数据库索引
1. 索引类型
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
1.1 单列索引
一次索引只包含一个列, 一个表里可以有多个单列索引
-
主键索引
-
唯一索引
CREAT UNIQUE INDEX 索引名 ON 表名(字段名)
- 普通索引
CREAT INDEX 索引名 ON 表名(字段名)
1.2 组合索引
包含两个或两个以上的列
CREAT INDEX 索引名 ON 表名(字段A,字段B,字段C)
注: 查询时遵循mysql组合查询的 “最左前缀”,
删除语句:
DORP INDEX indexName ON TableName
1.3 聚集索引(也叫 聚簇索引、主键索引)
一个表只能拥有一个聚集索引,而且是建立在主键上面的,主键一般采用自增ID和GUID等方式。自增ID由于是有序的,而且占用字节较少。所以在性能和空间上都比较有优势。
2. 加入索引的好处和坏处
2.1 优点
- 可以通过建立唯一索引或主键索引, 保证每行数据的唯一性
- 建立索引可以大大提高检索的速度, 减少表的检索行数
- 可以加速表与表的相连速度
- 可以减少 分组( group by )/排序( order by )所消耗的时间
- 通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
2.2 缺点
- 创建索引和维护索引需要耗费时间和消耗内存
- 索引文件会占用物理空间
- 当表内进行 insert / update / delete操作时, 索引也需要动态的维护, 所以会降低维护的效率
2.3 加入索引要注意的地方
需要考虑哪些列上需要, 哪些列上不需要
- 在常常被搜索到的列上, 加索引可以提高查询速度
- 主键列上可以确保列的唯一性
- 表和表连接的条件上加索引, 可以加快连接查询的速度
- 经常需要排序 order by / 分组 group by / 去重 distinct 加索引可以加快排序查询的时间
- 索引不包含null值
2.4 什么情况下最好加(或不加)索引?
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合建立索引,因为每次更新不单单更新了记录还会更新索引
- WHERE条件里用不到的字段不创建索引
- 单键和组合索引的选择问题,(高并发情况下适合创建组合索引)
- 查询中排序的字段,排序的字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
不适合使用索引的场合 :
9. 对经常更新的表就避免对其进行过多的索引
10. 数据量小的表最好不要使用索引,由于数据较少,可能查询全部数据时间比遍历索引的时间还要短,索引就可能不会产生优化效果
11. 在不同值少的列上不要建立索引
12.
3. 索引失效的场景和原因
3.1 场景
- 列上有计算的时候
- 非最左前缀查询
- 范围查询( >右边的会失效 )
- like位于%的右面时
- 跳过某个数据时 ( < > 时 )
- 列类型是字符串,查询条件未加引号
- 未使用该列(被索引的列)作为查询条件
- 在查询条件中使用OR ( 要想是索引生效,需要将or中的每个列都加上索引 ).
3.2 原因
此处使用一个联合索引失效的具体场景做例子
需要先了解的知识点 :
联合索引的排序 先排序第一个字段去排序, 如果第一个字段相同, 再按着第二个字段去排序…以此类推
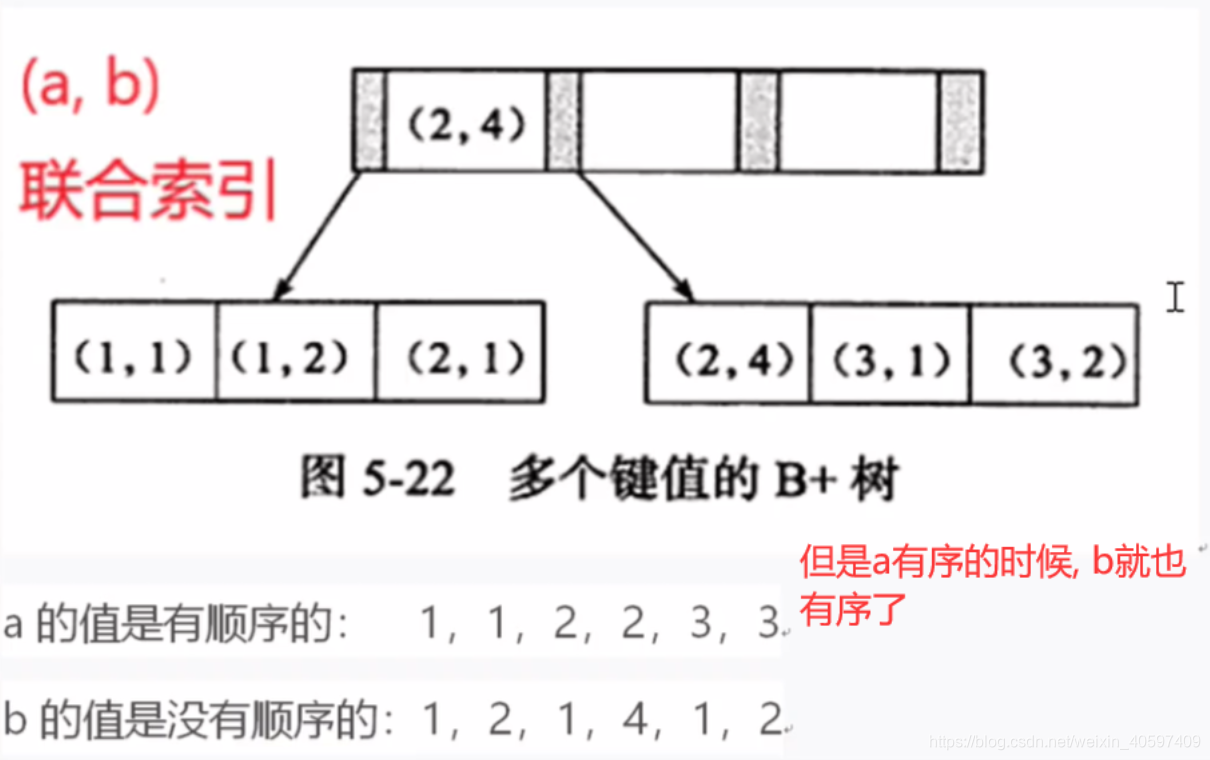
如上图可知 :
2. 最左前缀失效: 二分查找法查找的时候 前面的元素没找到 ,所以索引失败 , 参考上面知识点 [ 只有第一个元素相等的情况下 , 第二个元素才是有序的 / 反之无序 ]
3. " > "右边的会索引失效: 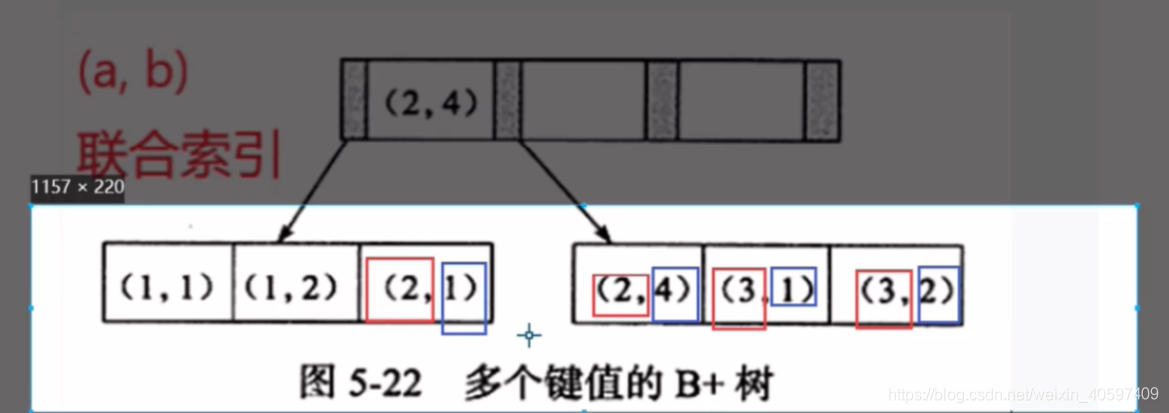
由图可知 , 根据条件 a>1得到 a=2和a=3条件, 则b元素为1,4,1,2 是无序的所以不能索引
4. like关键字中 %xx 和 %xx% 索引失效: 同上 违反了最左前缀法则
4. 索引的数据结构
此处主要讲解Mysql底层的索引数据结构: 也就是B+Tree
mysql中也有其他的数据结构, 比如hash / B树等 , 这些数据结构有个共同的问题, 是解决不掉(或者是效率极低)地进行范围查询( 要么就是多次回旋查找 )
4.1 B+tree概述
B+tree 如图所示 :
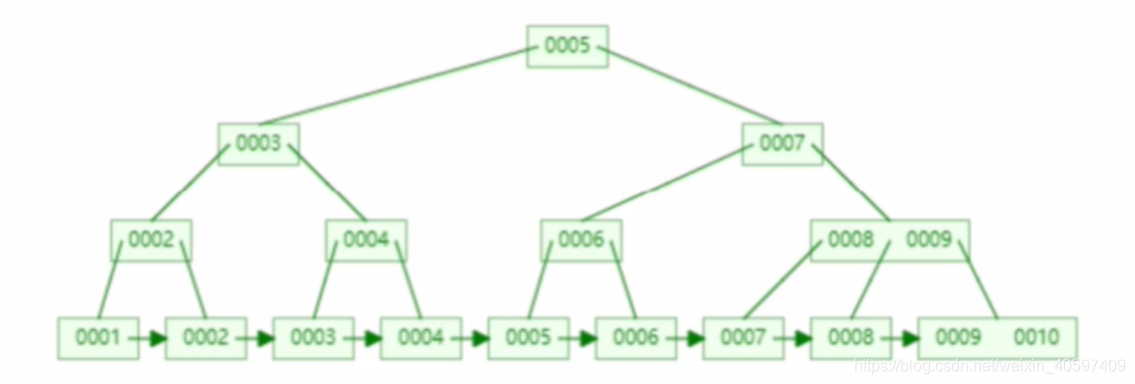
B+Tree基本概念:
- 一个结点可以存两个值
- 叶子结点层是一个单向链表
- 解决了回旋查找问题
- 上层( 非最后一次层 ) 只存储key (0001等) , 底层存储key-value( 数据-数据的地址 )
- 在范围查找的速度是非常高的
- B+树在树内形成了排序好的数据, 不需要产生排序的文件
4.2 其他索引数据结构的缺点
- 哈希查找: mysql中是无序的 哈希查找需要有序才可以查找 / 而且有概率出现哈希碰撞
- 平衡二叉树: 树的高度比较高的时候, 查询速度也会变慢 / 范围查询的时候也要往回查找
- B树: 也存在回旋查找的问题 . 所以引入了b+tree
5.底层如何通过索引找到真实数据?
5.1 mysql搜索引擎和方式
5.1.1 MyISAM
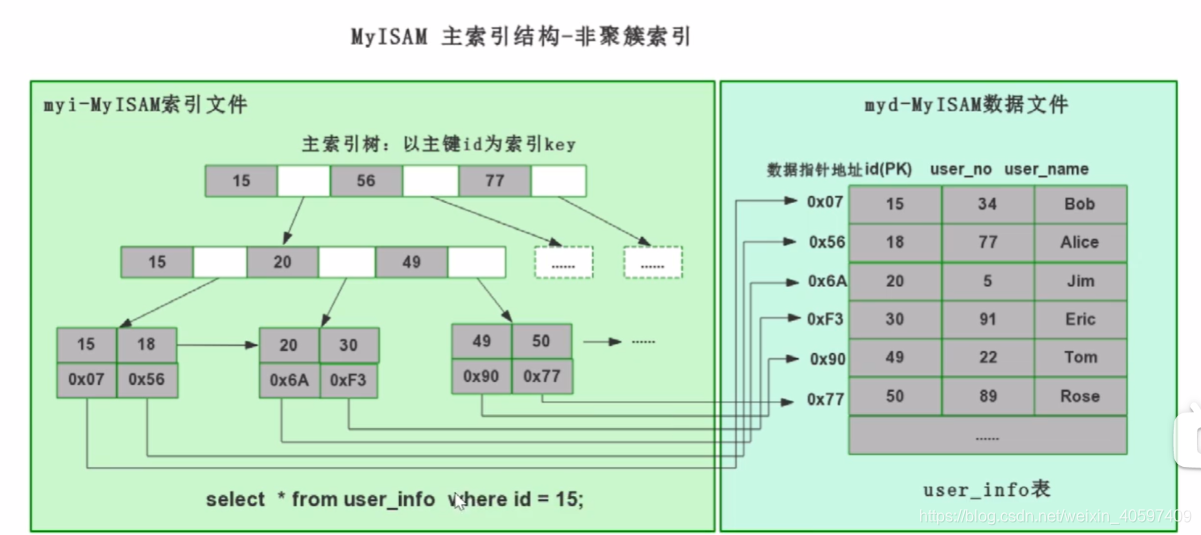
- 通过主键索引搜索到对应索引的物理地址
- 然后根据地址去查找索引的信息
5.1.2 InnoDB
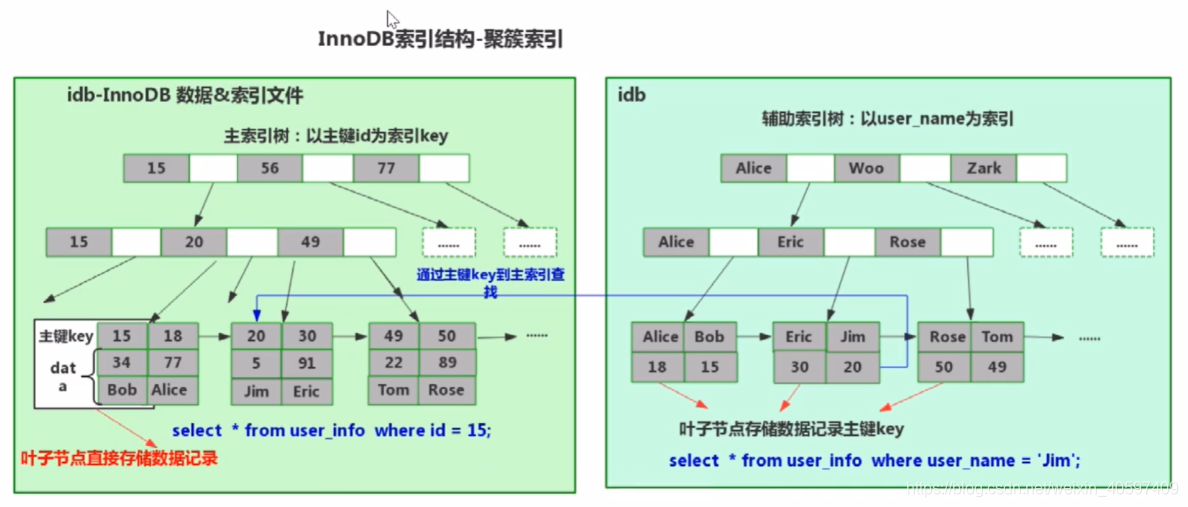
- 主索引树(实际是主键索引): 可以通过主键找到整行数据的全部信息
- 辅助索引 : 辅助索引中 假设用user_name为索引的话, 只能在最底层找到名字对应的id, 在使用id通过主键索引获取该行数据的全部信息, 即可完成查询.
总结: InnoDB中如果只一次主索引就能查到的话 ,效率一般是大于MyISAM的 ; 如果需要辅助索引查询的话, 也就是查询两次, 可能效率会低于MyISAM.
5.1.3 两者的区别
-
事务方面 : InnoDB支持事务 MyISAM不支持 [ 这是mysql将默认存储引擎从MyISAM变成InnoDB的重要原因之一 ]
-
外键方面 : InnoDB支持 MyISAM不支持, 对一个包含外键的InnoDB表转为MyISAM表会失败
-
索引方面 : InnoDB是聚簇索引, 不支持全文索引, 但是InnoDB可以使用
sphinx插件支持全文索引, 且效果非常好 ; MyISAM是非聚簇索引, 支持全文索引 . -
锁粒度方面 : InnoDB最小粒度的是行锁 ; MyISAM最小粒度是表锁. [ 这也是mysql将默认存储引擎从MyISAM变成InnoDB的重要原因之一 ]
6. 两种引擎的索引在本地存储文件的区别
硬盘存储结构 :
MyISAM : 在磁盘上分成三个文件( .frm / .MYD / .MYI )
- .frm : 存储表的定义
- .MYD: 数据文件 (MyData)
- .MYI : 索引文件(MyIndex)
InnoDB: 在磁盘分为两个文件( .Frm / .Ibd ) — 没有专门保存数据的文件
- .Frm : 表的定义
- .Ibd : 数据和索引的存储文件, 数据以主键进行聚集索引, 真正的数据存在叶子节点中( B+tree结构 )
7. 扩展
7.1 复合索引什么情况下失效(有实例)
MySql中的多列索引:
-
联合索引又叫复合索引。对于复合索引 : Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
例如索引是
key index (a,b,c)可以支持a | a,b| a,b,c3种组合进行查找,但不支持 b,c进行查找 , 当最左侧字段是常量引用时,索引就十分有效。 -
多列建索引比对每个列分别建索引更有优势,因为索引建立得越多就越占磁盘空间,在更新数据的时候速度会更慢。另外建立多列索引时,顺序也是需要注意的,应该将严格的索引放在前面,这样筛选的力度会更大,效率更高。
-
组合索引的生效原则是 : 从前往后依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用;
- 如
where a=3 and b=45 and c=5. 这种三个索引顺序使用中间没有断点全部发挥作用; where a=3 and c=5这种情况下b就是断点,a发挥了效果,c没有效果where b=3 and c=4这种情况下a就是断点,在a后面的索引都没有发挥作用,这种写法联合索引没有发挥任何效果;where b=45 and a=3 and c=5这个跟第一个一样,全部发挥作用,abc只要用上了就行,跟写的顺序无关
- 如
还需注意, (a,b,c)多列索引和 (a,c,b)是不一样的
经典例子:
select * from mytable where a=3 and b=5 and c=4;abc三个索引都在where条件里面用到了,而且都发挥了作用select * from mytable where c=4 and b=6 and a=3;这条语句列出来只想说明 mysql没有那么笨,where里面的条件顺序在查询之前会被mysql的查询优化器自动优化,效果跟上一句一样select * from mytable where a=3 and c=7;a用到索引,b没有用,所以c是没有用到索引效果的select * from mytable where a=3 and b>7 and c=3;a用到了,b也用到了,c没有用到,这个地方b是范围值,也算断点,只不过自身用到了索引select * from mytable where b=3 and c=4;因为a索引没有使用,所以这里 bc都没有用上索引效果select * from mytable where a>4 and b=7 and c=9;a用到了 b没有使用,c没有使用select * from mytable where a=3 order by b;a用到了索引,b在结果排序中也用到了索引的效果,前面说了,a下面任意一段的b是排好序的select * from mytable where a=3 order by c;a用到了索引,但是这个地方c没有发挥排序效果,因为中间断点了,使用 explain 可以看到 filesortselect * from mytable where b=3 order by a;b没有用到索引,排序中a也没有发挥索引效果
那如果我们分别在a和b上创建两个列索引,mysql的处理方式就不一样了,它会选择一个最严格的索引来进行检索,可以理解为检索能力最强的那个索引来检索,另外一个利用不上了,这样效果就不如多列索引了。
关于 in 是否能触发索引?
答 : 可能会用到索引
- IN 的条件过多,会导致索引失效,走索引扫描
- IN 的条件过多,返回的数据会很多,可能会导致应用堆内内存溢出。