前言
Glidedsky这关的JS解密不同于我之前见到的,希望大家好好看,好好学!

温馨提示:保护好头发!

1、网页查看

2、JS解密过程(细心看哦)
既然是JS加密过的,那么数据肯定不是静态的,如下
直接请求该页面,或取到的html代码粘贴到html文件打开是没有数字的

打开控制台查看XHR


这里有个问题,我之前查看是可以查看到数据的,但不知道为什么又看不到数据了,有知道的小伙伴麻烦在评论区告诉我下,谢谢。
网上查的说什么网页可以感应用户打开了控制台,咱也不知道,咱也不敢问,还有这么吊的操作

如何还有不明白的小伙伴,可以参考我这篇JS解密文章 Python爬虫JS解密详解,写的很详细,这玩意搞多了就有经验了
不说了,咱们接着看
往下翻可以看见,该请求带了3个参数
- page:当前页数
- t:类似于时间戳
- sign:进过某种方法加密后的数据

按住Ctrl+Shift+f 进行搜索,输入sign,可见有6个匹配的

有兴趣的小伙伴可以点进去再次搜索sign,都是些跟下图一样牛头不对马嘴的匹配


按我之前的JS解密经验,不应该是直接匹配到,然后搞个什么函数加密的嘛 o(╥﹏╥)o
都看到这份上了,接直接放弃也不是我个性格,耐着性子接着研究研究。。。。
然后发现个新办法,现在教给大家——就是打XHR断点,如下

复制部分URL就好了,不用全部复制



现在进入最关键步骤——使用python代码得到上面的数据
获取t值

获取sign值
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA),SHA1比MD5的安全性更强。对于长度小于2^ 64位的消息,SHA1会产生一个160位的消息摘要。
不要慌,python中提供了hashlib库解决,真是厉害啊!

成功了,老铁们可以来波点赞嘛!(*^▽^*)
拼接URL请求,注意:返回数据为json格式
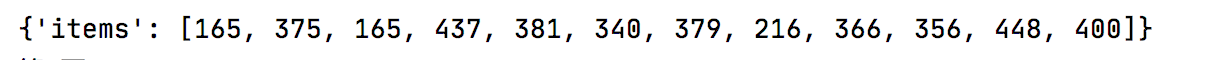
完美
3、解密答案(完整代码)
import requests
import hashlib
import time
import math
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
#注意Cookie自己填哦
"Cookie": ""
}
sum = 0
def get(response):
global sum
for i in response['items']:
sum += int(i)
if __name__ == '__main__':
#1000个页面
for i in range(1000):
#获取t值
t = math.floor(time.time())
#获取sign值
sha1 = hashlib.sha1()
data = 'Xr0Z-javascript-obfuscation-1' + str(t)
sha1.update(data.encode('utf-8'))
sign = sha1.hexdigest()
print("第"+str(i+1)+"页")
#拼接url
url = "http://glidedsky.com/api/level/web/crawler-javascript-obfuscation-1/items?page="+str(i+1)+"&t="+str(t)+"&sign="+str(sign)
response = requests.get(url=url,headers=headers).json()
get(response)
#打印最终数字
print(sum)

闯关成功,解密成功!!!

注意填上Cookie,我提供的代码没有填上Cookie值

博主会持续更新,有兴趣的小伙伴可以点赞、关注和收藏下哦,你们的支持就是我创作最大的动力!
博主开源Python爬虫教程目录索引(宝藏教程,你值得拥有!)