说明
文章的图片来源《MySQL是怎么运行的:从根儿上理解MySQL》,本篇文章只是个人学习总结,欢迎大家买一本正版小册看看,对于mysql是由浅入深的讲解非常细致
目录
16.Explain 详解(下)
Extra
描述表的额外信息
- No tables used没有from语句
- Impossible WHERE:where永远是false
- No matching min/max row没有符合的聚集函数符合条件

- Using index:可以使用覆盖索引
- Using index condition:有索引列但是不能使用索引
SELECT * FROM s1 WHERE key1 > ‘z’ AND key1 LIKE ‘%a’;这一句里面的key1 like ‘%a’是无法使用到索引的,现在的执行顺序是
- 根据索引找到key1>'z’的所有记录
- 不符合key1 like 'a’的全部去掉不进行回表。减少了回表操作
-
Using where:where的条件需要进行全表扫描
-
Using join buffer (Block Nested Loop):因为不能有效使用索引,那么就只能先把s2的记录存入内存join buffer中。而不需要s1查询一次,然后IO获取s2的某些页到内存读取,然后又放回去,减少IO成本

- Not exists:左连接,where条件是对于被驱动表来说是不可能的。
- Using intersect(…)、Using union(…)和Using sort_union(…):使用了索引合并
- Zero limit:limit的参数是0
- Using filesort:无法使用到索引只能把数据加载到内存或者在磁盘上进行排序。
- Using temporary:借助临时表完成一些排序,group by的查询
- Start temporary, End temporary:in查询转换成semi-join+DuplicateWeedout建立临时表来进行去重操作。驱动表是start temporary,被驱动表是end temporary
- LooseScan:semi-join+looseScan。驱动表就是显示这个
- FirstMatch:semi-join+firstMatch进行去重
Json格式的执行计划
EXPLAIN FORMAT=JSON SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key2 WHERE s1.common_field = ‘a’\G
- 加上format = json就可以看到执行计划所需要的那些成本
这个是s1表的cost_info
“cost_info”: { “read_cost”: “1840.84”, “eval_cost”: “193.76”, “prefix_cost”: “2034.60”, “data_read_per_join”: “1M” }
- read_cost
- IO成本
- CPU成本:rows * (1-filtered)条记录
- eval_cost
- rows * filtered
- prefix_cost单独查询s1的成本
- read_cost + eval_cost
- data_read_per_join查询所需的数据量
cost_s2的cost_info
“cost_info”: { “read_cost”: “968.80”, “eval_cost”: “193.76”, “prefix_cost”: “3197.16”, “data_read_per_join”: “1M” }
- 对于s2来说单表查询是多次而不是一次,因为他是被驱动表。所以最后的prefix_cost并不是直接相加
17.optimizer trace 表的神奇功效
-
prepare阶段
-
optimize阶段
-
execute阶段
能够把整个优化选择过程展现出来SELECT * FROM information_schema.OPTIMIZER_TRACE

18.InnoDB 的 Buffer Pool
- 表空间其实只是多个实际文件的抽象
- 缓存其实就是把数据加载进内存不着急放回磁盘,能够多次被使用到。mysql向操作系统申请了一块内存作为mysql的buffer pool
Buffer Pool内部组成
- 缓存页也是16KB
- 控制块和缓存页一一对应,描述缓存页所在的表空间位置等
- 碎片就是刚好不够凑一对缓存页和控制块空出来的空间
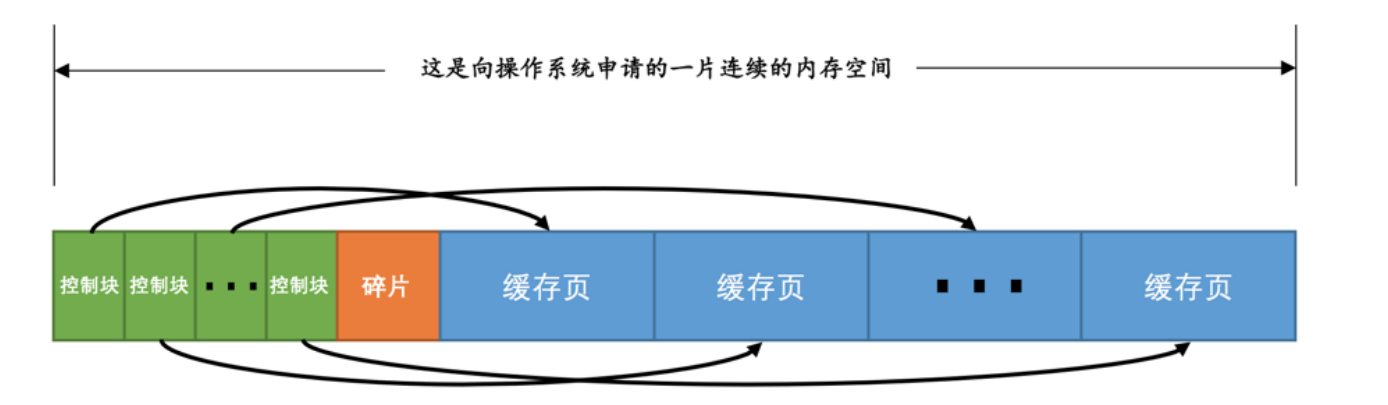
free链表的管理
- 怎么知道buffer pool哪些空间是空闲的?把所有控制块作为一个链表放到pool的一个位置,这个链表也可以叫做free链表
- free链表的基节点不包含在buffer pool申请的内存上面,它保存了头结点和尾节点的位置和链表的节点数量,占用40字节
- 如果节点被磁盘加载进来的数据页占用,那么节点就从链表中去掉
缓存页的哈希处理
- 如果程序需要访问这个缓存页的时候,那么应该怎么办?当然就是使用表空间号+页号来作为key,缓存页作为value进行存储。创建一个哈希表。
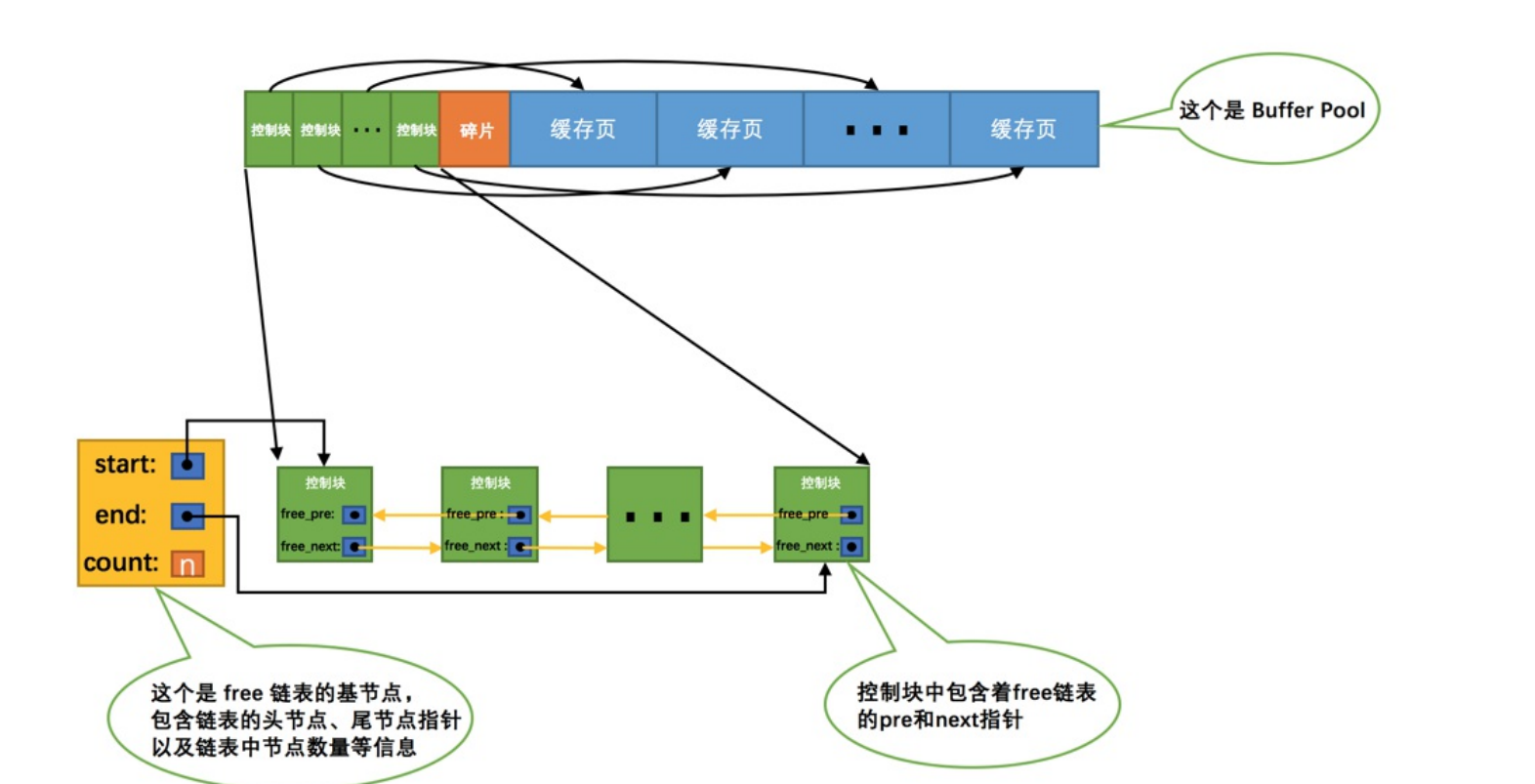
flush链表的管理
- 如果修改了内存的数据如何标记为脏页?需要创建一个flush链表,只要修改过就把缓存页的控制块弄成节点加入到flush链表
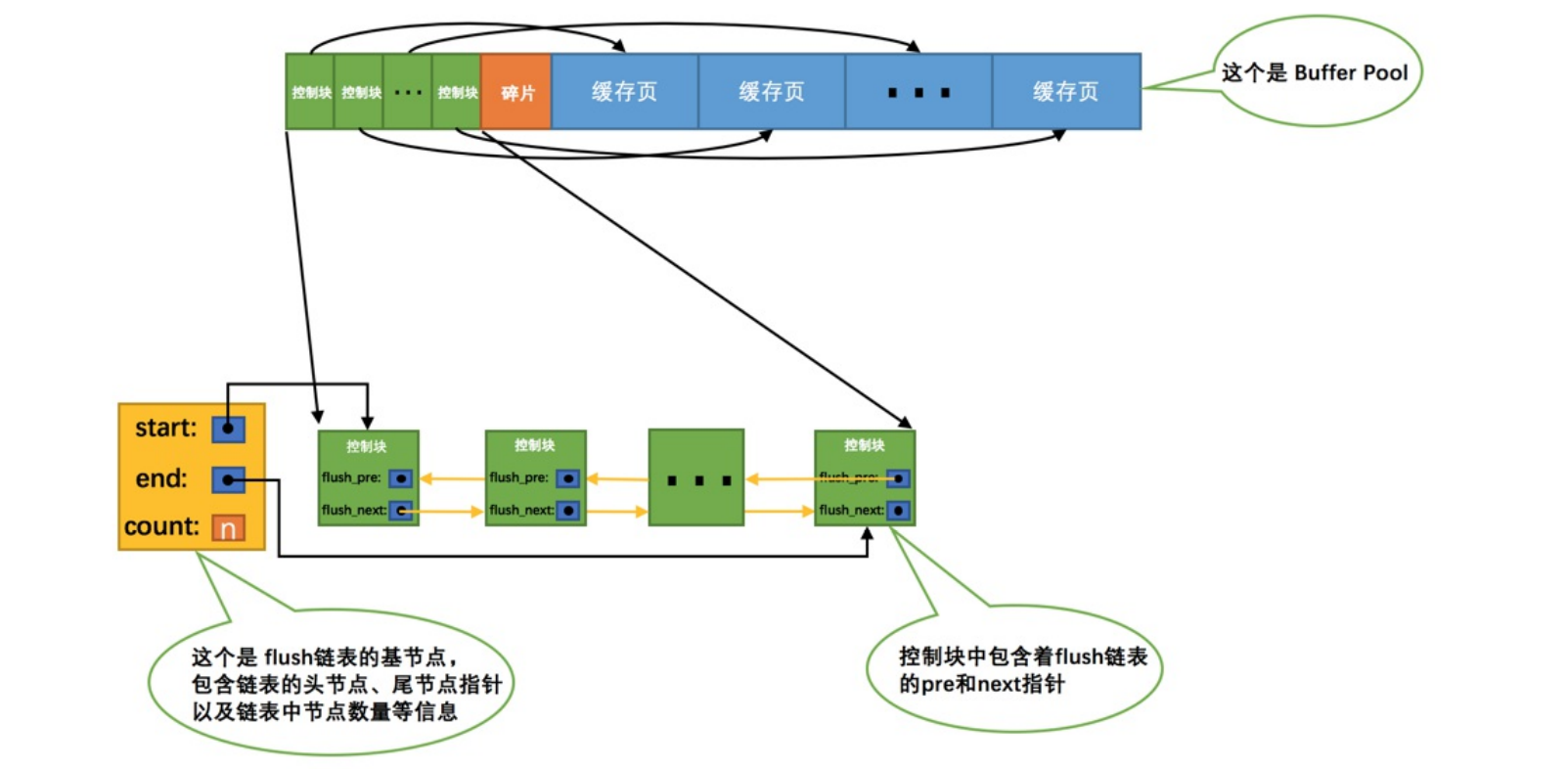
LRU链表管理
缓存不够的情况
- 如果缓存不足肯定就需要移除一些缓存,那么移除哪些?肯定就是最近n次里面,使用次数最少的那些缓存,用的多的那么就留下。最近频繁使用的。
简单的LRU链表
-
其实就是在缓存页从磁盘加载进来的时候,把控制块弄成节点放入LRU链表头部
-
如果该页已经存在,那么直接把控制块送到头部
-
新使用的都放到头部,也就是说链表尾部那个就是使用最近最少使用的。
划分区域的LRU链表
情况1:预读,先把磁盘数据页加载进来
- 线性预读
如果顺序读取某个区超过这个阈值(innodb_read_ahead_threshold)那么就会把下一个区的数据也提前读取进来。而且是异步读取
- 随机预读
意思就是如果已经缓存某个区13个连续页面,不管页面是不是顺序都会触发一次异步读取本区所有数据页进来。
情况2:写出来扫描全表的查询语句
把表所有的页直接缓存到buffer pool可能会导致多次换血。缓存没有作用
总结
- 加载到buffer pool不一定使用
- 很多使用频率少的页淘汰掉使用多的页问题,所以要把链表分成两截
- 使用频率高的,热数据,young
- 使用频率低的,冷数据,old
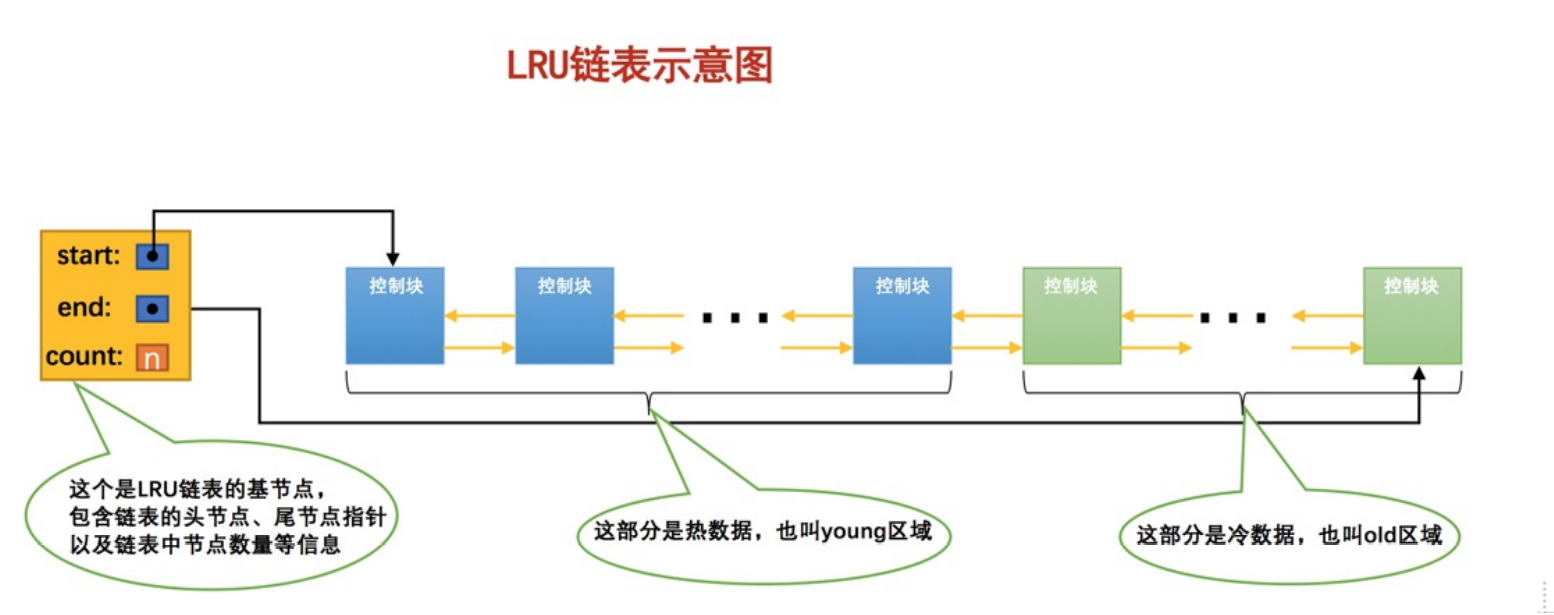
- LRU链表分成两半不是某些节点固定是young,某些节点是old,而是随着程序运行,节点所在的区域会发生变化。
针对预读的解决方案
- 第一次加载进来的页存放到old区,那么预读进来但是不访问的页会快速被淘汰
针对全表扫描
- 新加载进来的页,第一次访问记录下时间,如果第二次访问时间间隔太短说明可能就是全表扫描,那么就不会将数据页送到young区挤出那些访问频率高的页。(innodb_old_blocks_time)
所以链表分层+innodb_old_blocks_time解决了预读和全表扫描导致的缓存失效太快的问题。
更进一步优化LRU链表
- 实际上如果每次访问就跳到young开销就会非常大,所以规定了在young区域1/4后边的数据页才能够访问一次才能移动到链表的头部
刷新脏页到磁盘
后台有专门的线程负责刷新脏页
- 从LRU链表冷数据刷新一部分到磁盘
innodb_lru_scan_depth这个是扫描的冷数据页个数。这种刷新被称为BUF_FLUSH_LRU
- 从flush链表刷新一部分页面到磁盘
这种叫BUF_FLUSH_LIST
- BUF_FLUSH_SINGLE_PAGE这种的意思就是在内存不够的时候把LRU后面的数据页进行刷新到磁盘上,空出位置出来。
多个Buffer Pool实例
- 减少并发问题,因为申请内存可能是多个线程一起来申请导致的冲突变得很慢
- innodb_buffer_pool_size/innodb_buffer_pool_instances这个就是对应的每个pool占用的空间,如果innodb_buffer_pool_size小于1G那么开多几个pool是没有任何作用的。
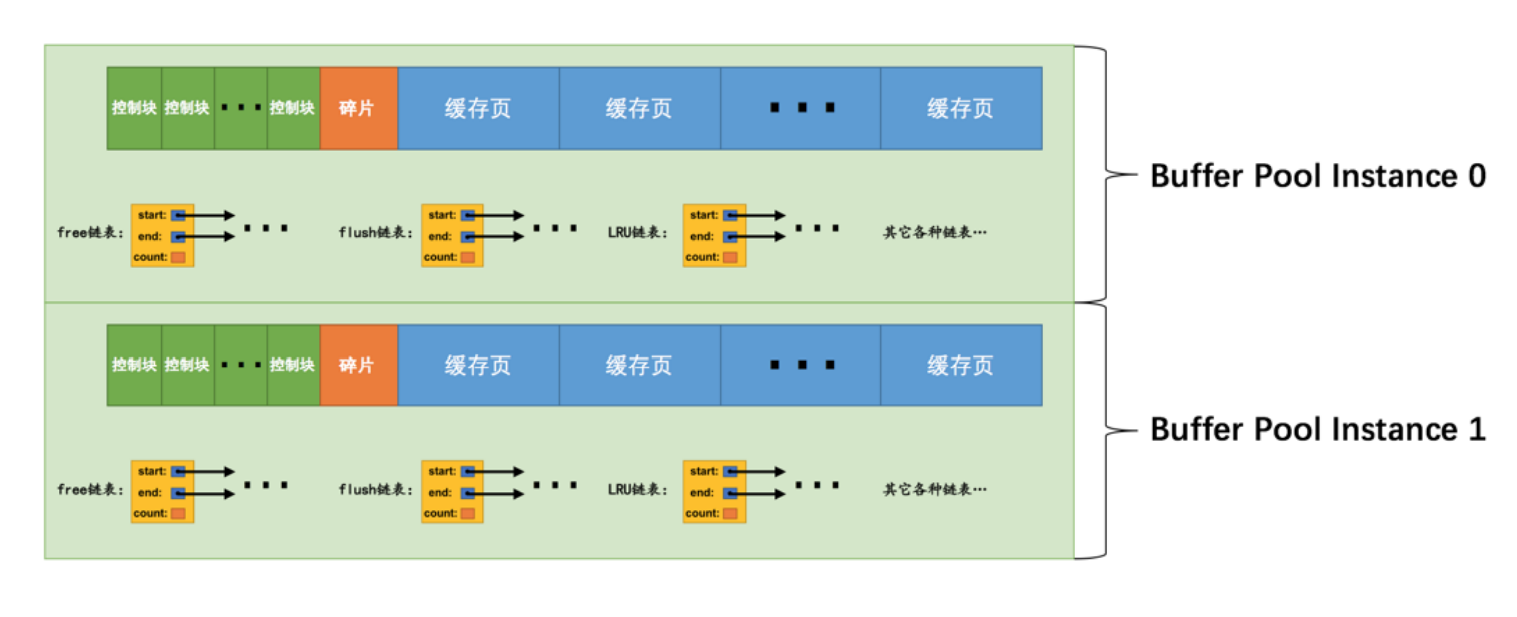
- innodb_buffer_pool_chunk_size,mysql为了能够调整pool大小使用的参数,因为调整pool大小需要请求一大段连续空间,导致运行速度很慢,所以现在以chunk为单位来请求pool的空间,这样转移的内存单位就变小了,速度也变快了,主要是添加内存只需要修改chunk的数量而不是开辟一大段空间。但是在程序运行的时候不要修改chunk,会导致大部分时间在进行迁移。开辟多个chunk。
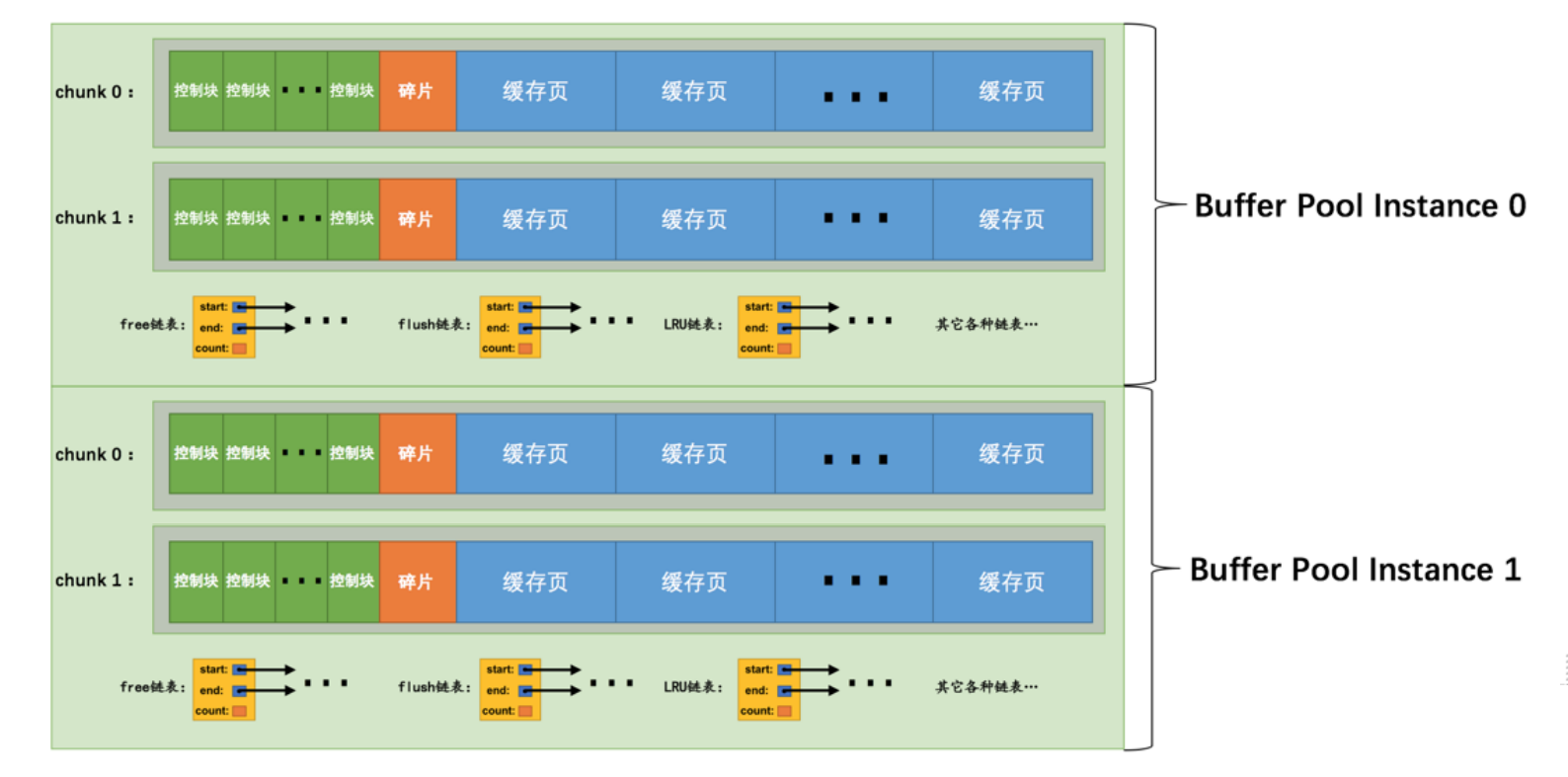
配置Buffer Pool时的注意事项
- innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数
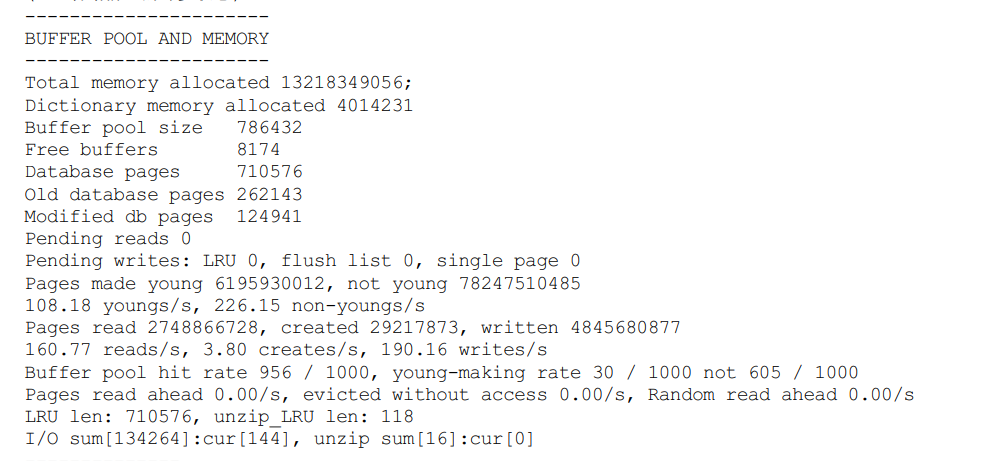
Buffer Pool中存储的其它信息


总结
- 磁盘太慢需要使用内存缓存
- 缓存需要通过控制块管理
- LRU链表分区old和young,来管理这些缓存页淘汰最近少使用的缓存页
- free链表控制空间的缓存页和控制块
- buffer被修改之后不是立刻同步到磁盘,而是先放到flush链表上面