贪心算法
求解最优化问题的算法通常需要经过一系列的步骤,在每个步骤都面临多种选择。对于许多最优化问题,使用动态规划算法来求最优解有些杀鸡用牛刀了,可以使用更简单,更高效的算法。贪心算法(greedy algorithm)就是这样的算法,它在每一步都做出当时看起来最佳的选择,也就是说,它总是做出局部最优的选择。
贪心选择性质
我们可以通过做出局部最优(贪心)选择来构造全局最优解,当进行选择时,我们直接做出当前问题中看来最优的选择,而不必考虑子问题的解,一个贪心算法通常是自顶向下的,进行一次又一次选择,将给定问题实例变得更小。
赫夫曼编码
赫夫曼编码可以很有效地压缩数据。假定我们希望压缩一个10万个字符的数据文件,如下图给出了文件中所出现的字符和它们出现的频率,也就是说文件中只出现6个不同的字符,其中字符 a a a出现了45000次。

如果用用定长编码,指定一个3位的码字,我们可以将文件编码为300000位的长度,但使用上表所示的变长编码,仅用224000位编码文件。 ( 45 ∗ 1 + 13 ∗ 3 + 12 ∗ 3 + 16 ∗ 3 + 9 ∗ 4 + 5 ∗ 4 ) ∗ 1000 = 224000 (45* 1+13*3+12*3+16*3+9*4+5*4)*1000=224000 (45∗1+13∗3+12∗3+16∗3+9∗4+5∗4)∗1000=224000对应的二叉树表示如下,每个叶节点标记了一个字符及其出现的频率。每个内部节点标记了其子树中叶节点的频率之和。(a)对应定长编码 a = 000 , . . . , f = 101 a=000,...,f=101 a=000,...,f=101的二叉树,(b)对应最优前缀码 a = 0 , b = 101 , . . . , f = 1100 a=0,b=101,...,f=1100 a=0,b=101,...,f=1100的二叉树。
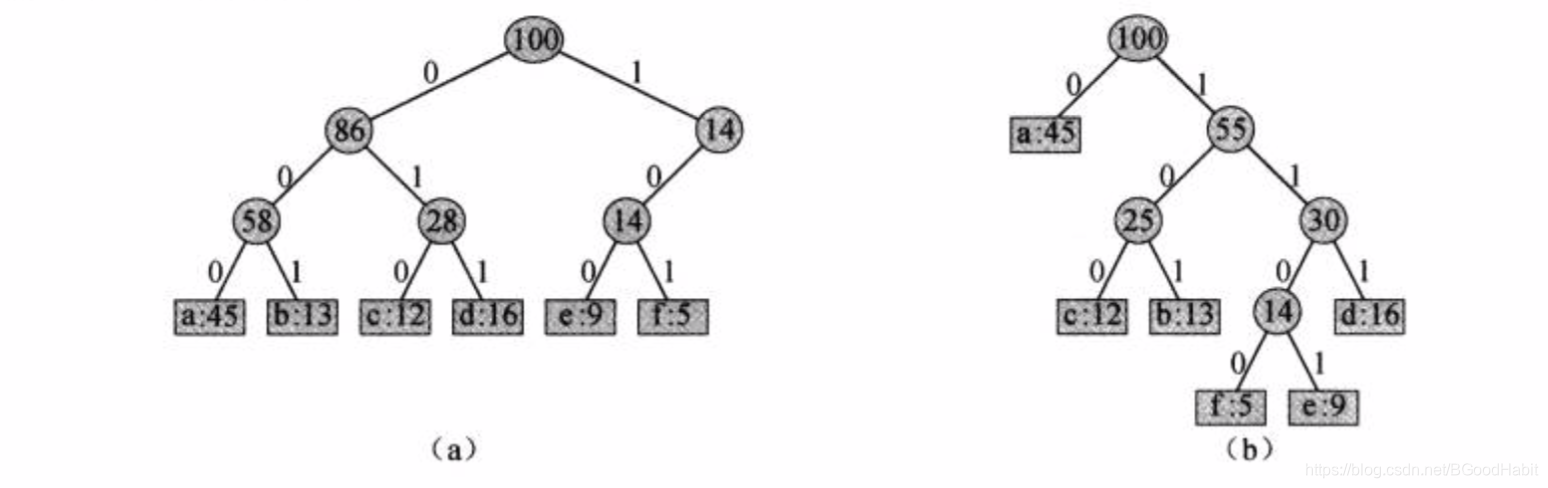
给定一棵对应的qian’zhui前缀码的树 T T T,我们可以容易地计算出编码一个文件需要多少个二进制位,对于字母表 C C C中的每个字符 c c c,令属性 c . f r e q c.freq c.freq表示 c c c在文件中出现的频率,令 d T ( c ) d_T(c) dT(c)表示 c c c的叶节点在树中的深度。则编码文件需要 B ( T ) = ∑ c ∈ C c . f r e q . d T ( c ) B(T)=\sum_{c \in C}c.freq.d_T(c) B(T)=c∈C∑c.freq.dT(c)个二进制位,我们将 B ( T ) B(T) B(T)定义为 T T T的代价。
构造赫夫曼编码
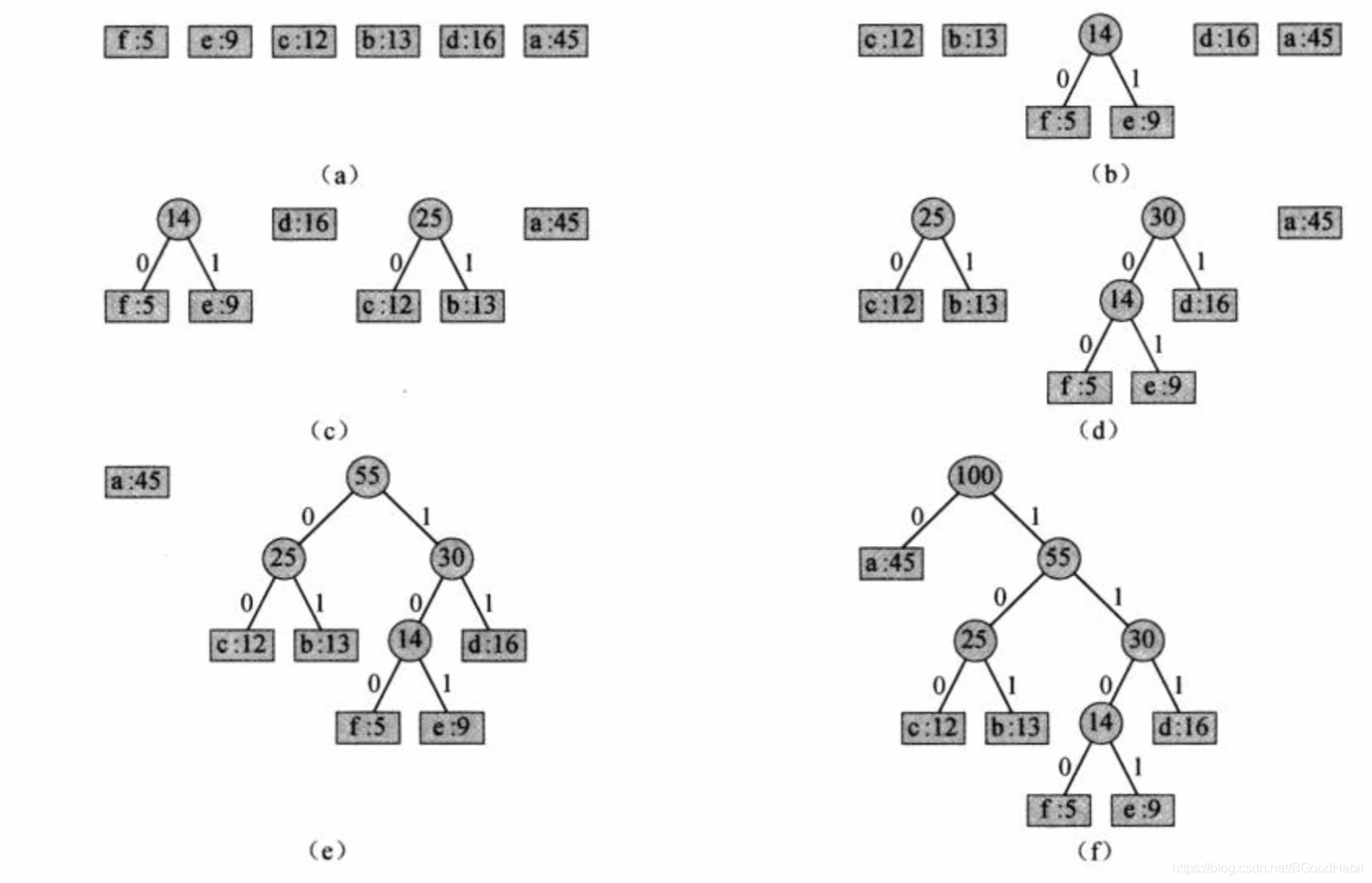
赫夫曼设计了一个贪心算法来构造最优前缀码,被称为赫夫曼编码(Huffman code)。我们假定 C C C是一个 n n n个字符的集合,而其中每个字符 c ∈ C c \in C c∈C都是一个对象,其属性 c . f r e q c.freq c.freq给出了字符的出现频率。算法自底向上地构造出对应的最优编码的二叉树 T T T。它从 ∣ C ∣ |C| ∣C∣个叶节点开始,执行 ∣ C ∣ − 1 |C|-1 ∣C∣−1个“合并”操作创建出最终的二叉树。如下图,赫夫曼算法执行过程:
python实现赫夫曼编码如下:
# -*-coding:utf8 -*-
import sys
#构造节点
class Node(object):
def __init__(self, key, code=0, parent=None,lchild=None, rchild=None):
self.key = key
self.code = code
self.parent = parent
self.lchild = lchild
self.rchild = rchild
class HuffmanTree(object):
def __init__(self,root=None):
self.huffman_tree = []
self.root = root
#找两个key值最小的节点
def find2node(self, flag):
mini = []
for i in range(len(self.huffman_tree)):
if i in flag:
continue
if len(mini) < 2:
mini.append(i)
else:
if self.huffman_tree[i].key < max([self.huffman_tree[mini[0]].key, self.huffman_tree[mini[1]].key]):
pos = 0 if self.huffman_tree[mini[0]].key > self.huffman_tree[mini[1]].key else 1
mini[pos] = i
# let lchird.key < rchild.key
if self.huffman_tree[mini[0]].key > self.huffman_tree[mini[1]].key:
temp = mini[0]
mini[0] = mini[1]
mini[1] = temp
#return sorted(mini)
return mini
def build(self, C):
#flag记录已经合并的节点
flag = []
#初始化各关键字key节点
n = len(C)
for key in C:
self.huffman_tree.append(Node(key))
#构建hufuman,n个值,需要n-1次合并操作
for i in range(n,2*n-1):
mini = self.find2node(flag)
print(str(mini[0])+'\t'+str(mini[1]))
#合并的节点记录,下次合并不需要考虑
flag.append(mini[0])
flag.append(mini[1])
#构建新的Node节点,key为两个子节点key相加
key = self.huffman_tree[mini[0]].key + self.huffman_tree[mini[1]].key
node = Node(key,lchild=self.huffman_tree[mini[0]],rchild=self.huffman_tree[mini[1]])
#新节点加入
self.huffman_tree.append(node)
self.huffman_tree[mini[0]].parent = node
self.huffman_tree[mini[1]].parent = node
self.huffman_tree[mini[1]].code = 1
#记录root节点
print(node.key)
self.root = node
#中序遍历
def inorder_tree_walk(self, tree):
if tree is not None:
self.inorder_tree_walk(tree.lchild)
print(tree.key, end=" ")
self.inorder_tree_walk(tree.rchild)
#获取节点的编码
def huffman_code(self, cur):
path = []
while cur.parent!=None:
#path结果保存从根节点搜索路径的编码结果
path.insert(0,cur.code)
cur = cur.parent
return path
if __name__=='__main__':
tree = HuffmanTree()
C = [5,9,12,13,16,45]
tree.build(C)
tree.inorder_tree_walk(tree.root)
print()
#打印每个叶子节点的赫夫曼编码
for i in range(len(C)):
path = tree.huffman_code(tree.huffman_tree[i])
print('key='+str(tree.huffman_tree[i].key))
print(path)
具体代码,可参考github地址算法导论各章节算法python实现