python爬虫探索原神世界
文章目录
一、前言
《原神》是一款开放世界冒险游戏,有着丰富多彩的元素,可爱帅气的人物角色,五彩斑斓的风景,那我们怎么使用python爬虫打开“原神世界”的大门呢?我们今天就来用python爬虫探索一下游戏角色!
二、页面分析
首先,打开《原神》官网,找到“角色”:链接传送门

然后进行右击检查,寻找想要找的元素。
如:
人物图:

人物名:
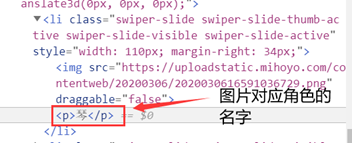
寻找完毕,右击复制xpath,准备编写爬虫程序!

三、完整代码
# -*- coding: UTF-8 -*-
"""
@Author :远方的星
@Time : 2021/3/3 20:18
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/column/91164
"""
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
}
url = 'https://ys.mihoyo.com/main/character/mondstadt?char=0'
response = requests.get(url=url, headers=headers).text
html = etree.HTML(response)
list_all = html.xpath('//*[@id="frame"]/div[4]/div/div/div[3]/div[1]/ul/li')
print(list_all)
运行结果:

emmmm,是个[ ],发生什么事了,是我xpath写错了了,不可能呀,我是复制的!
然后,我打印了“response”,哦~要命 ~,爬取的结果和页面的源代码不一样。
那我只好出动“秘密武器”了,就决定是你啦,“selenium”
四、完整代码—2
# -*- coding: UTF-8 -*-
"""
@Author :远方的星
@Time : 2021/3/4 12:16
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/column/91164
"""
import requests
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os
# 导入请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
}
# 创建文件夹
path = 'D:/原神/蒙德城'
if not os.path.exists(path):
os.mkdir(path)
# 实现无可视化界面(固定写法)
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 蒙德城的初始页面
url = 'https://ys.mihoyo.com/main/character/mondstadt?char=0'
# 如果想下载璃月港角色,使用这个url = 'https://ys.mihoyo.com/main/character/liyue?char=0',建议path那里也改动一下哟
# 初始化browser对象
browser = webdriver.Chrome(executable_path='chromedriver.exe', options=chrome_options)
# 模拟浏览器进行访问
browser.get(url=url)
# 获取页面的源代码
page_text = browser.execute_script("return document.documentElement.outerHTML")
html = etree.HTML(page_text)
list_s = html.xpath('//*[@id="frame"]/div[4]/div/div/div[3]/div[1]/ul/li') # 提取到图片的li节点
for i in range(len(list_s)):
image_url = list_s[i].xpath('./img[1]/@src')[0] # 获取图片的链接
num = i + 1 # 代表着图片对应的名字的神秘数字
# 获取角色名字
name = html.xpath('//*[@id="frame"]/div[4]/div/div/div[3]/div[2]/div[1]/ul/li[{}]/p/text()'.format(num))[0]
image_name = name + '.png' # 得到图片名字
image_path = path + '/' + image_name
image_data = requests.get(url=image_url, headers=headers).content # 获取图片内容
with open(image_path, 'wb') as f:
f.write(image_data)
print(image_name, '===========>下载完毕!!!')
f.close()
运行结果:


哦~ 舒服了~
可爱的可莉拿到了
五、补充
小伙伴如果想要自己尝试练习selenium,建议把“无可视化”的代码去掉嗷,要不然,你会发现你的CPU不知不觉就满了。
作者:远方的星
CSDN:https://blog.csdn.net/qq_44921056
腾讯云:https://cloud.tencent.com/developer/column/91164
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。