好吧,先来看一个列子
在特征工程中,做特征缩放是非常重要的,如下图所示:
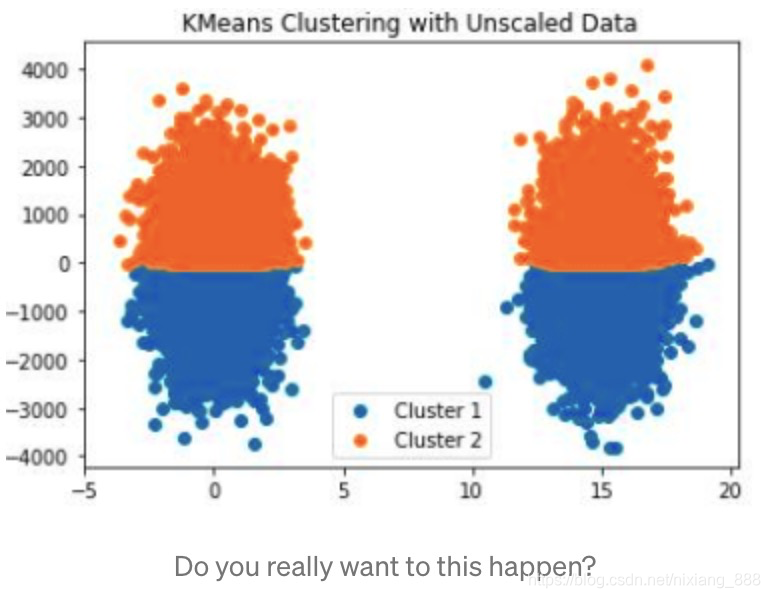
我们可以看到,在没做特征缩放前,用kmeans跑出的聚类结果就如图所示,以y=0为分界线,上面是一类,下面是一类,相当的离谱.主要原因就是y值的取值范围很大,从-4000 ~ 4000,而x轴只有-5~20,熟悉kmeans算法都清楚该算法中距离度量用的是欧式距离,因此x轴的数值就变得无关紧要.所以数据预处理没做好,很多模型都将不生效.
值得注意的是,scaling在数据预处理中并不是强制的,习惯用树模型的朋友们也很清楚对树模型而言,scaling对效果毫无影响.但是对于一些对距离敏感的算法影响就比较大了,如KNN,SVM,PCA,NN等.
Scaling的目的很简单,一方面是使得每列特征“范围”更接近,另一方面是让计算变得更加简单,如梯度下降在特征缩放后,将缩放的更快,效果更好,所以对于线性回归,逻辑回归,NN都需要做特征缩放:
特征缩放有很多种,我们介绍最常见的4种:
-
StandardScaler
-
RobustScaler
-
MinMaxScaler
-
MaxAbsScaler
第一种:StandardScaler
这种scale方法大家最熟悉了,通过减去均值再除以方差进行标准化.需要注意的是异常值对于这种scale方法的伤害是毁灭性的,因为异常值影响均值.如果你的数据是正太分布或接近正太分布,并且没有特别异常的值,可以使用该方法进行缩放.
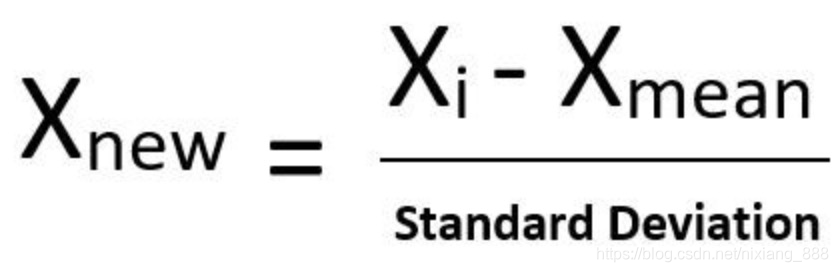
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler
def plot_figure(dat):
fig = plt.figure(figsize=(7, 7))
plt.hist(dat, bins=80, alpha=0.5)
plt.show()
plt.close()
tau = 10
df1 = pd.DataFrame({
"X": np.random.exponential(tau, size=10000)})
plot_figure(df1.X)
dat_scale = StandardScaler().fit_transform(df1)
plot_figure(dat_scale)
让我们看下该缩放方法,对有偏态分布的数据会产生什么影响.
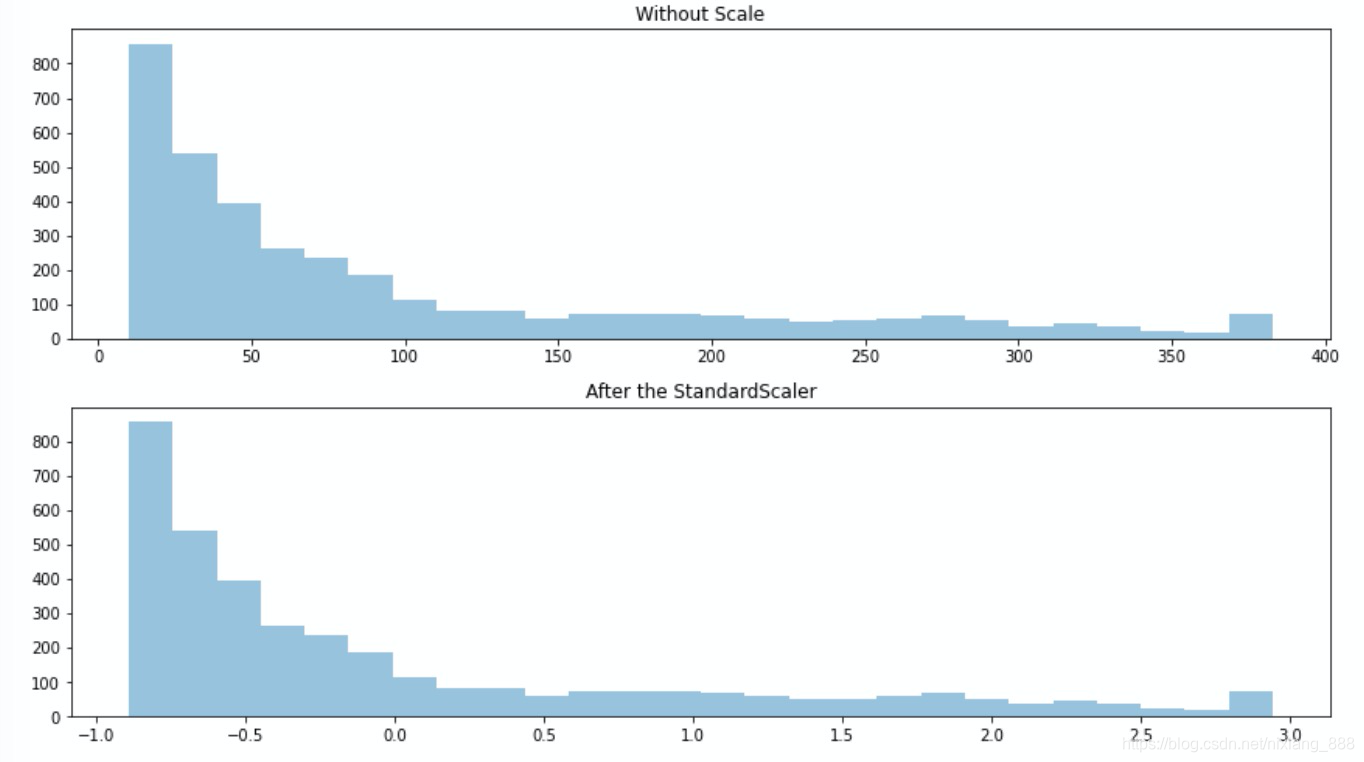
我们发现,对偏态分布的数据缩放后并没有改变其分布.我们对数据做次log再缩放呢?
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler
fig = plt.figure(figsize=(9, 5))
def plot_figure(dat, tt):
plt.hist(dat, bins=80, alpha=0.5)
plt.title(tt)
tau = 10
df1 = pd.DataFrame({
"X": np.random.exponential(tau, size=10000)})
p1 = fig.add_subplot(121)
plot_figure(df1.X, tt="Without Scaling")
df1 = np.log(df1)
dat_scale = StandardScaler().fit_transform(df1)
p2 = fig.add_subplot(122)
plot_figure(dat_scale, tt="Log and Scaling")
plt.show()
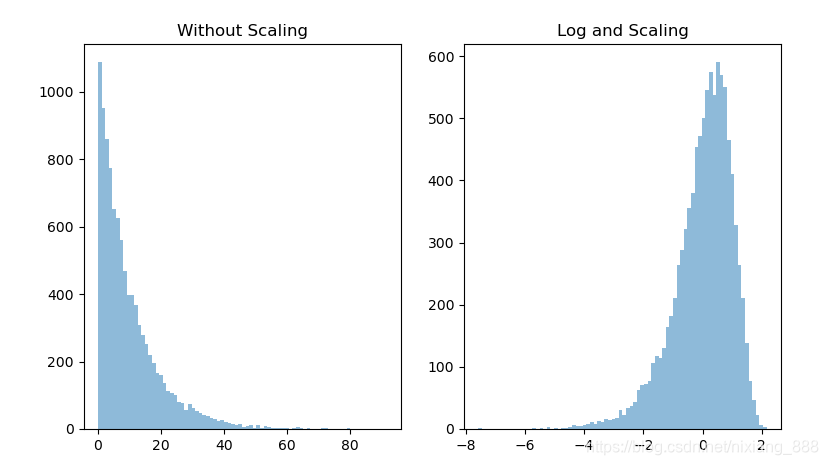
我们发现log使得数据接近正态分布,StandardScaler使得数据变成了标准正态分布,这种方法往往表现的更好并且降低了异常值的影响.
第二种:RobustScaler
RobustScaler是基于中位数的缩放方法,具体是减去中位数再除以第3分位数和第一分位数之间的差值.如下所示:
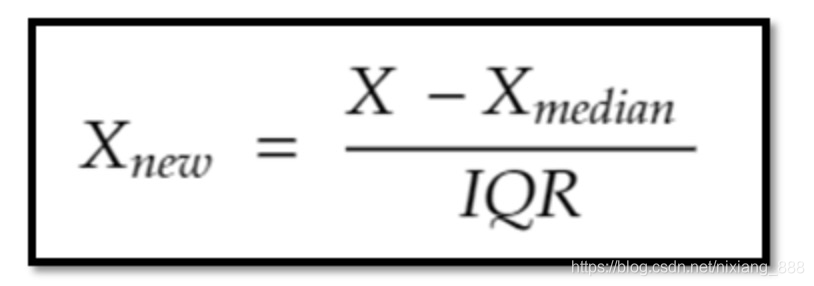
因为该缩放方法用了分位点的差值,所以它降低了异常值的影响,如果你发现数据有异常值,并且懒得去修正它们,就用这种缩放方法吧.
- StandardScaler使得异常值更接近均值了,但是在RobustScaler后,异常值还是显得比较异常.
第三种方法:MinMaxScaler
MinMaxScaler使得数据缩放到0~1之间,缩放由最小值和最大值决定,因此会受到异常值影响.并且对新出现的最大最小值并不友好.
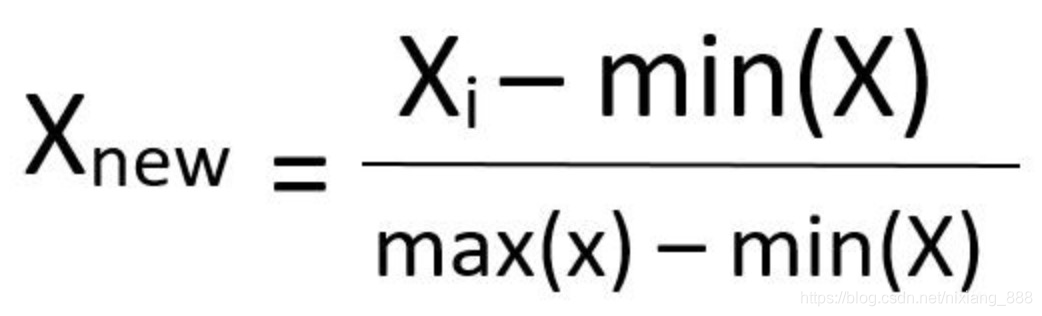
第四种方法:MaxAbsScaler
from sklearn.preprocessing import MaxAbsScaler
该缩放方法不会破坏数据的稀疏性,也不会改变数据的分布,仅仅把数据缩放到了-1~1之间.MaxAbsScaler就是让每个数据Xi/|Xmax|,值得注意的是,该方法对异常值也相当敏感.
总结一下:
StandardScaler: 不适用于有异常值的数据;使得均值为0.
RobustScaler: 适用于有异常值的数据.
MinMaxScaler: 不适用于有异常值的数据;使得数据缩放到0~1.
MaxAbsScaler: 不适用于有异常值的数据;使得数据缩放到-1~1.