- 题意:
给定一个字典,里面包含一些string,给定一个句子,从中匹配最多的字典中的string。输出未匹配的最少的字符数。
- 思路:
动态规划 + 字典树
(1)动态规划
dp[i] 代表 前i个字符未匹配的最少字符数。
当遍历到第i个字符时,判断从 j 到第i个字符是否在字典中,如果在字典中,则
dp[i] = min(dp[i], dp[j-1])。为什么是 dp[j-1],因为第j个字符到第i个都在字典中,所以是前 j-1个字符的未匹配最少字符数。
若没在字典中匹配,则 dp[i] = dp[i-1] + 1。即相对于前 i-1个字符,多了一个第i个字符没有匹配。
(2)字典树 Trie
如何快速判断当前子串是否在字典中,就要用到字典树。一般的字典树,也称为前缀树。
来看一个例子,用单词 love、meet、pain、like构建字典树 Trie:
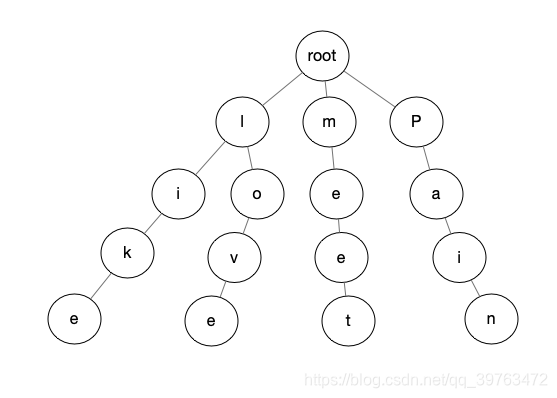
可以看到,根节点不保存字符;根节点到叶子节点的路径就是一个字符串;有公共前缀的字符串like 和love 在一个子树中。
这样每次寻找一个字符时,有公共前缀的字符便很容易寻找。
而在此题中,因为我们遍历i节点,然后从j ——i判断是否有字符匹配。那么我们相当于建立的是一个后缀树。上图中的树就会变成:
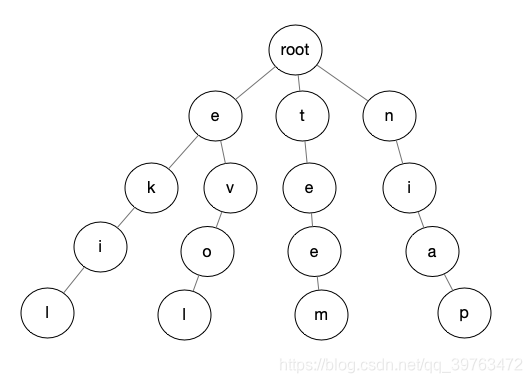
例如我们目标串为asdflike.
当我们遍历到e时,j from i to 0。e在树中,j --;否则只要匹配不到叶子节点就退出循环。这样当 匹配到 l 时,我们创建树时预先在每个叶子节点设置一个isEnd标志,标志是叶子节点,代表我们匹配了一个字符串。
- 代码:
class Trie{
public:
Trie* next[26] = {
nullptr};
bool isEnd;
Trie(){
isEnd = false;
}
void insert(string s){
Trie* curPos = this;
for(int i = s.length()-1;i >= 0;i--){
int tmp = s[i] - 'a';
if(curPos->next[tmp] == nullptr){
curPos->next[tmp] = new Trie();
}
curPos = curPos->next[tmp];
}
curPos->isEnd = true;
}
};
class Solution {
public:
int respace(vector<string>& dictionary, string sentence) {
int n = sentence.length();
Trie* root = new Trie();
for(auto& word : dictionary){
root->insert(word);
}
vector<int> dp(n+1, INT_MAX);
dp[0] = 0;
for(int i = 1;i <= n;i++){
dp[i] = dp[i-1] + 1;
Trie* curPos = root;
for(int j = i;j >= 1;j--){
int t = sentence[j-1] - 'a';
if(curPos->next[t] == nullptr){
break;
}else if(curPos->next[t]->isEnd){
dp[i] = min(dp[i], dp[j-1]);
}
if(dp[i] == 0){
break;
}
curPos = curPos->next[t];
}
}
return dp[n];
}
};
- 收获
因为之前没怎么做过字符串dp,以及字典树的应用。这次学到了很多。当然肯定每个题都不一样,需要自己灵活运用。dp也需要多做题才能对状态转移公式有所掌握。