pandas库中累积计算统计特征函数:
1、cumsum()
依次给出前1,2,…,n个数的和
2、cumprod()
依次给出前1,2,…,n个数的积
3、cummax()
依次给出前1,2,…,n个数的最大值
4、cummin()
依次给出前1,2,…,n个数的最小值
注意:
cum系列函数是作为DataFrame或series对象的方法而出现的
命名格式:D.cumsm()
pandas库中滚动计算统计特征函数:
1、rolling_sum()
计算数据样本的总和(按列计算)
2、rolling_mean()
计算数据样本的算数平均数
3、rolling_var()
计算数据样本的方差
4、rolling_std()
计算数据样本的标准差
5、rolling_corr()
计算数据样本的spearman(Pearson)相关系数矩阵
6、rolling_cov()
计算数据样本的协方差矩阵
7、rolling_skew()
计算样本值的偏度(三阶矩)
8、rolling_kurt()
计算样本值的峰度(四阶矩)
注意:
rolling_系列函数是pandas函数,不是DataFrame或series对象的方法,因此,rolling_系列函数的使用格式是:pd.rolling_mean(D.k) 即每k列计算一次均值。
实例:
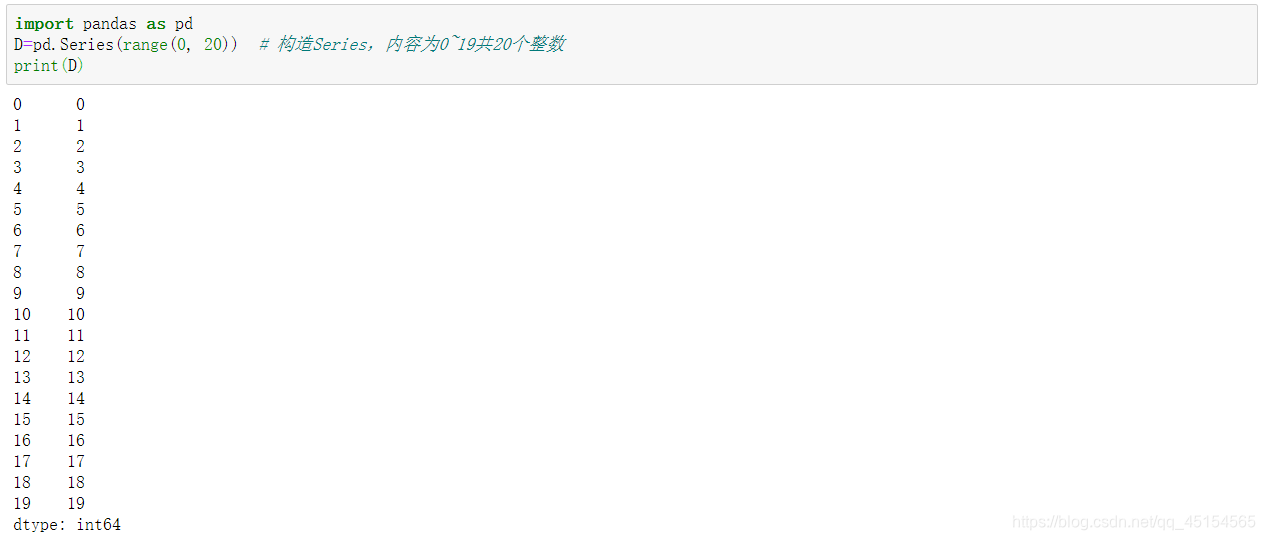
import pandas as pd
D=pd.Series(range(0, 20)) # 构造Series,内容为0~19共20个整数
print(D)
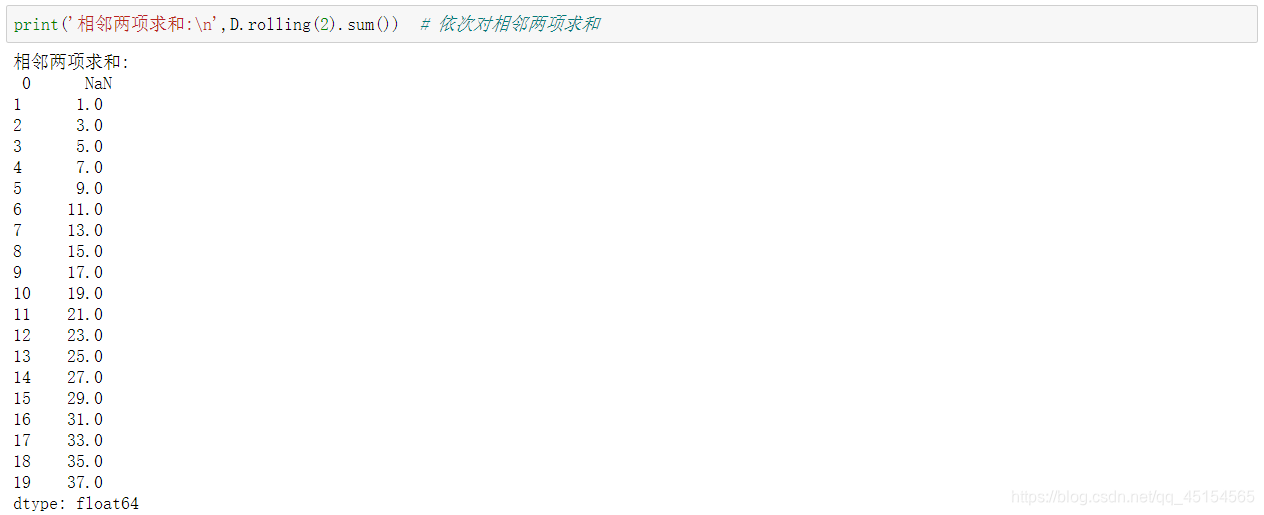
print('前n项和:\n',D.cumsum()) # 给出前n项和

print('相邻两项求和:\n',D.rolling(2).sum()) # 依次对相邻两项求和