1、主要思路:
- 把producer配置信息进行封装
- 使用LineNumberReader获取文件总行数和对应行的起始字节位置,并存入map里,方便不同线程从不同行读取和写入kafka
- 继承Thread类,重写run方法并执行
2、实现步骤
2.1、消息接口 Dbinfo
- kafka消息对象 KafkaConfiguration
- Dbinfo:连接参数,需要手动传入,单独写一个类对象,包含IP,port,topic
- 其他kafka配置,放在构造器里即可
public interface Dbinfo {
//1、分别为获取IP、端口号、主题topic名
String getIp();
int getPort();
String getDbName();
Map<String,String> getOther();
}
public class KafkaConfiguration implements Dbinfo {
//2、配置参数实现类
private String ip;
private int port;
private String dbName;
@Override
public String getIp() {
return this.ip;
}
@Override
public int getPort() {
return this.port;
}
public void setIp(String ip) {
this.ip = ip;
}
public void setPort(int port) {
this.port = port;
}
public void setDbName(String dbName) {
this.dbName = dbName;
}
@Override
public String getDbName() {
return this.dbName;
}
@Override
public Map<String, String> getOther() {
return null;
}
}
- mysql
- oracle
- redis…
2.2、KafkaConnector
暴露给用户的核心方法:sendMessage(String path)
- 构造器获取连接参数和配置参数
- 使用LineNumberReader方法,计算出文件的行信息,得到总行数totalRow和【行号与行起始位置的】rowSize数组
- 链接客户端,获得主题消息的分区数
- 计算每个线程的开始字节位置和行数,并存入到HashMap里
- sendMessage方法里,开辟同主题分区数量相同的线程数量并启动
public class KafkaConnector {
//3、链接属性
private Dbinfo info;
//总行数
private int totalRow=0;
//每行的尺寸
private List<Long> rowSize = new ArrayList<>();
//配置属性
Properties prop = new Properties();
/**
* info为用户端输入的参数,其他的此处在初始化里默认,也可以在作为参数让用户设置
* @param info
*/
public KafkaConnector(Dbinfo info){
this.info = info;
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,info.getIp()+":"+info.getPort());
prop.put(ProducerConfig.ACKS_CONFIG,"all");
prop.put(ProducerConfig.RETRIES_CONFIG,"0");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getTypeName());
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getTypeName());
}
/**
* 9、send方法,用户调用
* @param path
* @throws FileNotFoundException
*/
public void sendMessage(String path)throws FileNotFoundException{
//获取文件信息
getFileInfo(path);
//获取分区数
int psize = getTopicPartition();
//获取每个线程的开始位置和执行行数(不是每个线程对应的分区,但可以这么理解)
Map<Long, Integer> threadParams = calcPosAndRow(psize);
int thn = 0;
//启动每个线程
for (Long key : threadParams.keySet()) {
new CustomkafkaProducer(prop,path,key,threadParams.get(key), info.getDbName(), thn+"").start();
thn++;
}
}
/**
* 6、计算每个线程的开始字节位置和行数
* @return
*/
private Map<Long,Integer> calcPosAndRow(int partitionNum){
//new一个HashMap
Map<Long,Integer> result = new HashMap<>();
//计算平均每个分区多少行
int row = totalRow/partitionNum;
//每个分区循环
for (int i = 0; i < partitionNum; i++) {
if (i==(partitionNum-1)){
//把没除尽的行放到最后一个分区
//getPos(row*i+1),对应分区的起始行行号,求出起始行第一个字符的位置,以便于线程开始读
result.put(getPos(row*i+1),row+totalRow%partitionNum);
}else {
result.put(getPos(row*i+1),row);
}
}
return result;
}
/**
* 6.1、输入行号,返回这一行的起始字节位置
* @param row
* @return
*/
private Long getPos(int row){
return rowSize.get(row-1)+row-1;
}
/**
* 5、获取分区信息
* @return
*/
private int getTopicPartition(){
//链接客户端
AdminClient client = KafkaAdminClient.create(prop);
//获取对应的topic详细信息
DescribeTopicsResult result = client.describeTopics(Arrays.asList(info.getDbName()));
//获取所有的信息,是一个Map结构
KafkaFuture<Map<String, TopicDescription>> kf = result.all();
//获取分区数量
int num = 0;
try {
num = kf.get().get(info.getDbName()).partitions().size();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return num;
}
/**
* 4、计算出文件的行信息,得到总行数totalRow和【行号与行起始位置的】rowSize数组
* @param path
* @throws FileNotFoundException
*/
private void getFileInfo(String path) throws FileNotFoundException {
LineNumberReader reader = new LineNumberReader(new FileReader(path));
try {
String str = null;
int total=0;
while ((str=reader.readLine())!=null){
//每一行的长度为实际长度+1个换行符,而total+=则代表读到这一行时,这一行的开头在全文里是第几个字符
total+=str.getBytes().length+1;
//把total(每一行的起始位置)放在list里,对应的下标则为其对应第几行的位置
rowSize.add(((long) total));
}
//算出读的总行数
totalRow = reader.getLineNumber();
//把00添加到首位
rowSize.add(0,0L);
} catch (IOException e) {
e.printStackTrace();
}
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.3、CustomkafkaProducer
继承Thread类,需要在配置信息里添加分区器信息
- 构造器,需要再获取线程名字作为key
- 每一条线程对应的位置
- 读数据
- 写进kafka
public class CustomkafkaProducer extends Thread{
private Properties prop;
private String path;
private long pos;
private int rows;
private String topic;
/**
* 9、构造器还缺一个县城名字
* @param prop
* @param path
* @param pos
* @param rows
* @param topic
* @param threadname
*/
public CustomkafkaProducer(Properties prop, String path, long pos, int rows, String topic,String threadname) {
this.prop = prop;
this.path = path;
this.pos = pos;
this.rows = rows;
this.topic = topic;
this.setName(threadname);
}
/**
* 8、线程执行,缺啥就加啥属性,可以通过构造器传
*/
@Override
public void run() {
prop.put("partitioner.class",SimplePartitioner.class.getTypeName());
//创建producer对象
KafkaProducer producer = new KafkaProducer(prop);
try {
RandomAccessFile raf = new RandomAccessFile(new File(path),"r");
//移位置
raf.seek(pos);
for (int i = 0; i < rows; i++) {
//读数据
String ln = new String(raf.readLine().getBytes(StandardCharsets.UTF_8));
//读完写进kafka里,用线程名字当key
ProducerRecord pr = new ProducerRecord(topic, Thread.currentThread().getName(), ln);
producer.send(pr);
}
producer.close();
raf.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.4、测试类App
public static void main( String[] args ) throws FileNotFoundException {
//10、测试
KafkaConfiguration kc = new KafkaConfiguration();
kc.setDbName("mydemo5");
kc.setIp("single");
kc.setPort(9092);
new KafkaConnector(kc).sendMessage("本地路径");
}
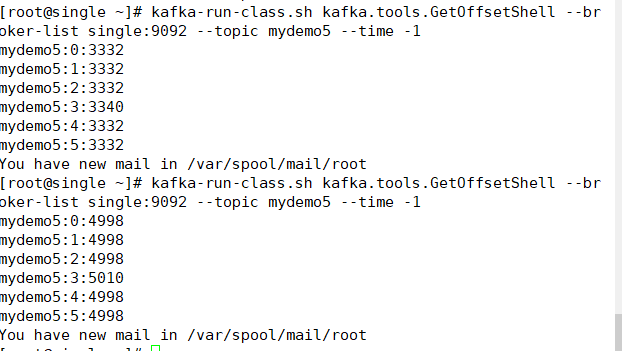
输出如下:可以看到执行后的一万条数据已经通过多线程写进kafka每个分区里