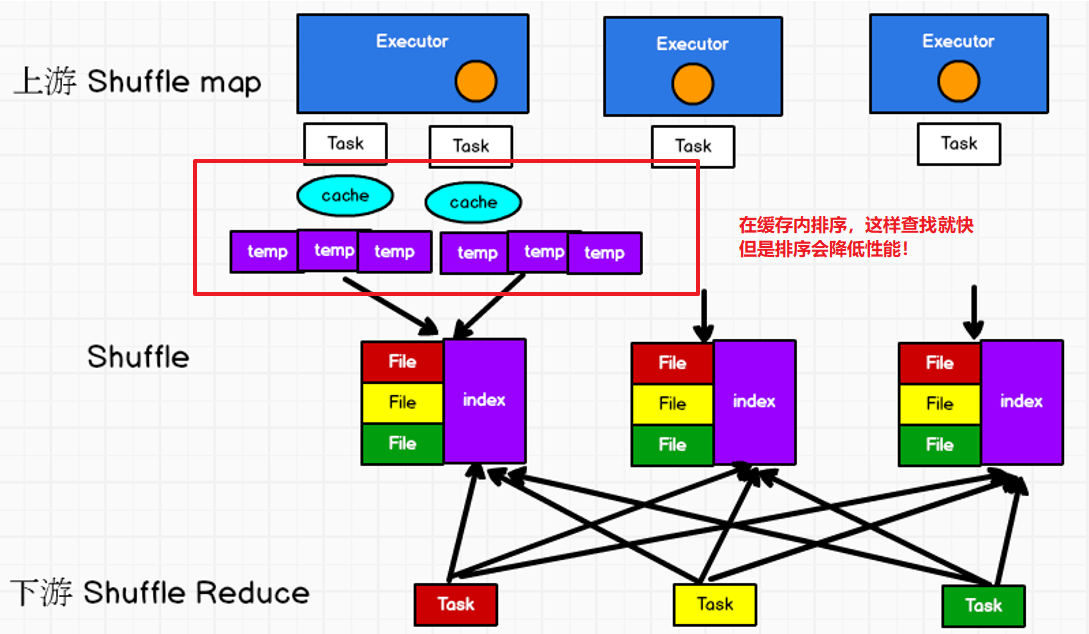
③普通SortShuffle
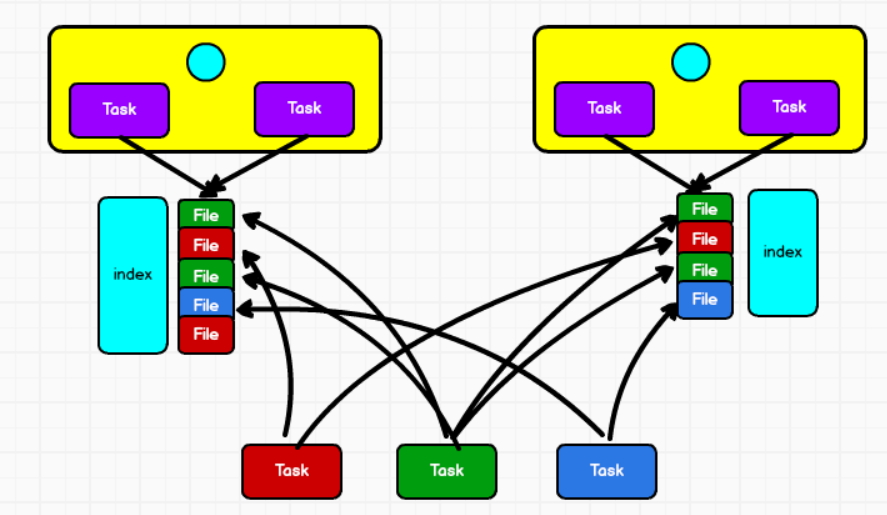
④bypass SortShuffle
和普通的SortShuffle的区别是 不在缓存内排序。
不排序那么怎么快速的定位数据呢?
将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件
5.2 Shuffle阶段的划分源码
Spark的ShuffleDependency(也就是Shuffle)将阶段切分。
默认一定会有一个finalStage : ResultStage,提交阶段submitStage的时候会获取getMissingParentStages,也就是根据宽依赖还是窄依赖判断是否有上一级的ShuffleMapStage。
DAGScheduler:
--handleJobSubmitted //处理JobSumbitted
--finalStage = createResultStage() //创建ResultStage
--submitStage(finalStage) //提交Stage,这里面会判断是否有宽依赖和窄依赖
//★获取漏掉的ParentStage,也就是判断是否有Shuffle判断是否有其他的阶段
--getMissingParentStages(stage).sortBy(_.id)
//遍历所有的依赖
--for (dep <- rdd.dependencies)
//如果是宽依赖,也就是ShuffleDependency
case shufDep: ShuffleDependency
//那就创建一个ShuffleMapStage
mapStage = getOrCreateShuffleMapStage
case narrowDep: NarrowDependency
--submitMissingTasks() //得到了所有的ParentStage也就是ShuffleStage,提交
5.3 Shuffle的读写磁盘源码分析
shuffle将job分为了ShuffleMapStage,ResultStage;
ShuffleMapStage内new了ShuffleMapTask,runTask的时候shuffle一定会落盘,那么一定会有写操作,如果前面还有stage那么也会有读操作。
ResultStage内new了ResultTask,runTask的时候一定会读磁盘,那么一定会有读操作。
--写的Writer有3种:
1. UnsafeShuffleWriter
2. BypassMergeSortShuffleWriter
3. SortShuffleWriter(我们用的是这一个!)
--读的reader只有1种
1. BlockStoreShuffleReader
--写数据的缓冲区是32K
--读数据的缓冲区是48M
ShuffleMapTask的读写磁盘分析:
--runTask()
--dep.shuffleWriterProcessor.write
--var writer: ShuffleWriter
--writer.write(rdd.iterator(partition, context) ...)
//这里的writer会根据ShuffleHandle,shuffle的处理方式分为3中writer
//如何选择writer呢?看下面的shuffle的管理
//ShuffleMapTask的读磁盘在哪呢?
//RDD不保存数据,是通过iterator迭代器的方式去读取数据的
-- writer.write(
rdd.iterator(partition, context))
--computeOrReadCheckpoint()
//在这个时候找到ShuffledRDD的compute方法
--compute()
//这里就是ResultTask的RDD的读操作了
--SparkEnv.get.shuffleManager.getReader().read()

ResultTask:的读磁盘分析:
//ResultTask的都磁盘的也是通过RDD的iterator迭代器的方式读取数据
--func(context, rdd.iterator(partition, context))
--computeOrReadCheckpoint
//在这个时候找到ShuffledRDD的compute方法
--compute()
//这里就是ResultTask的RDD的读操作了
--SparkEnv.get.shuffleManager.getReader().read()
5.4 Shuffle的管理
- SortShuffleManager
- HashShuffleManager(已删除)
ShuffleMapTask://任务分为ResultTask和ShuffleMapTask
--runTask()
--dep.shuffleWriterProcessor.write //ShuffleMapTask运行Task一定会写操作
//★这里的会获得shuffleManager,Shuffle的管理器现在只有SortShuffleManager
--manager = SparkEnv.get.shuffleManager
//写磁盘一定会write
--writer = manager.getWriter
//getWriter是抽象的,找到==>SortShuffleManager
//★handle在这里
--dep.shuffleHandle
//环境的shuffleManager会注册Shuffle
env.shuffleManager.registerShuffle
//★注册shuffle是抽象的找到 ==> SortShuffleManager
--registerShuffle
/*
如果满足shouldBypassMergeSort就new一个忽略合并排序的shufflehandle
那么是什么条件?
如果支持map端聚合,也就是预聚合那么就不满足。
if (dep.mapSideCombine) false
如果不支持那么就从环境中拿到下面这个参数。忽略merge排序的一个阈值
spark.shuffle.sort.bypassMergeThreshold
默认为200
如果分区数量 <= 200就可以忽略了
else {
conf.get(config.SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD)
dep.partitioner.numPartitions <= bypassMergeThreshold}
*/
--if (SortShuffleWriter.shouldBypassMergeSort)
new BypassMergeSortShuffleHandle
/*
如果能够使用序列化那么就new一个序列化的ShuffleHandle
那么什么是能够使用序列化呢?
如果不支持序列化的重定位操作,那么就不满足。
if (!dependency.serializer.supportsRelocationOfSerializedObjects) false
//如果支持mapSide预聚合那么也不满足
else if (dependency.mapSideCombine) false
//如果分区数大于16777215 那么也不满足
else if (numPartitions > 16777215) false
//上面都是false才满足
else {true}
*/
--else if (SortShuffleManager.canUseSerializedShuffle)
new SerializedShuffleHandle
//前面两个条件都不满足的情况下才会走这个,new一个BaseShuffleHandle
--else {
new BaseShuffleHandle}
SortShuffleManager:
//handle这里上面传来的~
--handle: ShuffleHandle
//★会根据handle匹配三种Writer,那么handle哪来的呢?
-- handle match {
case unsafeShuffleHandle: SerializedShuffleHandle
new UnsafeShuffleWriter
case bypassMergeSortHandle: BypassMergeSortShuffleHandle
new BypassMergeSortShuffleWriter
case other: BaseShuffleHandle
new SortShuffleWriter}
5.5 分区内排序 & 预聚合
-- 有预聚合功能的算子:
1. reduceByKey
2. aggregateByKey
3. foldByKey
4. combineByKey
重要的Writer : SortShuffleWriter
SortShuffleWriter:中一定会有write方法:
SortShuffleWriter
--write
//★排序,如果支持预聚合
--sorter = if (dep.mapSideCombine)
//分区内的聚合,排序
new ExternalSorter(dep.aggregator, dep.keyOrdering)
else {
new ExternalSorter(aggregator = None,ordering = None)}
//★聚合,把数据插入进行聚合
--sorter.insertAll(records)
--val shouldCombine = aggregator.isDefined //判断是否定义聚合器
--if (shouldCombine) {
//如果有预聚合操作
//map = new PartitionedAppendOnlyMap[K, C],这里的map和buffle并不是真正的map,这里的kv其实是顺序存储的。那么是怎么存储的呢?
//data(2 * pos) = k
//data(2 * pos + 1) = v
//分区排序是先以分区排序,再以key排序
map
//★怎么预聚合的呢?就是将分区内相同key的两个v合并
update = mergeValue(oldValue, kv._2)
//有可能溢写磁盘,那么什么时候会溢写磁盘呢?
//★“spark.shuffle.spill.initialMemoryThreshold” = 5M
//如果可申请的内存 + 5M 还不够那么就溢写磁盘
//★"spark.shuffle.spill.numElementsForceSpillThreshold"=Integer.MAX_VALUE
//如果
maybeSpillCollection(usingMap = true)
//真正的溢写磁盘操作
--spill(collection)
}else {
//如果没有预聚合操作
//buffer = new PartitionedPairBuffer[K, C]
buffer
//有可能溢写磁盘
maybeSpillCollection(usingMap = true)
}
//排完序之后会写文件
--sorter.writePartitionedMapOutput()
//如果溢写文件为空,in-memory data,在内存中,不用溢写
--if (spills.isEmpty)
//merge-sort,溢写的时候归并,溢写的时候生成数据文件和索引文件
--else
1. 写文件的过程:写磁盘文件时,首先将数据写入到内存中,并在内存中进行排序,如果内存不足(5M),会溢写磁盘
5.6 归并排序
Spark归并排序算法用的是堆排序算法,大顶堆排序。
Hadoop的归并排序算法是快排。
SortShuffleWriter:
--write
//分区内排序 & 预聚合之后,写文件
--sorter.writePartitionedMapOutput()
//spills = new ArrayBuffer[SpilledFile]
//★如果没有溢写,那if就在内存中操作
--if (spills.isEmpty) {
partitionPairsWriter = new ShufflePartitionPairsWriter(partitionWriter)
partitionPairsWriter.write(elem._1, elem._2)
}else{
//else就在内存和临时的磁盘文件
for ((id, elements) <- this.partitionedIterator)
//★partitionedIterator内会判断溢写文件spills是否为空,如果不为空就归并
--merge(spills)
//★归并排序的算法
--mergeSort(iterators)
//spark的归并排序用的是优先级队列
//默认的优先级队列,会把放入数据的最小数据取出
//Spark使用的是大顶堆排序!!!
// Use the reverse order (compare(y,x)) because PriorityQueue dequeues the max
--val heap = new mutable.PriorityQueue[Iter]()
}
//把所有的分区文件提交到Driver。为什么要提交到Driver呢?
//因为当前的Task写了一个文件,下一个task不知道去哪里取。需要把文件路径传到Driver中保存起来
--mapOutputWriter.commitAllPartitions()
--【LocalDiskShuffleMapOutputWriter】
--writeIndexFileAndCommit
--indexFile = getIndexFile
--dataFile = getDataFile
6 Spark内存管理
6.1 堆内和堆外内存规划
1) "堆内内存"
是指JVM所能够使用的内存,并不是完全可以控制,如GC垃圾回收器的执行时间是不可控的,当你需要内存进行数据处理的时候,GC并不能立即释放内存给你使用。
JVM虚拟机默认使用的内存大小是可用内存的1/64,最大值是1/4
1.1) "设置堆内内存的参数"
①由Spark应用程序启动时,–executor-memory
②spark.executor.memory 参数配置
2) "堆外内存"
在JVM虚拟机之外的内存,可以存储我们的数据,这个内存是咱们向操作系统申请过来的,完全可控。
"默认是不启用堆外内存"
2.1) "设置堆外内存的参数"
①启动堆外内存的参数:spark.memory.offHeap.enabled
②设置堆外内存的大小:spark.memory.offHeap.size
3) "Spark中堆内和堆外内存可以进行统一的管理"
6.2 早期内存管理
①早期内存管理
Spark最初采用的静态内存管理机制,存储内存、执行内存、和其他内存的大小在Spark应用程序运行期间是固定的。
1) 内存空间的分配
1. Storeage:缓存RDD数据和广播变量的数据,"内存大小占比60%"
2. Executor:用于缓存shuffle过程的中间数据,"内存大小占比20%"
3. Other:用户自定义的一些数据结构或者是Spark内部的元数据,"内存大小占比20%"
2) Storeage内存和Executor内存都有预留空间,目的是方式OOM,因为Spark堆内存大小的记录是不准确的,需要留出保险区域。
3) 当前不同区域内存大小分配存在的问题:
Executor的内存太小,而Sroreage内存太大
堆内内存:

堆外内存:
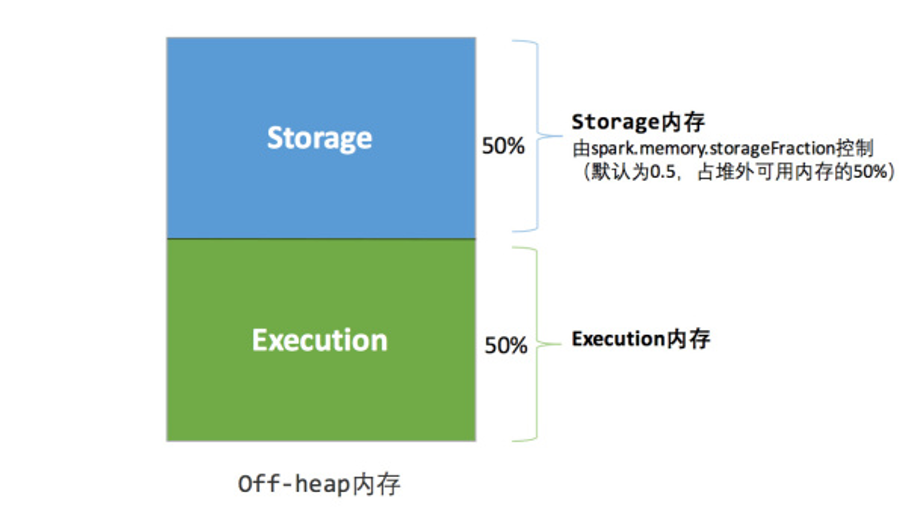
6.3 统一内存管理
1) 什么是统一内存管理
Spark1.6之后引入的统一内存管理机制,各个区域内存的大小可变
2) 与静态内存管理的区别:
统一内存管理"存储内存"和"执行内存共享"同一块空间,可以动态占用对方的空闲区域
3) 当前Spark默认的内存分配是按照统一内存管理的模式
堆内内存:
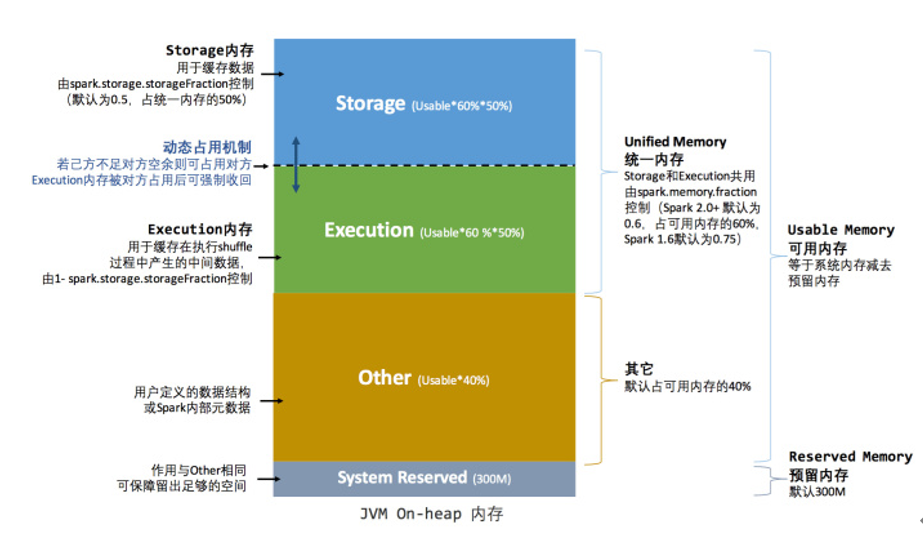
堆外内存:
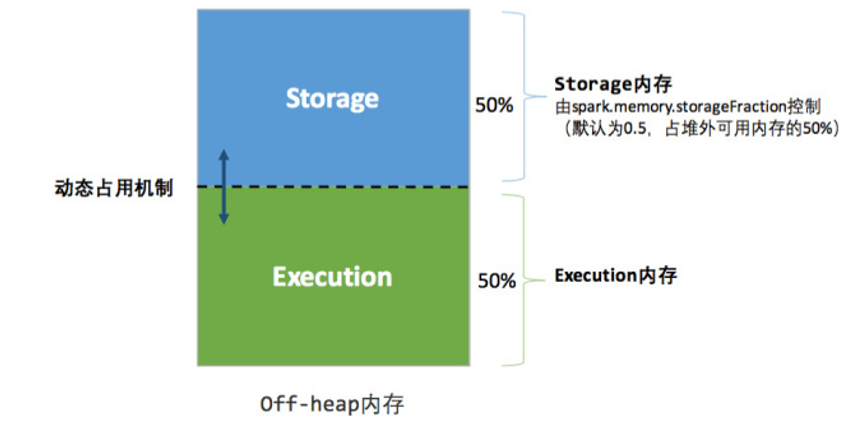
6.4 统一内存管理 - 动态占用机制
-- 1. 优点
1)设定基本的存储内存和执行内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围;
2)双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的Block)
3)执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间;
4)存储内存的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle过程中的很多因素,实现起来较为复杂。
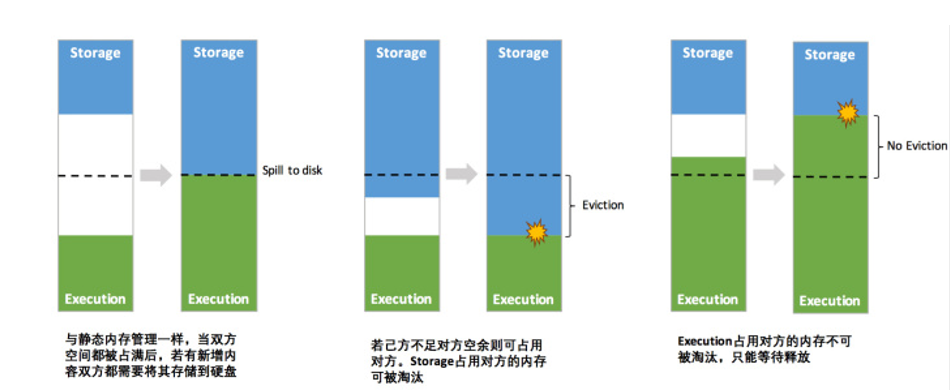
-- 注意事项
1. 如果是storage借了Execution的内存,那么当Execution需使用时,storage占用Execution的内存就要想办法还给Execution,一般可以进行落盘,但是在内存中的数据有一个存储级别,如果仅仅是Memory_Only的话,那么此时占用内存的数据就会丢失。
2. 如果是Execution借了storage的内存,那么当storage需使用时,Execution并不会把内存还给storage,那么此时storage的数据就会溢写磁盘,如果不能溢写的话,那么就会丢失或淘汰。
补充
Java的List和Scala的List的转换:
