0. 前言
- 《全栈深度学习》第一课:如何启动一个机器学习项目?
- 相关资料
- B站视频(字幕是自动生成的,但也差不多够用)
1. Overview
- 机器学习项目与普通软件工程项目的差距很大,很难判断哪些任务困难,哪些容易
- 某份报告表明,85%的机器学习项目失败了,主要原因在于:
- 机器学习还处于研究中,很难达到100%的成功率。
- 但有一些项目注定失败,原因在于:
- 技术上不可行
- 无法从学术界移植到工业界
- 没有明确的标准表明成功与否,没有明确的牧宝
- 团队管理混乱
- 本课程后续内容以机器人 pose estimation 作为应用场景

2. Lifecycle
-
介绍机器学习项目的声明周期(几个阶段,以及阶段间的关系)
-
机器学习项目并不是流水线,各个阶段一般都需要重复作业。
-
四个阶段
- Planning & project setup:决定要研究的内容,期望达成的目标,完成项目需要多少资源
- Data collection & labeling:确定需要训练的目标对象、设置传感器(如摄像头)采集数据,标注数据
- Training & debugging:使用opencv实现一些baseline,文献综述了解最新、最强技术并复现,改进模型
- Deploying & testing:在实验室环境下部署,进行测试防止退化(感觉意思是写好日志系统,在出问题的时候我们可以回顾、定位这些问题),在生产环境中部署
-
各个阶段之间的关系
- Data -> Planning:发现数据太难获取,或太难标注,可用其他更容易标注的方法来解决问题
- Training -> data:出现过拟合需要更多数据,发现数据不可靠(标注质量不行)
- training -> planning:发现计划难以实现,发现难以同时满足其他要求(比如要又快又好)
- deploying -> training:实验室环境中性能不够,需要进一步提升模型
- deploying -> data:发现训练数据与测试场景数据不匹配(我们之前有一些假设,但实际场景中假设不成立),需要重新采集数据,寻找一些困难的场景(mine hard cases)
- deploying -> planning:使用的性能指标不合适(不能为下游用户提供帮助),现实世界中达不到预期性能(需要对我们的要求进行回顾)
-
总体内容如下:
- 右边的就是单个机器学习项目中的活动
- 昨天是多个机器学习项目中共有的,主要就是如何构建团队以及通用工具。
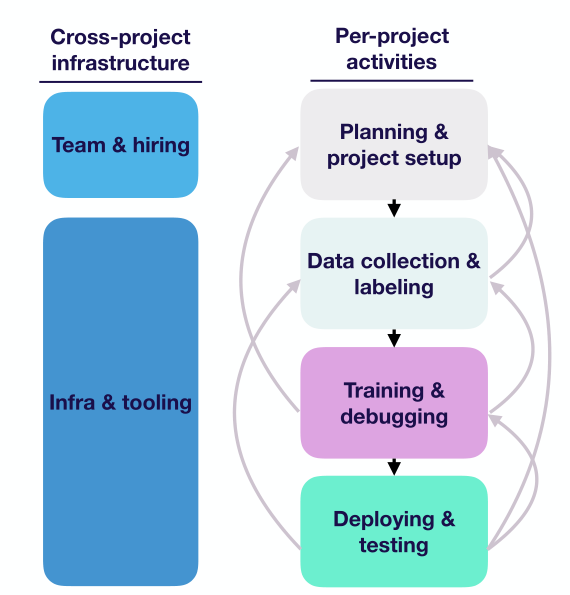
- 还需要了解什么内容
- 了解领域中现在的最优情况,比如哪些内容能做,后续还可以研究哪些方面
- 现在哪些研究领域比较有希望、有前途
- Q&A
- 如何调研SOTA:对于一个新领域,寻找1-2篇landmark工作,他们引用的工作,引用他们的工作(按引用料排)
- 如何向高层沟通机器学习项目相关的内容:很难沟通因为机器学习项目与普通工程项目有很大区别,后者时间可控,前者永远不知道能做哪些、做不了哪些
3. Prioritizing
- 主要内容
- 选择怎样的机器学习项目
- 评估机器学习项目的成本以及可行性
- 关键点在于:
- 如何寻找影响力大的机器学习项目,其中cheap prediction非常有价值
- 项目的成本主要在于数据获取难度,但也要考虑精度要求
- 项目优先级坐标系
- 通过“影响力(Impact)”和“可行性(Feasibility)”建立坐标系
- 优先进行影响力大、可行性高的项目
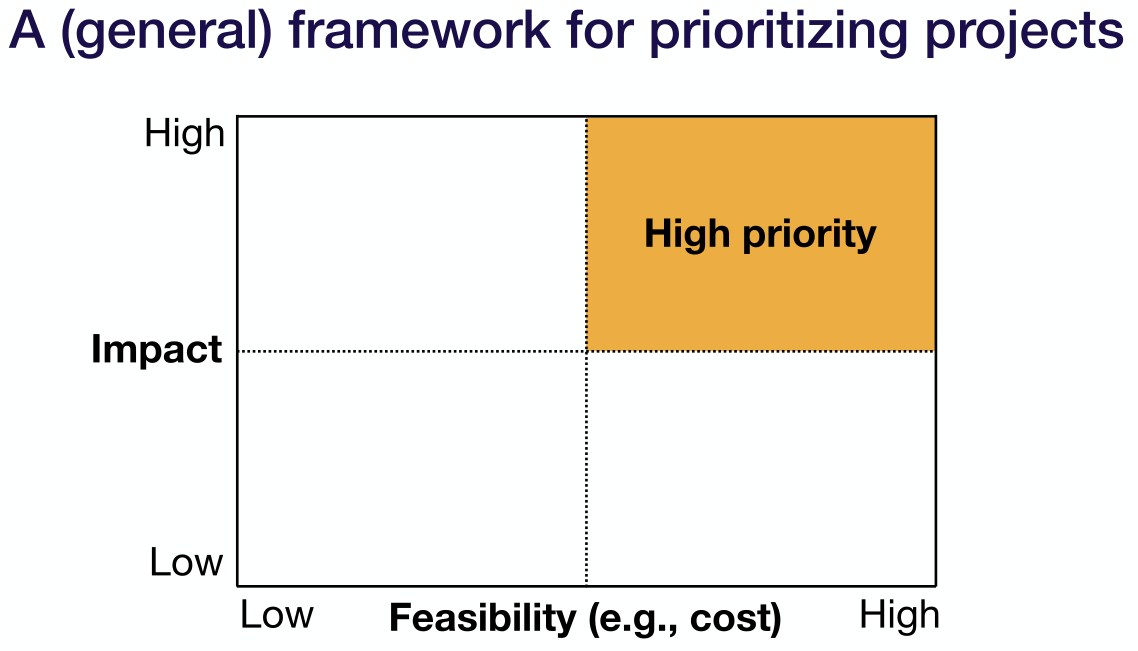
- 高影响力机器学习项目的Mental models
-
我不太明白Mental models是什么意思,百度了一下好像是心理学的概念,中文是 心智模式。
- 我猜测意思是高影响力的机器学习项目应该具备什么样的特征。
-
The economics of AI 这本书的观点:
- AI降低了“预测”的成本,而预测是决策的关键
- cheap prediction(廉价的预测),降低了预测的成本,以前成本特别高的现在普通人也能使用(比如自动驾驶)
- Implication(应该寻找什么样的项目):寻找拥有cheap prediction且cheap prediction能产生重大影响的。
-
Software 2.0
- 传统软件范式(1.0):有明确指令(instructions/rules)
- Software 2.0:首先由人来确定目标,然后通过算法来寻找一个程序实现上面的目标。
- 都与数据集有关,which get compiled via optimization
- Implications(应该找什么样的项目):相关的功能可以通过模型学习,而不能通过编程实现的 rule-based projects。
-
- 评估项目可行性
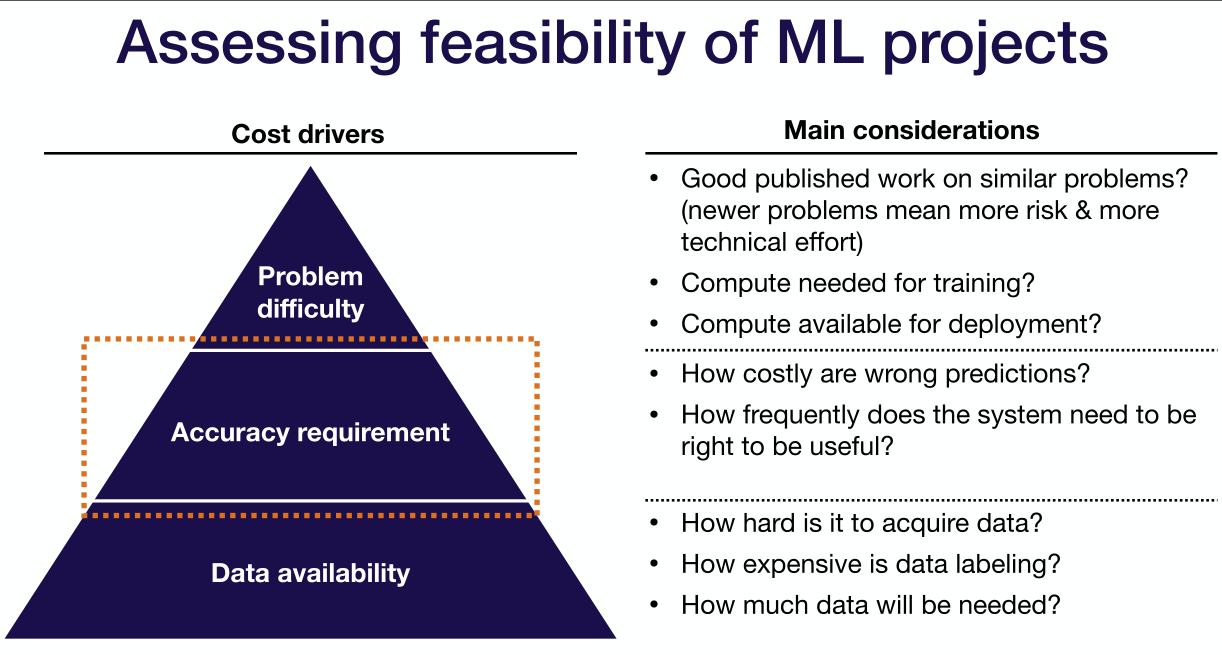
- 模型准确率与成本的关系
- 成本随着模型准确率呈指数增长。
- 如何理解?有些错误样本出现概率很低,要获取更多错误样本就需要海量数据。
- 机器学习任务难度如何判断
- Andrew Ng 有一个非常不严谨的理论:人1秒内能做的工作,极其都能做。
- 正例:图像识别、语音识别、机器翻译、抓取物品
- 反例:理解讽刺/幽默、手上的静谧动作、泛化到新场景
- 机器学习中哪些任务难度大
- 无监督学习、强化学习
- 在某些场景(有海量数据)效果很好,但总体效果一般
- 监督学习哪些难度大:
- 回答问题、总结文本
- 预测视频
- 3D模型
- 现实世界语音识别(噪声多)
- 做数学题
- word puzzles
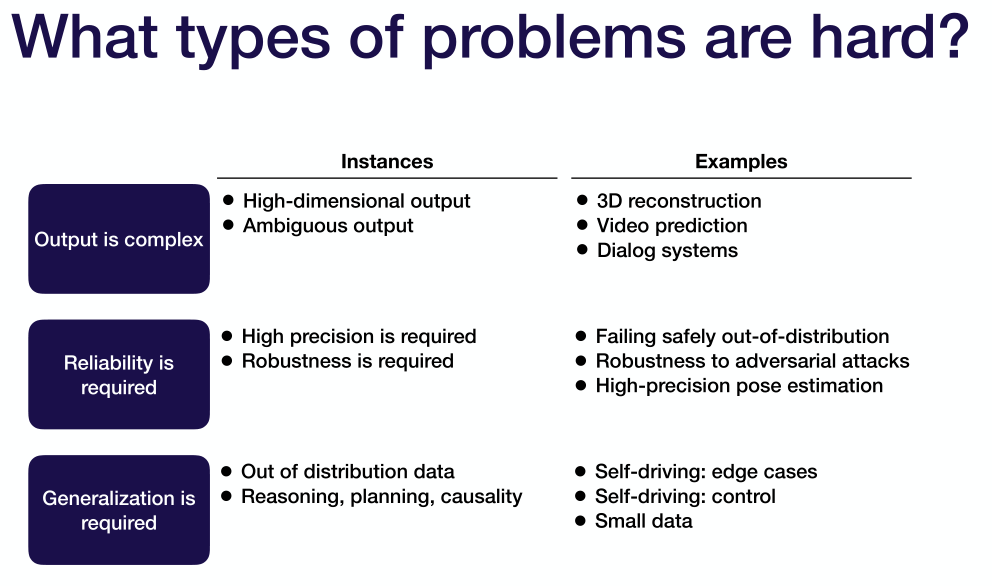
- 哪些方面的任务比较困难
- 输出复杂、对精度要求特别高、对泛化能力要求特别高
- Andrew Ng 有一个非常不严谨的理论:人1秒内能做的工作,极其都能做。
4. Aechetypes
- 主要内容包括:
- 机器学习项目分哪几类
- 每一类的特点是什么
- 问题主要分为三类,如下图
- 提升现有功能,如推荐系统、游戏AI、代码补全
- 增强(augment)手工工作,如草图转换
- 自动化手工工作,如自动驾驶
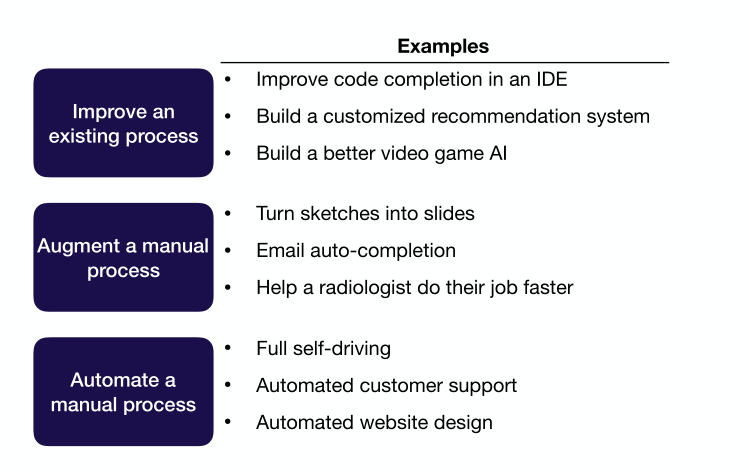
- 确定每类问题的关键

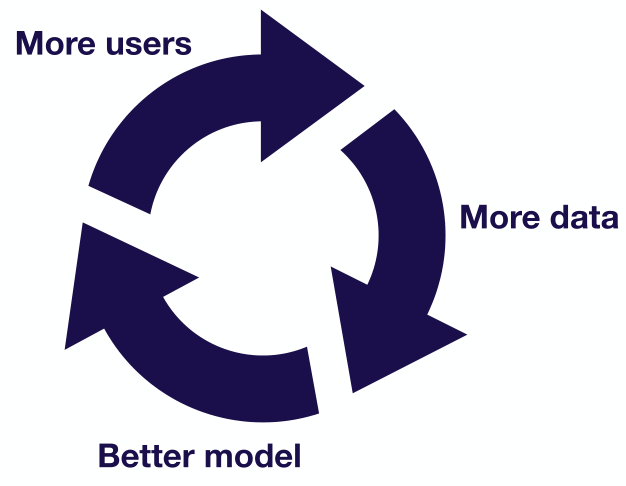
- Data Flysheel:理想状态下的机器学习项目数据流
- 三类项目的可行性与影响,以及提升方法
- Automate a manual process 的影响力最高但实施难度最大
- 提升方法:实时过程最好将人也添加到 dataflywheel 中,或对整个项目实时环境添加一些限制
- Augment a manual process 的影响力较高,实时难度较大
- 提升方法:需要更好的设计产品细节,先发布一个较好的模型并持续优化,如 facebook 在图片中可以可以检测人脸并让用户判断有没有标错
- Improve an existing process 的影响力最低,但实时难度也较小
- 提升方法:要创建一个数据循环,不停地提高模型精度
- Automate a manual process 的影响力最高但实施难度最大
5. Metrics
- 主要内容是如何选择性能优化参数,其关键在于:
- 存在一个悖论:现实世界很复杂、需要多个指标,但模型训练最好只使用一个指标。
- 所以需要确定一个挑选性能指标的准则,这个准则可以变也会变
- 一般有三种多指标混合的方法
- 平均(算术平均或加权平均):比如 precision 与 recall 平均
- Threshold n-1 metrics, evaluate the nth:某些性能指标高于阈值就行,某一个性能指标则尽可能好。
- 如何选择 threshold 指标:
- domain judgement(e.g., which metrics can you engineear around?)
- which metrics are least sensitive to model choice(对模型选择最不敏感)
- 那些指标以及以及快达到预期了
- 如何选择 threshold 数值:
- domain judgement(e.g., what is an acceptable tolerance downstream? What performance is achievable?)
- baseline model 表现如何
- 当前有多重要
- 如何选择 threshold 指标:
- More complex/domain-specific formula
6. Baselines
- 基准,判断我们训练的模型效果到底好不好。
- 为什么需要基准
- 预期结果的下限
- baseline性能越好,作用越大
- 训练好模型后,对比不同的基准,后续工作安排也不同
- 预期结果的下限
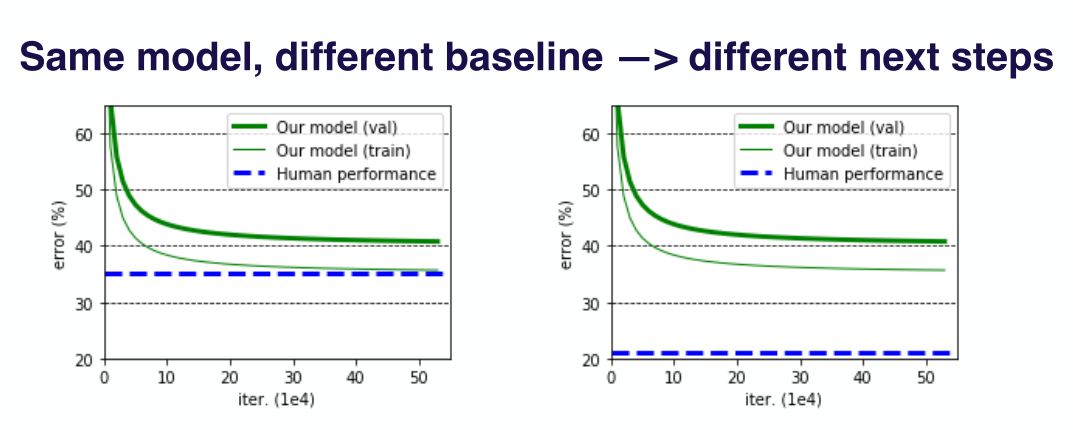
-
如何确定基准
- 外部基准:业务要求,公开结果(要确定公开结果与我们所需的是同一事件)
- 内部基准:简单ML算法(如K邻近等)、简单规则、人的预测结果
-
实际应用中如何构建基准
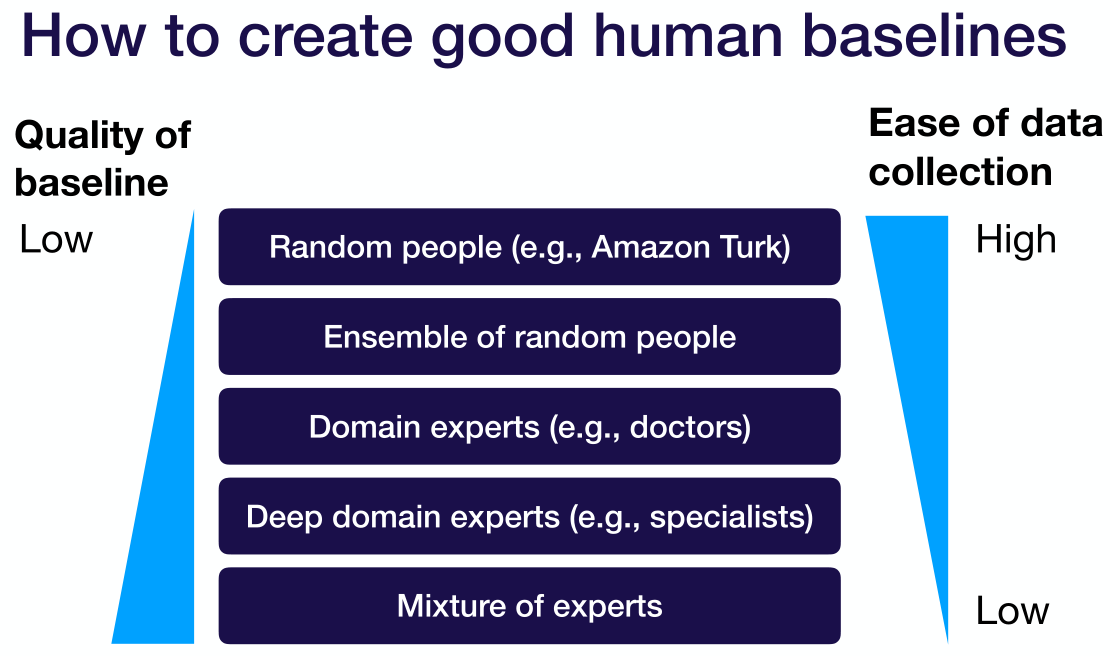
- 另外,建议就算时间紧也不要跳过“基准”这一步,但可以在这一步中少花事件。