1.算法思想
快速排序(Quicksort)是对冒泡排序算法的一种改进。
快速排序由C. A. R. Hoare在1960年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序算法虽然能够确保,划分出来的子任务彼此独立,并且其规模总和保持渐进不变,却不能保证两个子任务的规模大体相当。实际上, 甚至有可能极不平衡。因此, 该算法并不能保证最坏情况下的O(nlogn)时间复杂度。尽管如此,它仍然受到人们的青睐,并在实际应用中往往成为首选的排序算法,并被集成到Linux和STL等环境中。究其原因在于,快速排序算法易于实现,代码结构紧凑简练,而且对于按通常规律随机分布的输入序列,快速排序算法实际的平均运行时间较之同类算法更少。
2.算法步骤
快速排序基本算法思想是分治算法,通过多次比较和交换来实现排序,其排序流程如下:
(1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
(2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
(3)然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
(4)重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
3.动态演示

4.左右指针法
(1)具体算法步骤
设要排序的数组是a[0]……a[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它左边,所有比它大的数都放到它右边,这个过程称为一轮快速排序。
一趟快速排序的算法是:
1)设置两个变量left、right,排序开始的时候:left=0,right=N-1;
2)以第一个数组元素作为关键数据,赋值给pivot,即pivot=a[0];
3)从right开始向前搜索,即由后开始向前搜索(right–),找到第一个小于pivot的值a[left],将a[left]和a[right]的值交换;
4)从left开始向后搜索,即由前开始向后搜索(left++),找到第一个大于pivot的a[left],将a[left]和a[left]的值交换;
5)重复第3、4步,直到left == right,当在当轮内找完一遍以后就把中间数pivot回归;
(2)举例
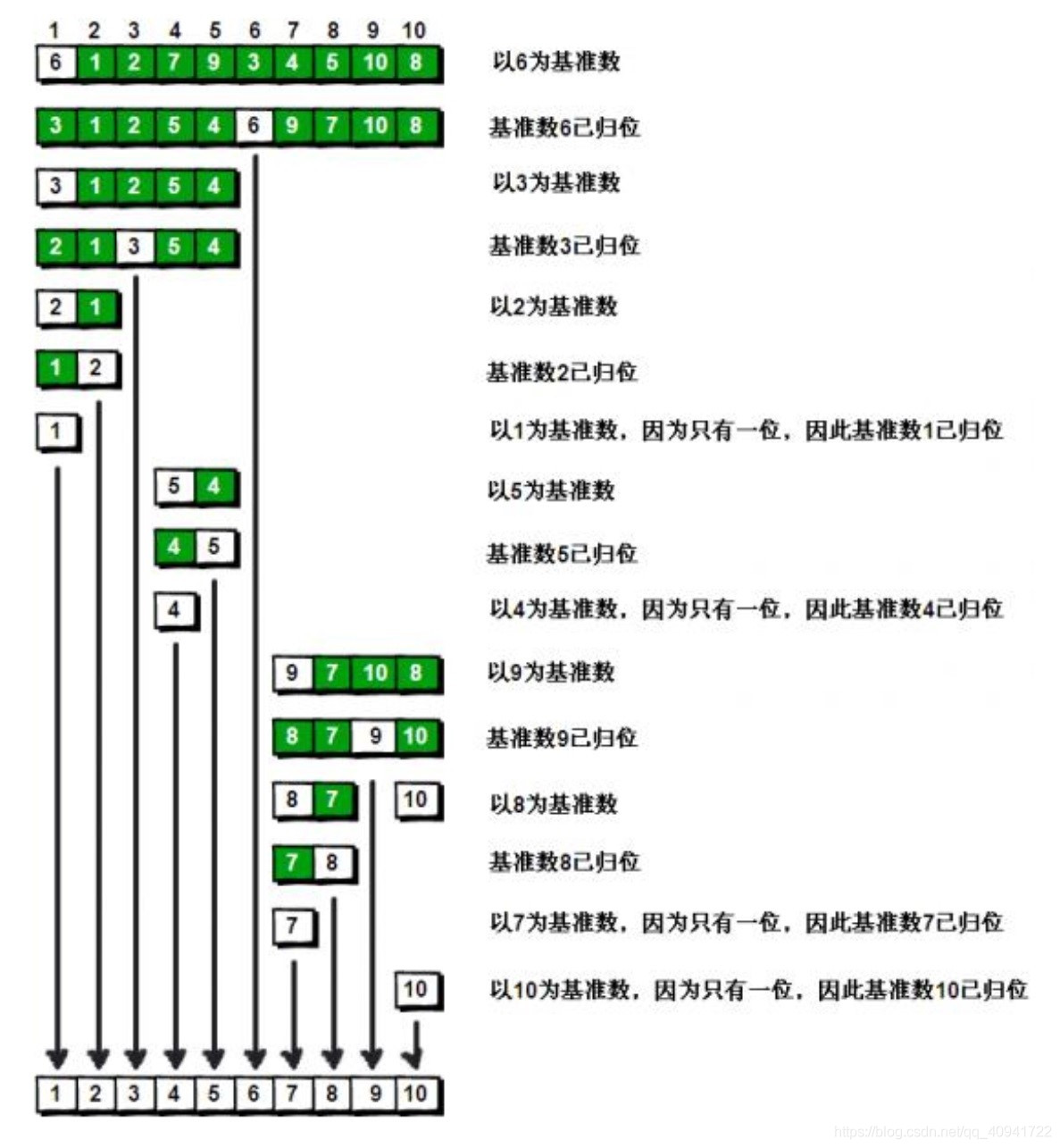
(3)C++代码
//按照从小到大排序
void quicksort(int* a, int L, int R)
{
static int count = 0;//函数调用次数计数
if (L >= R) return;
int left = L, right = R;
int pivot = a[left];
while (left < right)//控制在当轮寻找一遍
{
//先从后往前搜索
while (left < right&&a[right] >= pivot) right--;//而寻找结束的条件就是,找到一个大于或者小于pivot的数(大于或小于取决于你想升序还是降序)
swap(a,left,right);
//再从前往后搜索
while (left < right&&a[left] <= pivot) left++;
swap(a, left, right);
}
/*打印每轮排序结果*/
printarray(a, 10, count);
count++;
//**************//
a[left] = pivot;//当left == right时,一趟快速排序就完成了,当轮内找完一遍后就把中间数pivot回归
//此时小于left的数顺序尚未完全归位,但是一定小于left右边的数,所以接下来对[L,left-1]和[left+1,R]分别排序就行了。不用再考虑每轮排序结束时的pivot点。
quicksort(a, L, left - 1);//最后用同样的方式对分出来的左边的小组进行同上的做法
quicksort(a, left + 1, R);//用同样的方式对分出来的右边的小组进行同上的做法,当然最后可能会出现很多分左右,直到每一组的i = j 为止
}
main函数–测试函数
#include <iostream>
using namespace std;
void quicksort(int* a, int L, int R);//左右指针法
void printarray(int* b, int n, int count);//打印排序数组
void printa(int* b, int n);//打印数组a
void swap(int* a, int left,int right);//交换数组的两个元素
int main()
{
//int a[7] = { 2,3,1,0,4,5,6 };
int a[10] = {
6,1,2,7,9,3,4,5,10,8 };
cout << "打印排序前的数组a:";
printa(a, sizeof(a) / sizeof(a[0]));
quicksort(a, 0, sizeof(a) / sizeof(a[0]) - 1);//调用排序函数
cout << "打印排序完毕的数组a:";
printa(a, sizeof(a) / sizeof(a[0]));
return 0;
}
void printarray(int* b, int n, int count)
{
cout << "第" << count << "轮排序:\t";
for (int i = 0; i < n; i++)
{
cout << b[i] << " ";
}
cout << endl << endl;
}
void printa(int* b, int n)
{
for (int i = 0; i < n; i++)
{
cout << b[i] << " ";
}
cout << endl;
}
void swap(int* a, int left, int right)
{
int temp = a[left];
a[left] = a[right];
a[right] = temp;
}
测试结果


(4)性能分析
稳定性:很容易举一个例子,假设数组所有元素都相同,还是会发生交换的,所以是不稳定的交换算法。
平均时间复杂度:O(n(log(n)))
5.挖坑法
挖坑是快排的一种改进,避免多次调用swap函数。
(1)具体算法步骤
设要排序的数组是a[0]……a[N-1]
1)首先任意选取一个数据(通常选用数组的第一个数)作为关键数据(pivot),也是初始的坑位。
2)设置两个变量left = 0;right = N - 1;
3)从left一直向后走,直到找到一个大于pivot的值,然后将该数放入坑中,坑位变成了a[left]。
4)right一直向前走,直到找到一个小于pivot的值,然后将该数放入坑中,坑位变成了a[right]。
5)重复3和4的步骤,直到left和right相遇,然后将pivot放入最后一个坑位。
(2)举例

(3)C++代码
void quicksort1(int* a, int L, int R)//挖坑法
{
if (L >= R) return;
static int count = 0;//记录递归次数,排序轮数
int left = L, right = R;
int pivot = a[left];
while (left < right)
{
//先从后往前搜索
while (left < right&&a[right] >= pivot) right--;
a[left] = a[right];//找到比pivot小的数,交换到前面去
//再从前往后搜索
while (left < right&&a[left] <= pivot) left++;
a[right] = a[left];//找到比pivot大的数,交换到后面去
}
a[left] = pivot;
/*打印每轮排序结果*/
printarray(a, 10, count);
count++;
//**************//
quicksort1(a, L, left - 1);
quicksort1(a,left+1,R);
}
测试结果

前后指针法。。。
参考:https://blog.csdn.net/qq_36528114/article/details/78667034