2021SC@SDUSC
简介
将PositionRank模型在指定中文数据集上运行需要克服两个主要难点:1.数据集的格式不同。2.需要修改数据处理代码,修改分句、分词方法,去除词干还原算法。
本文将解决第一个问题。
数据集格式
在PositionRank原数据集中,数据被分成了两个文件夹,分别对应原文和关键词,文件名一一对应。而本项目前期获取数据存储在csv文件中,文件名-摘要-关键词为一个数据项。
思路一
对数据进行预处理,将其保存为原数据集的形式。
思路二
修改文件读取算法,为该形式的数据集定义合适的方法。
最终选择
经过对代码的再次分析,我选择使用思路一进行修改,原因是使用思路一无需修改任何代码,而使用思路二既需要修改数据读取部分的代码,又需要修改流程控制的代码。
算法实现
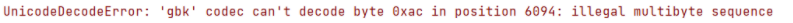
可能是编码方式未统一。使用记事本打开爬取的csv文件,将该文件以‘utf-8’编码保存,同时指定文件读取的解码方式为utf-8,然而该问题仍未消除。
考虑到文件可能存在微小损坏,因此在读取时遇到错误可以采取ignore模式。
with open('data.csv','r',encoding='utf-8',errors='ignore') as f:
具体实现如下:
def read_source():
"""用于读取百度学术数据集(csv文件),同时将每条数据转化为单个文件"""
num = 0
with open('data.csv','r',encoding='utf-8',errors='ignore') as f:
reader = csv.reader(f)
row = next(reader)
# csv文件可以使用next(reader)访问,注意第一行是表头,也可以使用for循环遍历
for row in reader:
print(num)
# num用于文件命名和进度显示
num+=1
# 将题目和摘要作为文本内容
# 防止内容为空时出现越界异常
try:
content = row[0]+" "+ row[1]
except IndexError:
content = ''
# 关键词字符串
# 防止内容为空时出现越界异常
try:
keywords = row[2]
except IndexError:
keywords=''
# 生成文件路径
doc_path = os.path.join('my_data/doc',str(num))
gold_path = os.path.join('my_data/gold',str(num))
with open(doc_path,'w',encoding='utf-8') as doc:
doc.write(content)
with open(gold_path,'a',encoding='utf-8') as gold:
# 将关键词分行写入
keywords_list = keywords.split(';')
for keyword in keywords_list:
gold.write(keyword+'\n')