0. 前言
- 相关资料
- B站视频(字幕是自动生成的,但也差不多够用)
- 引子:
- 理想状态下的工作:获取数据 -> 构建预测系统(如服务器API或本地部署程序)
- 实际工作:标注数据 -> 构建/测试模型 -> 管理计算资源 -> 训练/测试模型 -> 部署模型 -> 监控测试结果、构建 flywheel
- 为了实现实际工作中的各种功能,我们需要选择开发套件与相关工具。
- 本节课关注的就是中间这部分。

- 主要内容图包括:
- 编程语言以及编辑器选择
1. 编程语言与编辑器
- 语言 Python,主要因为第三方包多
- 编辑器选择很多,推荐的有
- VSCode:推荐使用的编辑器
- Jupyter:Data science 中常用
- 适合编写 getting started 教程等简单程序
- 不适合复杂的任务,如难以版本控制、难以测试、没有IDE功能(如代码跳转)、难以运行分布式任务
- Streamlit:完美解决了interactive applets的问题,即写Python发布一个简单Web应用(替代flask和前端)
2. 计算资源
2.1. 为什么计算资源很重要
- 可以从两个维度考虑对应功能
| 维度 | 所需功能 | 理想状态 | 解决方案 |
|---|---|---|---|
| 开发(Development) | 写代码、调试模型、查看结果 | 快速开发模型并进行训练,最好有图形界面 | 有1-4GPU的桌面系统或云服务器 |
| 训练/测试(Training/Evaluation) | 模型结构以及超参数搜索、训练大模型 | 快速执行训练并回顾结果 | 4卡桌面系统,或GPU集群 |
- 另外,随着深度学习的发展,模型也越来越大,需要的算力也越来越多。
- 算力很重要,但新模型、新结构也很重要,可以用更少的算力做更多的事情。
2.2. 如何选择计算资源
- 本节主要介绍以下几个部分:
- GPU简介
- 云服务器简介
- 实体机简介
- 如何选择
- GPU简介:
- 主要就是使用NVidia设备,目前最快的是TPU(只能在Google Compute Platform中使用),Intel和AMD正在尽力赶上。
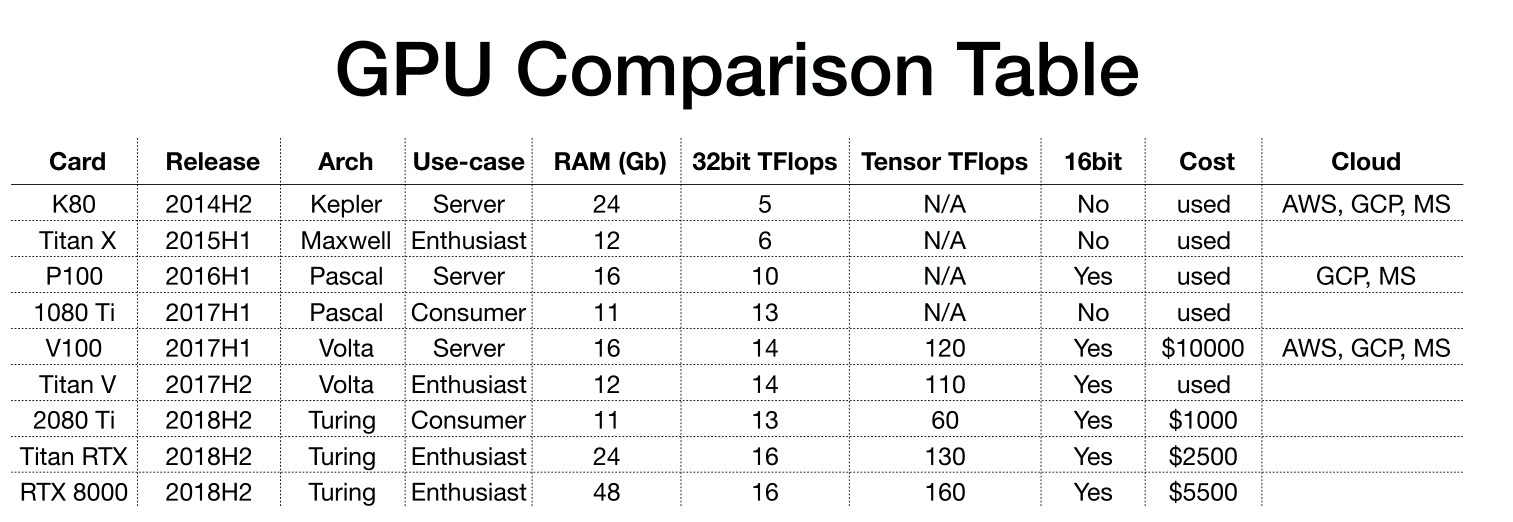
- GPU基础如下表,要介绍一下这些参数
- Arch就是GPU架构,从上到下就是进化的过程
- 不要使用Kepler Maxwell架构,比Pascal、Volta慢2-4倍,不应该买,太老了。一般比较便宜。
- Pscal架构的(P100/1080ti)如果要买就买二手,中档的
- Volta和Turing是现在应该买的,支持混合精度
- 2080ti比1080ti在32bit上快1.3倍,但在16bit快2倍
- 当时V100(2019年秋天)是最快的
- Use-case就是面向对象,用于服务器(Server)、发烧友(Enthusiast)还是普通用户(Consumer)
- RAM就是显存大小,目前最重要的参数
- 32bit TFlops 和 Tensor TFlops 就是计算速度,32位浮点数计算速度,Tensor Cores是为深度学习混合精度计算设计的
- 16bit就是只使用16位运算(而不是混合精度)
- 这个只在P100上是有,其他卡要么不支持16bit,要么就是支持Tensor Cores(混合精度计算,比单纯16bit好,所以就不用16bit了)
- 如果只有P100那就用16bit,速度提高2倍,显存提高1.5倍。
- Arch就是GPU架构,从上到下就是进化的过程
- 云服务供应商对比
- AWS最贵,只能使用预设实例。可以关注下Spot实例,很便宜。
- Google Cloud Platform有多重GPU选择(不是预设实例,可自己选择)且支持TPU
- 没人推荐使用Azure
- 有一些新兴选择,国外的也不关心了。
- 买实体机,可以买组装好的(pre-built),也可以自己组装
- 价格对比思路:
- 计算实体机与云服务器的价格,看看实体机的价格能够租服务器跑多久。
- 另一种思路,我们需要尽快完成训练,一次开多个实例进行训练,总时间(GPU hours)不变,但由于并行训练,实际过去的时间少了。
- 实际情况:
- 云服务器很贵,但扩展很容易。
- 本地服务器便宜,但超过一定数量后维护非常麻烦。
- 建议:
- 对于单人开发者、刚刚起步的团队:使用4卡Turing PC开发,使用相同的4卡PC训练(直到architecture is dialed in),如果需要更多算力可以再买一台或租云服务器。
- 对于大公司:每个ML Scientist配一台4卡Turing PC,或使用V100实例,使用云服务器实例进行训练与测试。
3. 资源管理
- 主要就是服务器计算资源管理。
- 需求:多个人使用多台服务器,每个人使用不同的环境。
- 目标:能够整合各类资源,非常容易地进行多个实验。
- 解决方案:
- 手工表格分配,低端但用的人很多。
- Python脚本,会自动占用空闲资源,会使用以前的集群任务(Job)调度,每个Job定义了要进行的任务,然后这些Job会按顺序执行。
- Docker(轻量级虚拟机) + Kubernetes(在集群中运行多个容器)
- Kubeflow,Google开源项目,主要处理 multi-step ML workflows,有超参数调节的插件。
- polyaxon,全栈机器学习平台,开源,但也提供了一些付费功能。
4. 其他
-
深度学习框架
- 如果没有特殊要求,就TensorFlow/Keras和PyTorch二选一。
- 目前发展方向类似,都是易于开发的 define-by-run 模式(即TF中的eager模式),以及多平台优化的静态计算图(即PyTorch中的TorchScript)。
- 目前新项目PyTorch较多。
- fast.ai 可能适合一些新手且不深入的用户。
- 如果没有特殊要求,就TensorFlow/Keras和PyTorch二选一。
-
分布式训练
- 分布式训练有两种方式,数据并行或模型并行。
- TF/PyTorch自带分布式训练功能。
- 其他解决方案包括Ray、Horovod。
-
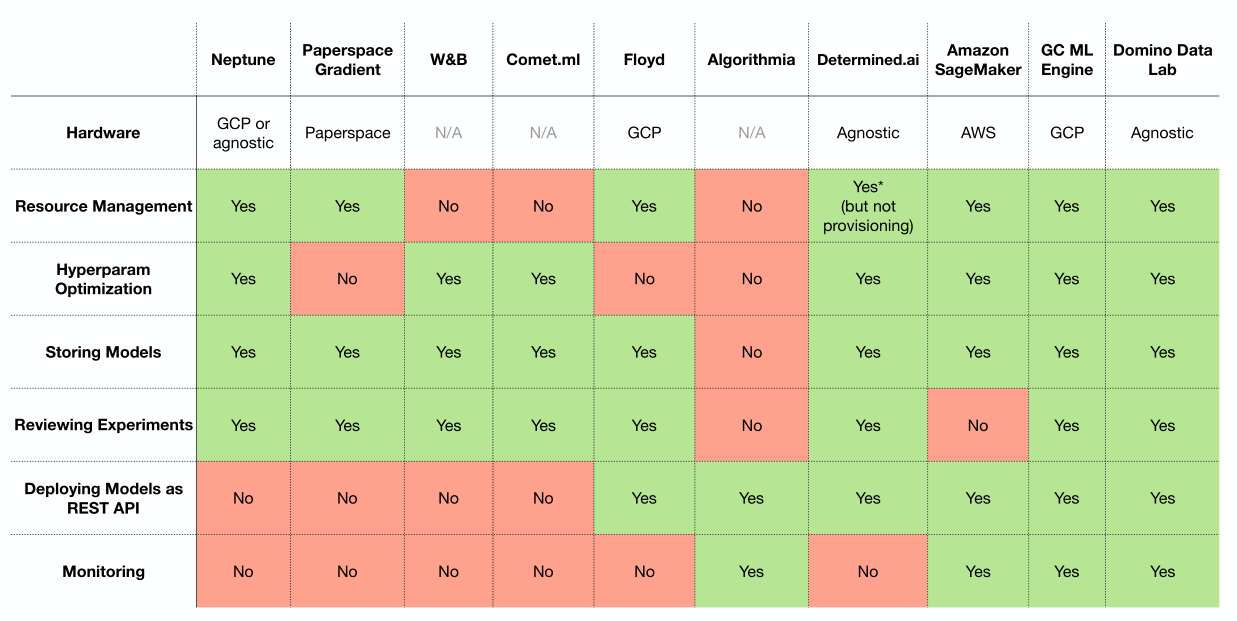
实验管理
- 现状:就算一次跑一个实验,时间长了也会搞糊涂,更不要说跑多个实验了。
- Tensorboard:记录单次实验不错的方案,但管理多个实验非常不方便。
- Losswise/Comet.ml/Weights & Biases:这些都类似,都是安装一个包,在训练过程中按照tensorboard的方式调用,不同之处在tensorboard保存数据在本地,而其他库则是上传到对应服务器,然后到对应网站中查看。
- MLFlow Tracking:开源软件,可以本地部署相关平台,功能非常强大。
-
超参数调节:
- Hyperas,即 Keras + Hyperopt
- Sigopt,没细看
- Ray-Tune:看来后续要查一下这个相关内容了,有很多SOTA算法
- Weights & Biases 有相关内容
-
All-in-one,即一体化解决方案