说明
文章的图片来源《MySQL是怎么运行的:从根儿上理解MySQL》,本篇文章只是个人学习总结,欢迎大家买一本正版小册看看,对于mysql是由浅入深的讲解非常细致
目录
19.事务简介
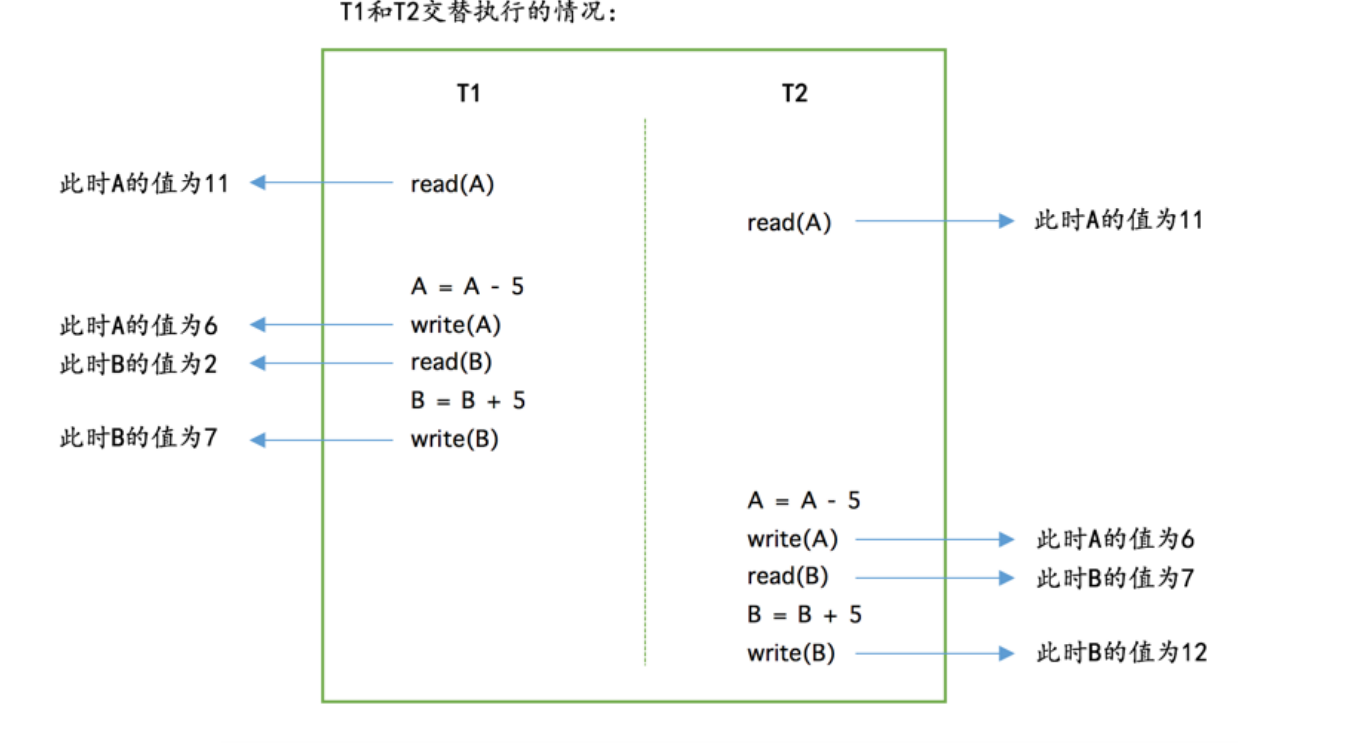
- 原子性:保证一个事务从头到尾都只有一个线程在操作
- 隔离性:两个事务之间是分开执行的
- 一致性:加入多种约束,这种约束通常是业务程序员进行保证。比如我有100块给了小明40块,那么最后小明不可能拥有50块吧。我也不可能还拥有70块,最后我只有60,小明有40。而且我们两个之间的和还是100.数据符合约束那么就是数据一致性
- 持久性:做了修改的数据不应该被撤销。而是在磁盘保存下来
事务的概念
- 保证上面的4种特性的一个或者多个数据库操作称为事务
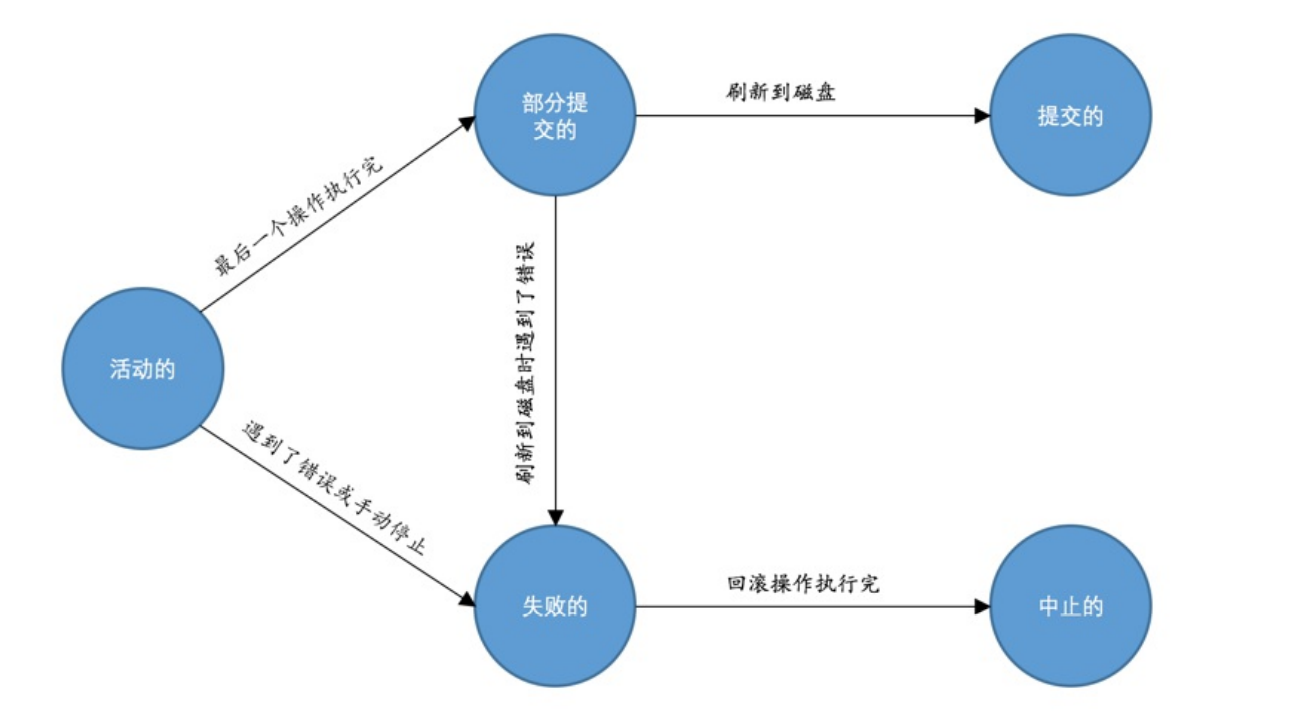
事务的状态
- 活动的:事务操作正在执行
- 部分提交的:事务在内存中处理最后一个执行操作没有刷新到磁盘这种就是半提交活动状态
- 失败的:事务被终止执行
- 中止的:撤销了之前事务失败的前面的几个操作之后就是中止状态
- 提交的:把事务处理完的数据更新到磁盘
只有事务到中止或者是提交那么事务的生命周期才算是结束
开启事务
- BEGIN [WORK];可以写若干操作语句,代表开启了一个事务
- START TRANSACTION;跟begin一样,但是可以加上修饰符
- READ ONLY:只读事务
- READ WRITE:读写事务
- WITH CONSISTENT SNAPSHOT:一致性读
提交事务
- COMMIT [WORK]
手动中止事务
- ROLLBACK [WORK]手动回滚事务。
支持事务的存储引擎
- Innodb
- NDB
自动提交
- autocommit如果是on那么就是自动提交,off就是手动提交
隐式提交
- 定义或者修改数据库对象的时候DDL
- 隐式修改表的结构
- 事务控制和锁定语句
- 加载数据的语句
LOAD DATA
- mysql复制的语句
START SLAVE、STOP SLAVE、RESET SLAVE、CHANGE MASTER TO
- 其它一些语句
保存点
- 主要就是用于回滚的时候不是回滚整个事务,而是回滚到指定的点
- SAVEPOINT 保存点名称;+ROLLBACK [WORK] TO [SAVEPOINT]
20.redo日志(上)
为了保证提交事务之后能够修改成功,只要修改就把对应页刷新到磁盘,问题是
- 刷新完整的页非常浪费
- 随机IO刷新起来非常慢,这些更新页面并不是连续的
目标?提交的事务生效,而且系统崩溃之后可以重启把这种修改恢复过来。
- 解决方案就是把这种修改了哪些东西记录一下
- 记录这些的就是redo log重做日志,可以满足事务提交之后的持久性
- redo log占用空间很小
- redo log是顺序写入磁盘,一条语句可能就会生成多个日志,按照产生顺序写入
redo日志格式

- type:日志类型
- space id:表空间id
- page number:页号
- data:该条日志的具体内容。
简单的redo日志类型
- 使用row_id作为主键,其实就是一个全局变量赋值给row_id并且自增
- 变量到达256倍数之后就会刷新到7页号的max row id处
- Max Row ID加载进内存,并且加上256后赋值给全局变量
事务如果给某个包含row_id列的表插入记录,而且刚好全局变量自增到256的倍数,就会向系统7号页偏移量写入8个字节的值,它在buffer pool中完成,并且记录一条redo日志。记录哪个页面,在哪个偏移量干了什么事,这种redo log也可以说是物理日志,写入多少数据来进行划分的日志类型
- MLOG_1BYTE:某个页面某个偏移量处写入1个字节的redo log
- MLOG_2BYTE:同理两个字节
- MLOG_4BYTE
- MLOG_8BYTE
- MLOG_WRITE_STRING:在某个页面某个偏移量写入一串数据
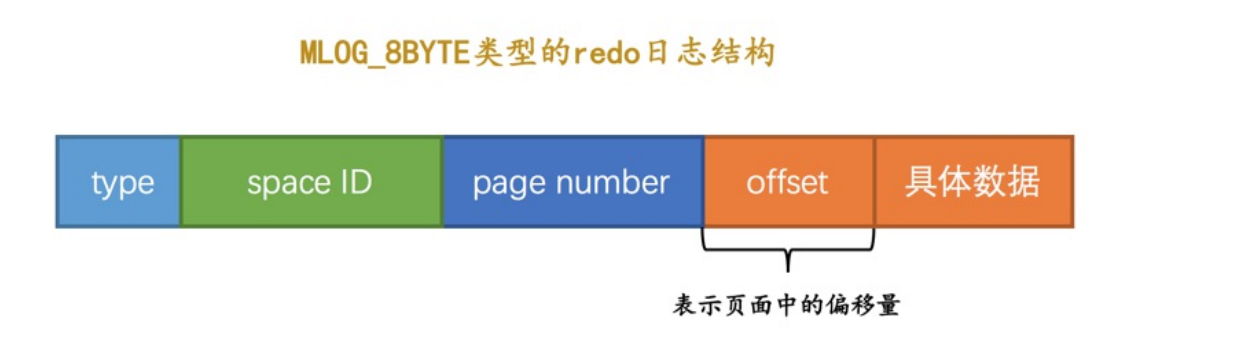
- 上面这种就是记录8个字节的Max Row ID的8byte redo日志
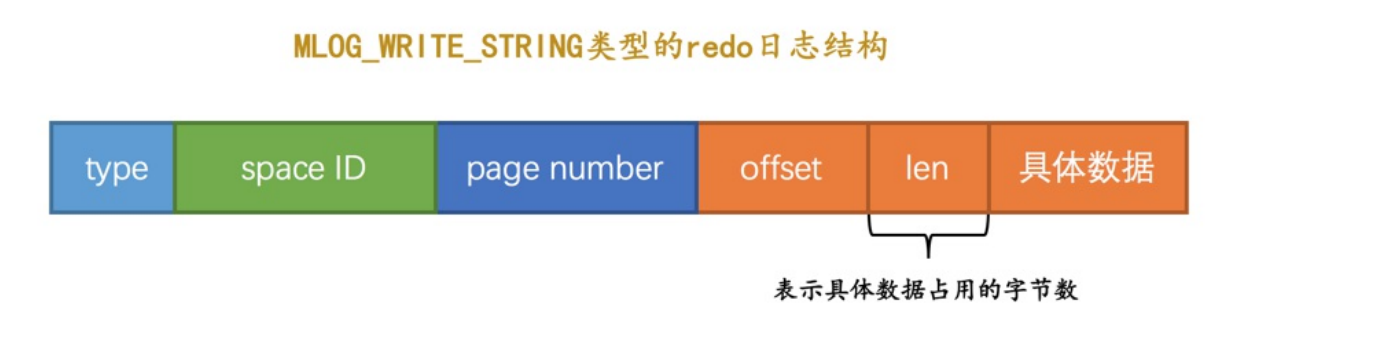
- 对于写入一串数据,无法知道字节长度所以需要有一个len。
复杂一些的redo日志类型
- 表多少个索引,insert需要更新多少b+树
- b+可能更新叶子节点、内节点、或者是创建新的页面
更新节点不仅仅只是添加了什么数据,还有file header、page header、page directory
- 可能更新page directory的槽信息
- page header的各个页统计信息,PAGE_N_DIR_SLOTS槽数量,PAGE_HEAP_TOP还未使用的空间最小地址,PAGE_N_HEAP页面有多少记录数
- 记录单向链表的next_record
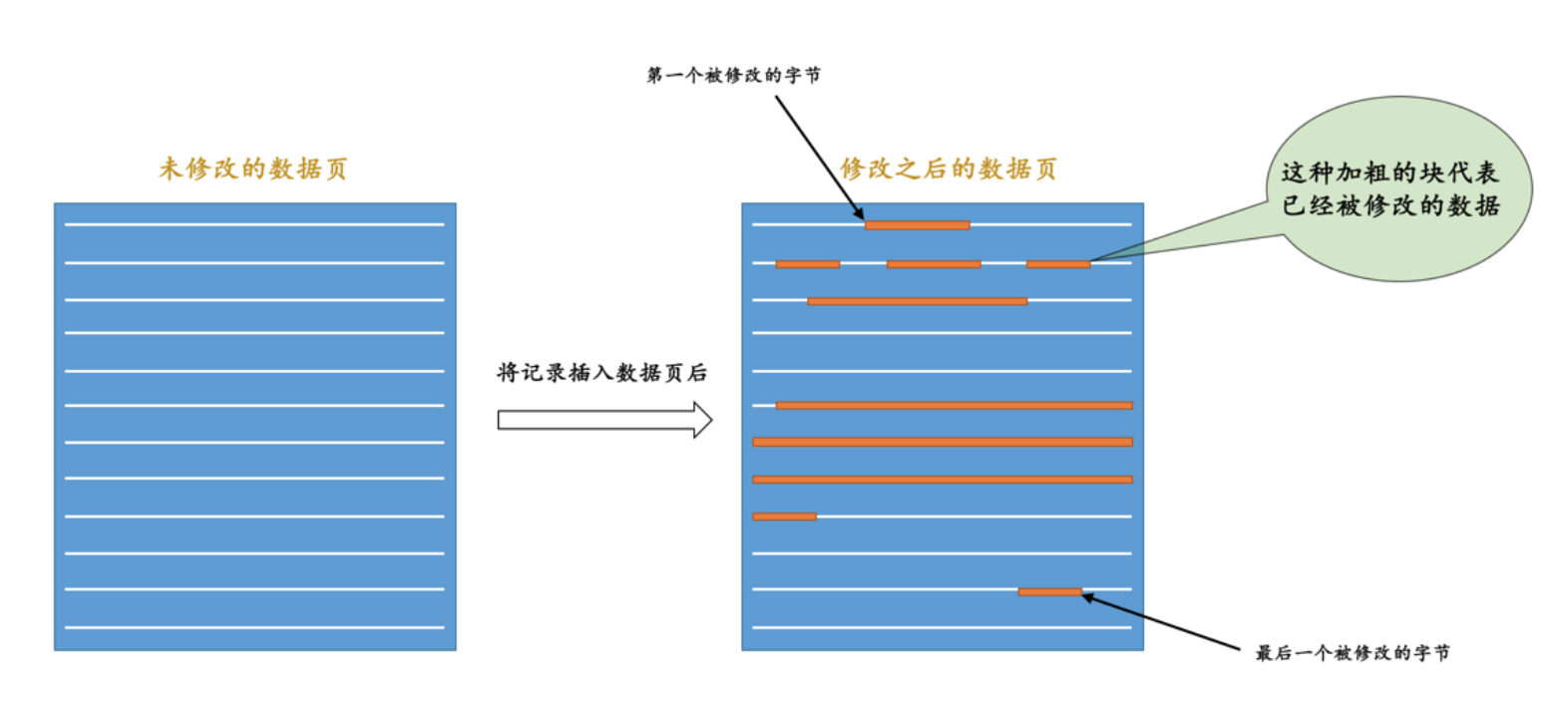
记录的到redo log的方案
- 方案1:每个修改的地方都加上一条redo log,问题是占用空间太大
- 方案2:把第一个被修改的字节到最后一个都记录下来,问题就是很多没有修改的也被记录了
所以需要新的redo log日志类型
- MLOG_REC_INSERT(9):插入一条非紧凑行格式的redo日志
- MLOG_COMP_REC_INSERT(38):插入一条紧凑行格式的日志

- 这些日志包含物理+逻辑层面的意思
- 物理层改变了哪个表空间,哪个页,哪个偏移
- 逻辑不能直接根据记录哪个偏移来恢复,而是需要函数,执行函数之后才能恢复
MLOG_COMP_REC_INSERT的日志结构

- n_uniques:能够让记录保持唯一的多个列,或者是一个主键列,这样就能够进行排序。这里指的是让记录保持唯一需要多少个列
- field1_len ~ fieldn_len:字段占用空间的大小。
- offset:前一条记录,每次修改的时候都需要修改前一条记录的一个next_record。因为页里面的记录是通过链表的形式串联起来的
- end_seg_len:为了减少redo log的占用空间
- mismatch_index:也是为了节省redo log的空间
- 这些参数其实只是记录的重要部分,redo log知道这些参数就可以通过函数计算出其他的PAGE_N_DIR_SLOTS、PAGE_HEAP_TOP、PAGE_N_HEAP等的值
redo日志格式小结
- 目的:就是为了节省redo日志空间,而且能够通过redo log来恢复那些因为故障没有执行成功的事务的操作修改
Mini-Transaction
以组的形式写入redo日志
- 更新Max Row ID产生的redo日志是不可以分割的
- 向聚簇索引B+树插入一条记录产生的redo日志不可分割
- 向二级索引的B+树插入记录产生的redo日志也是不可以分割的
- 对其他页面的访问操作也是和redo日志不可以分割
插入一条数据到B+树为例解释不可分割
- 情况1:数据页空间充足可以直接插入,并且记录MLOG_COMP_REC_INSERT到redo log,这种就是乐观插入
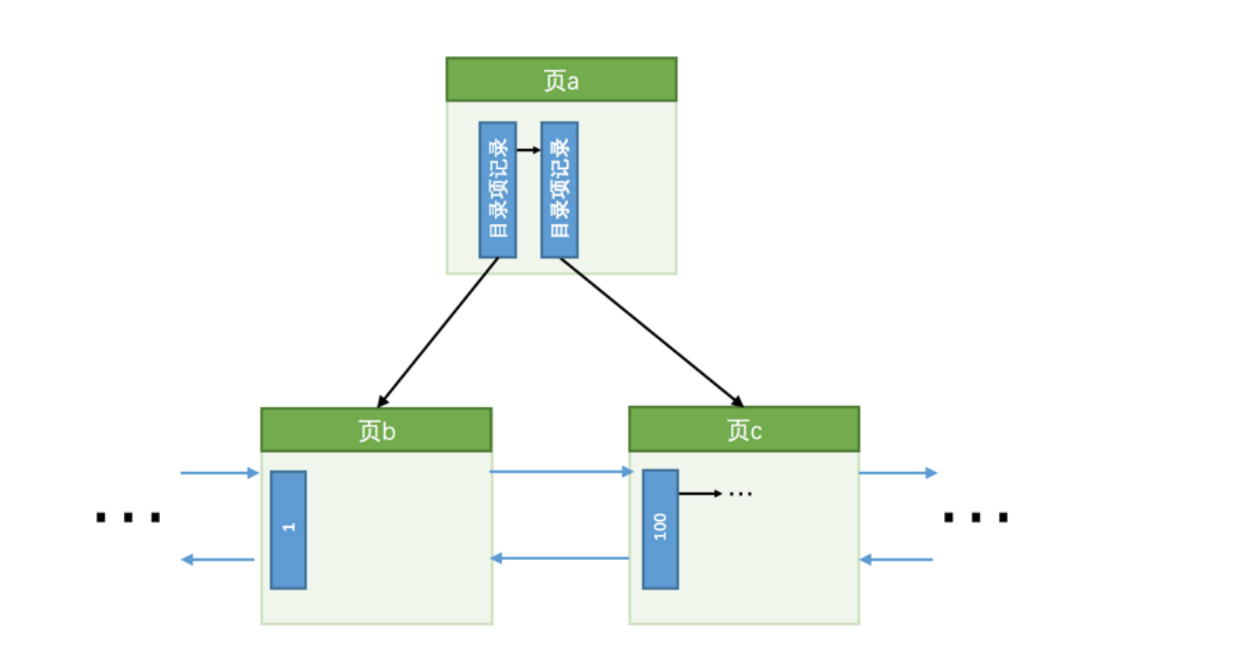
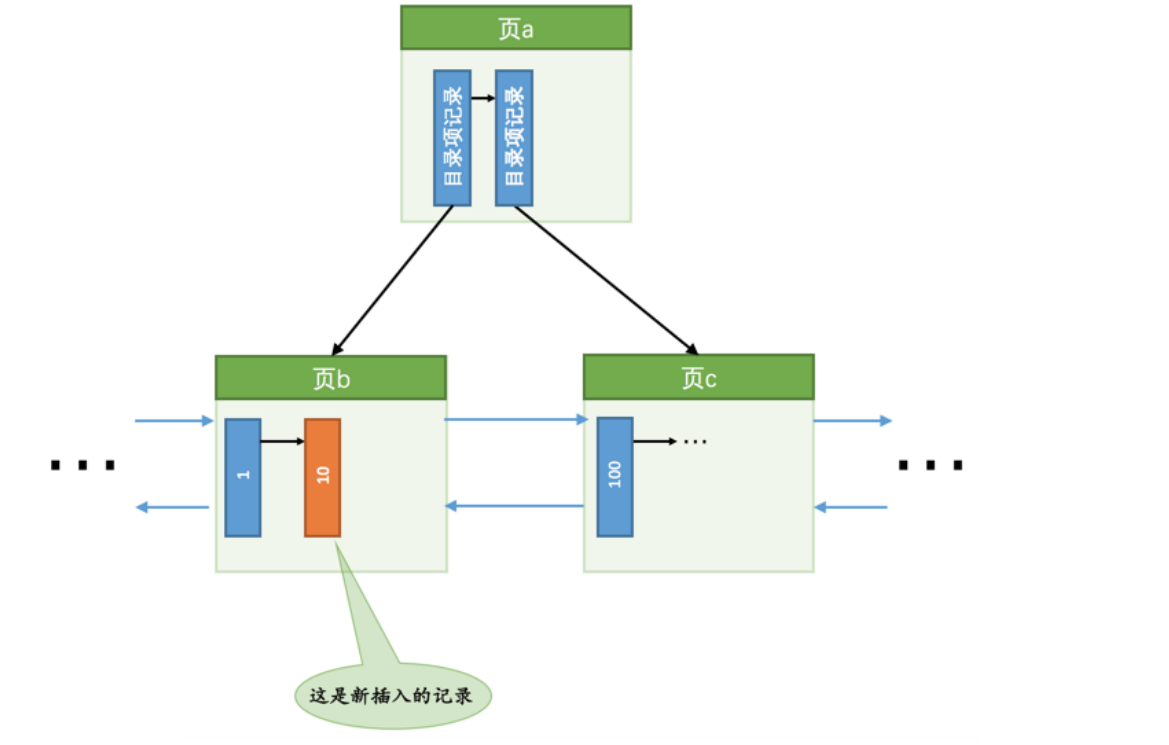
- 情况2:如果这条数据插入的数据页刚好就是已经满了,那么这种就需要进行页分裂操作,这种分裂操作,需要创建新的页,搬运一部分记录过去,并且还需要在内节点连接上新创建的页,一下子需要插入多条redo日志,这种就是悲观插入
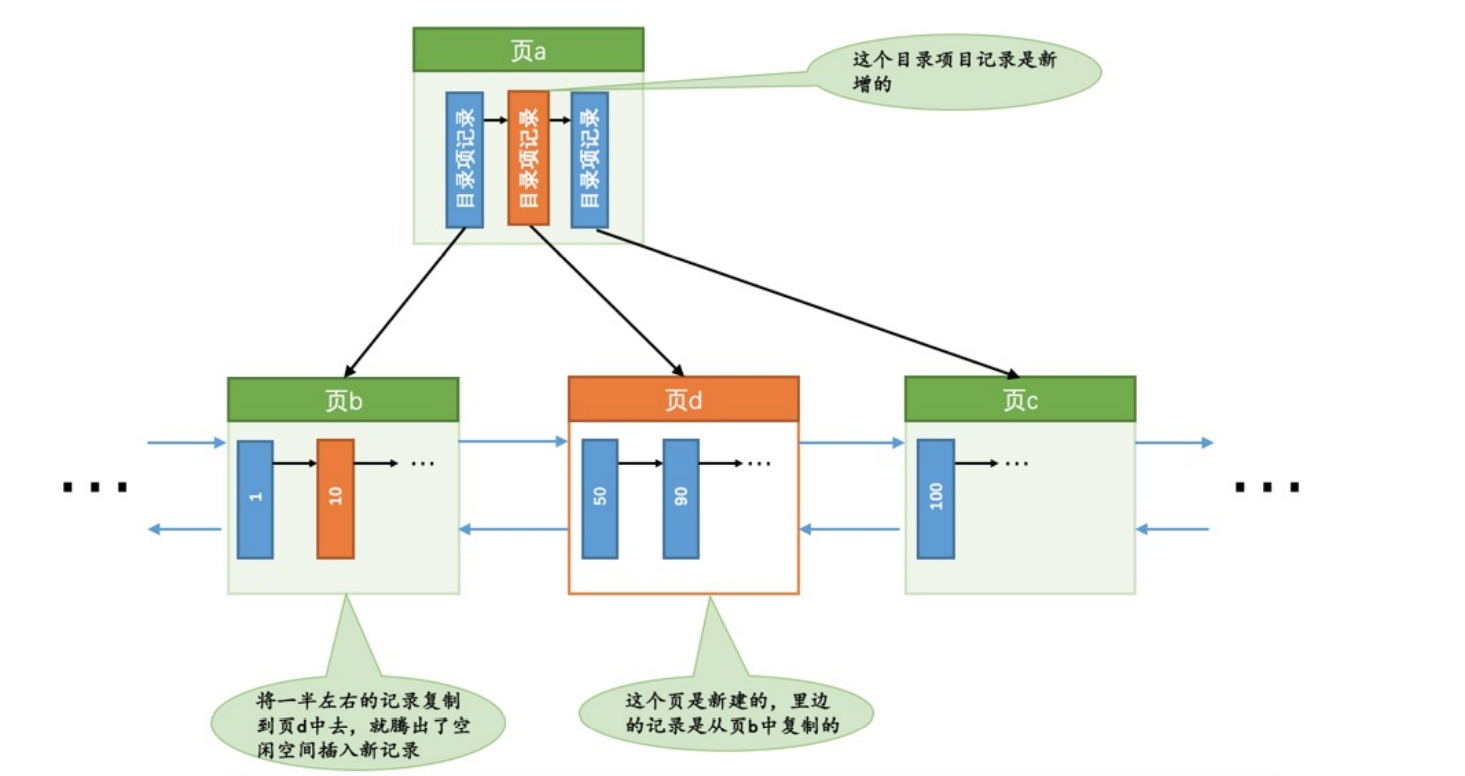
插入一条记录到B+树的过程是一个原子操作,redo log目的是在系统崩溃的时候进行恢复,但是如果悲观插入只插入了一部分,那么redo log也只记录一部分,导致最后恢复也是错的。所以需要用组的方式来记录redo 日志,在系统崩溃的时候对于某个组来说要么就不恢复,要么就全部都恢复
- 情况1:有的原子操作生成多条redo log日志,如何进行划分组?在每个日志组后面加上MLOG_MULTI_REC_END,type字段是十进制的31

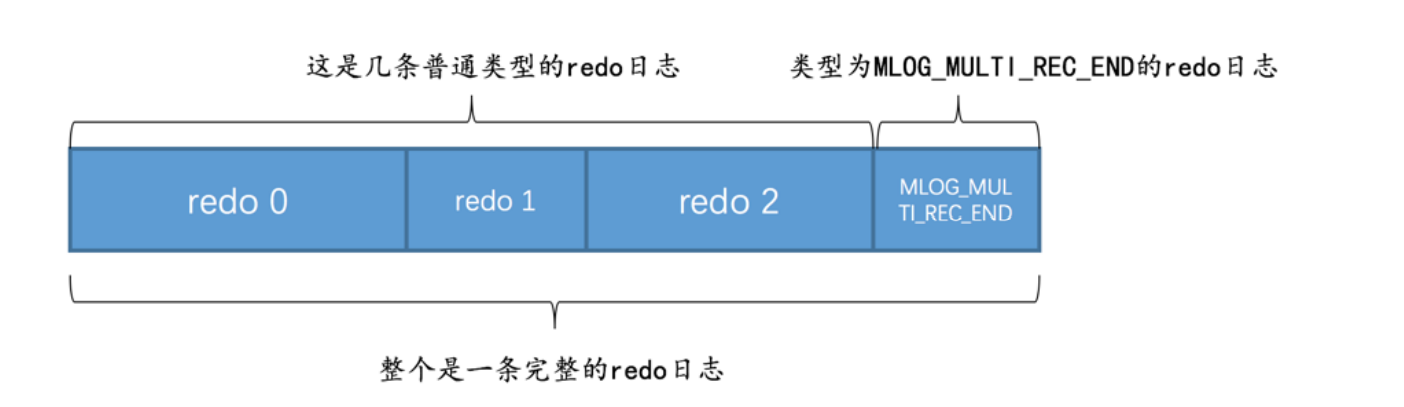
- 那么系统恢复需要解析到最后的那个MLOG_MULTI_REC_END那么才会认为这个组是完整的。可以进行恢复,不然就会放弃解析前面的数据
- 情况2:有的原子操作只会生成一条redo log。这里会使用1个bit来标识是不是单一log,并且7个bit来作为MLOG_MULTI_REC_END作为日志组的结尾日志。
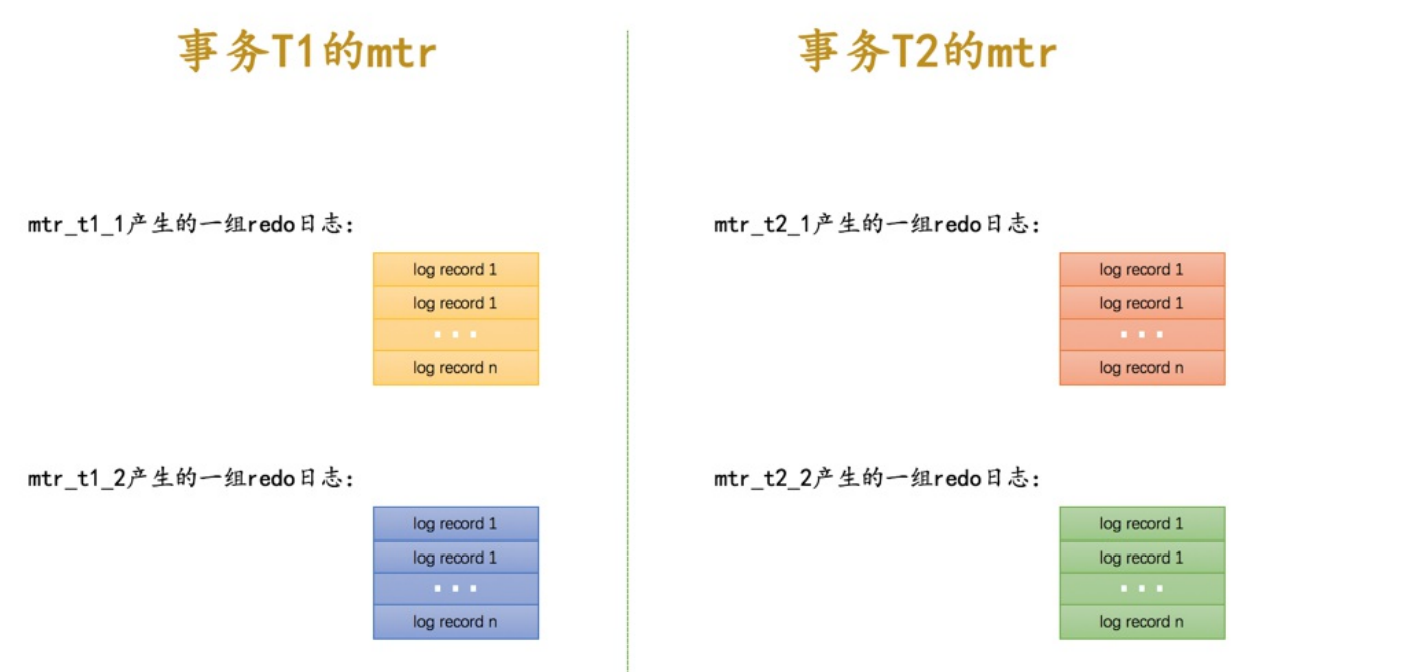
Mini-Transaction的概念
- 对底层页面的一次原子访问操作就是一个mini-transaction,一个事务包含多个语句,每个语句都是一个mtr(mini-transaction),mtr里面又包含了若干条redo日志
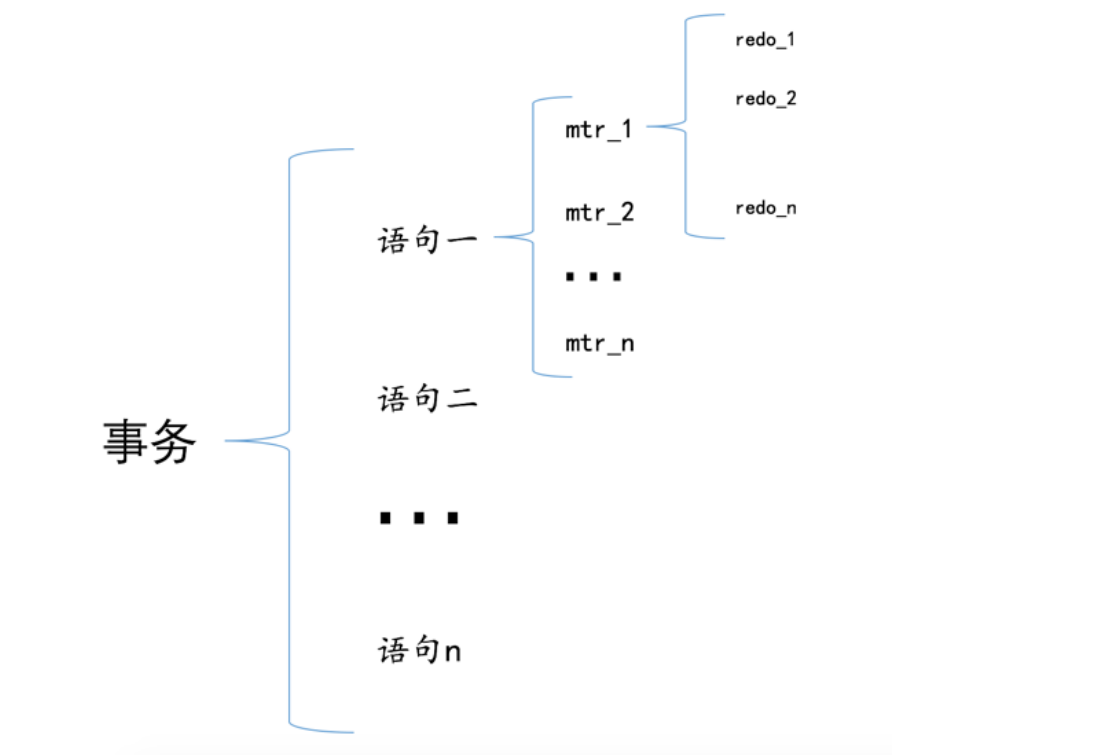
redo日志的写入过程
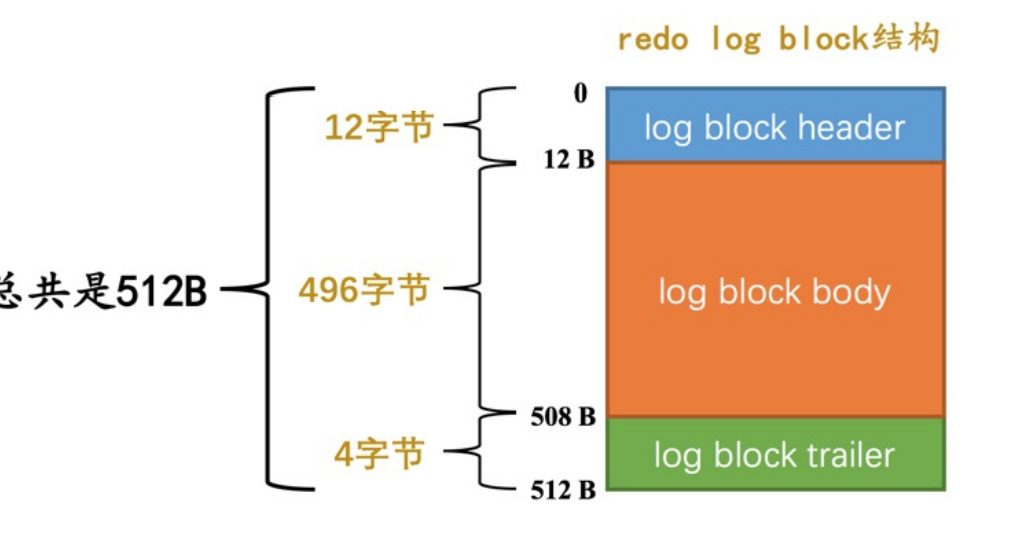
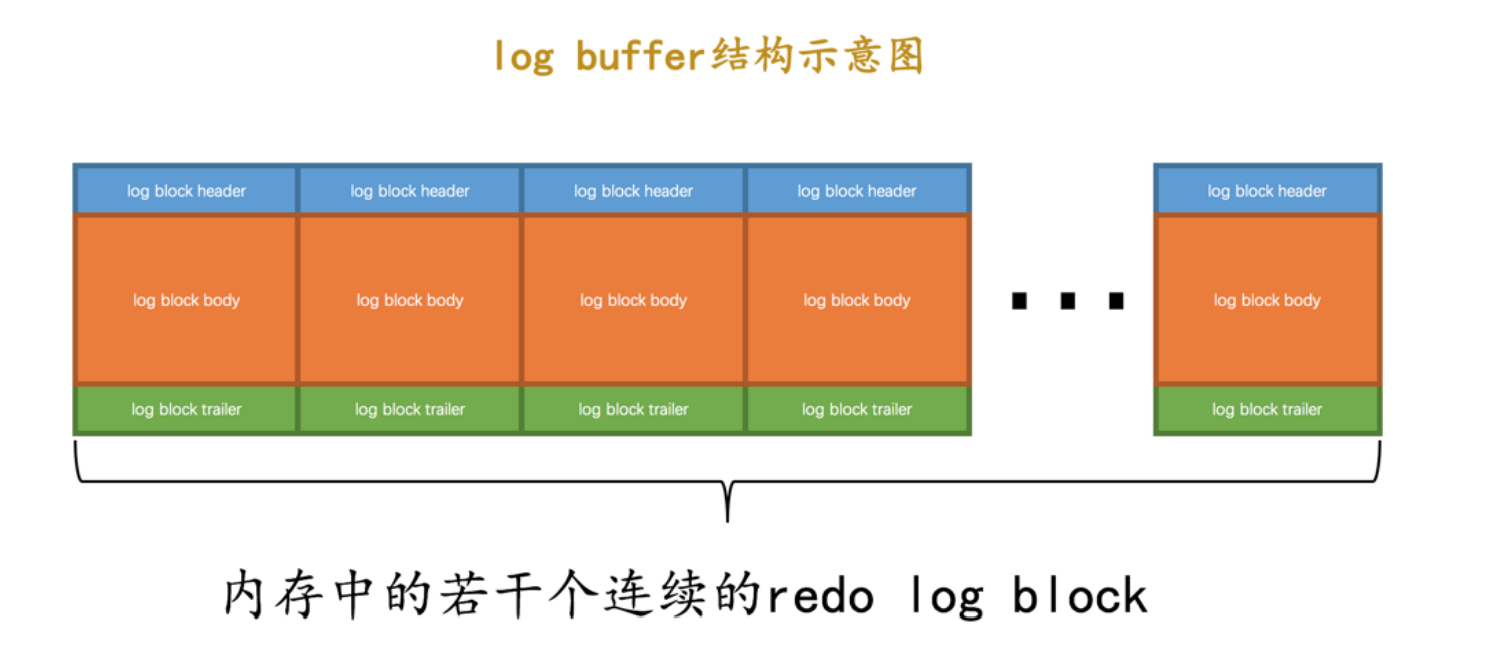
redo log block
- mtr生成的redo日志放到512字节的页上面,这种页叫做block
- 两部分管理信息header和tailer,其它496个字节都是日志实体内容
log block header
- LOG_BLOCK_HDR_NO:每个block的标号值
- LOG_BLOCK_HDR_DATA_LEN:表示block已经使用了多少个字节
- LOG_BLOCK_FIRST_REC_GROUP:第一个mtr生成的redo日志组的偏移量
- LOG_BLOCK_CHECKPOINT_NO:checkpoint序号
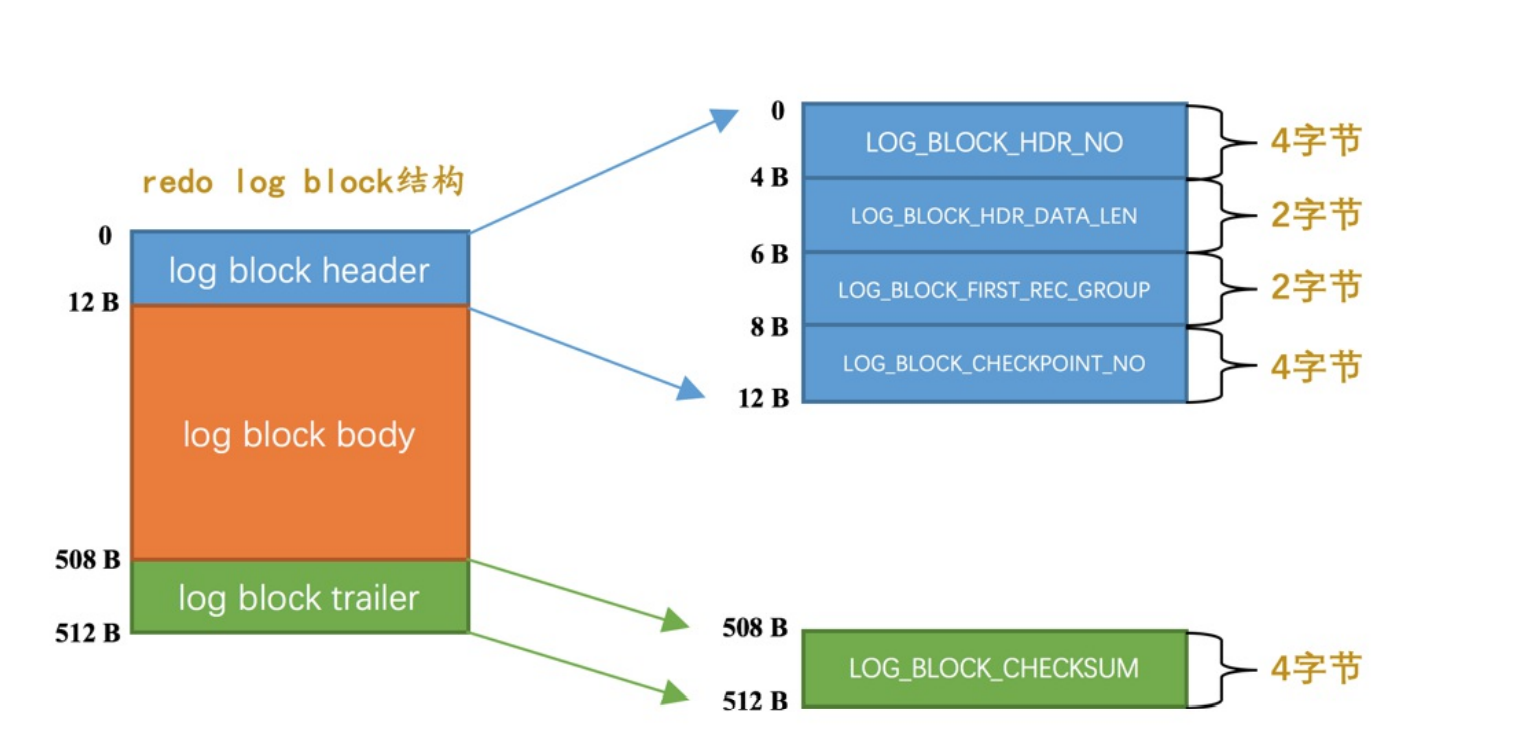
log block trailer
- LOG_BLOCK_CHECKSUM:block的校验值
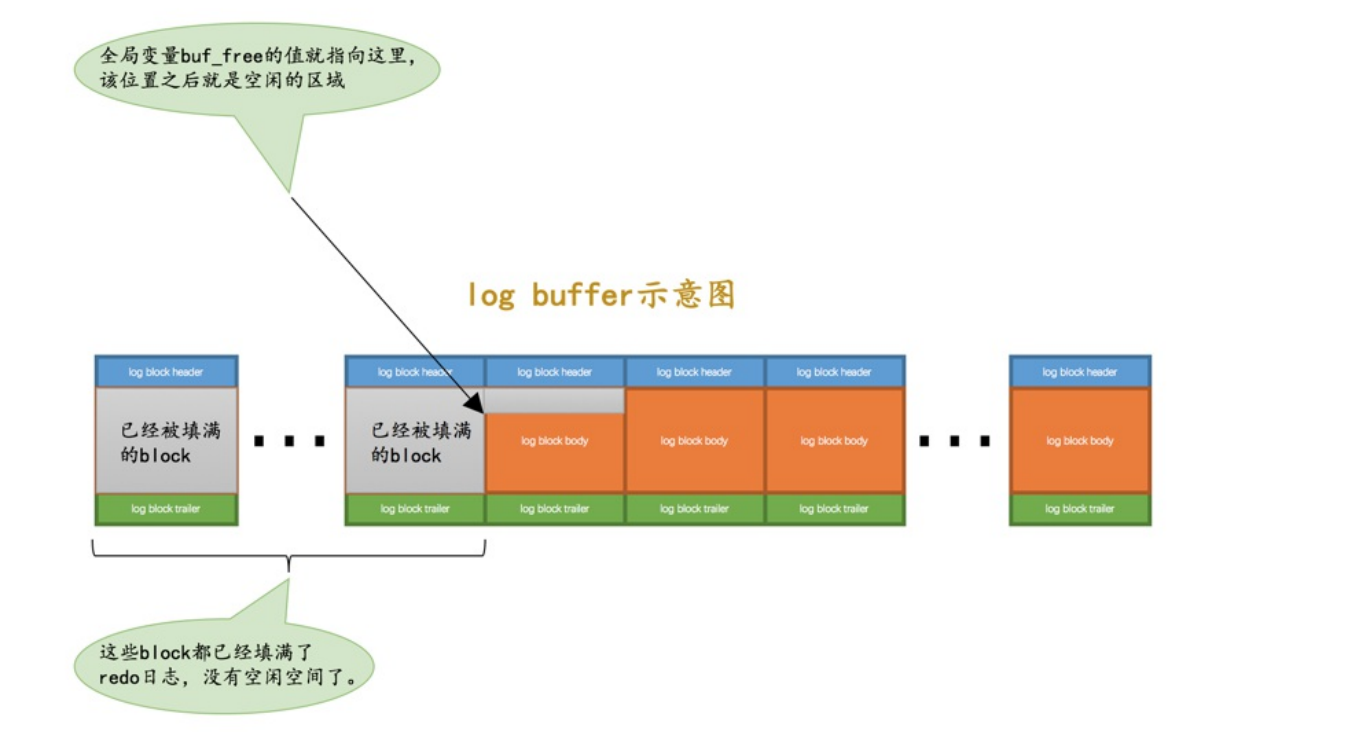
redo日志缓冲区
- redo log buffer是mysql申请的redo日志连续内存空间。
- 这段内存空间也被划分成为多个redo log block
- innodb_log_buffer_size可以限定buffer的大小。默认是16MB
- 问题是如果要写入数据那么要写入到哪个block的哪个偏移量上面?所以需要一个buf_free全局变量指明后序写入到的block的位置
- 两个事务可能会出现并发执行问题,导致每个语句也就是mtr是交错执行的,所以并不是生成一条log就存入log buffer,而是交替地存
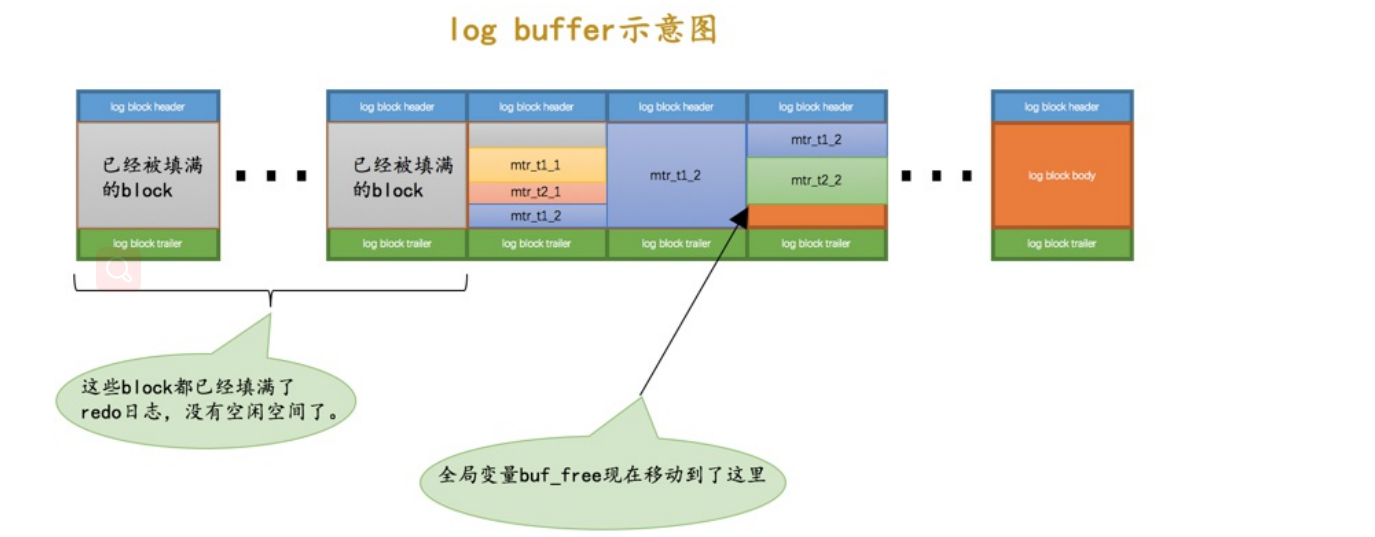
入到哪个block的哪个偏移量上面?所以需要一个buf_free全局变量指明后序写入到的block的位置
[外链图片转存中…(img-WcyLqsZx-1636338401019)]
- 两个事务可能会出现并发执行问题,导致每个语句也就是mtr是交错执行的,所以并不是生成一条log就存入log buffer,而是交替地存
[外链图片转存中…(img-tXZ0L1I8-1636338401020)]
[外链图片转存中…(img-7Z4pRjIT-1636338401021)]