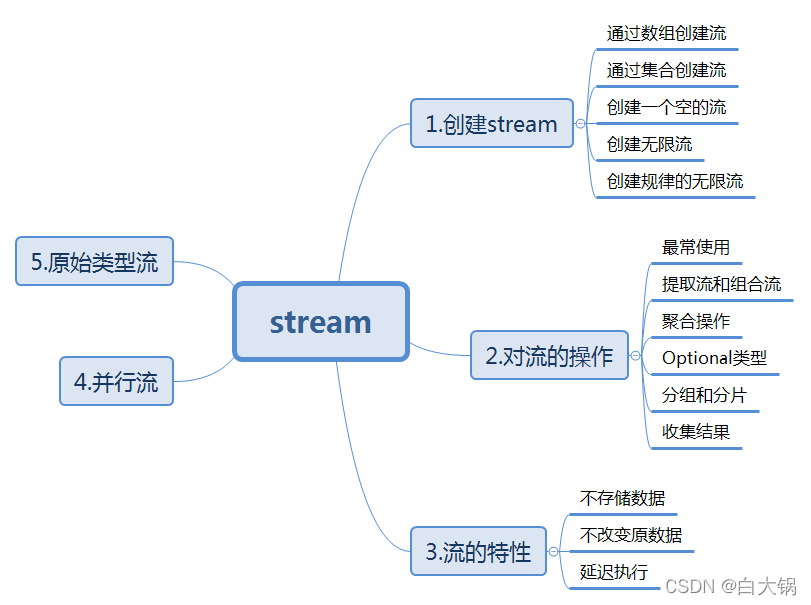
Stream流目录
- 前言
- 一、初识Stream流
- 二、Sream流的创建
- 三、Stream流的操作及实例详解
-
- 3.1.中间操作
- 3.2.终端操作
- 3.2.5.collect
- 3.3.Stream中的Collectors操作
-
- 3.3.1.Collectors.toList()
- 3.3.2.Collectors.toSet()
- 3.3.3.Collectors.toCollection()
- 3.3.4.Collectors.toMap()
- 3.3.5.Collectors.collectingAndThen()
- 3.3.6.Collectors.joining()
- 3.3.7.Collectors.counting()
- 3.3.8.Collectors.summarizingDouble/Long/Int()
- 3.3.9.Collectors.averagingDouble/Long/Int()
- 3.3.10.Collectors.summingDouble/Long/Int()
- 3.3.11.Collectors.maxBy()/minBy()
- 3.3.12.Collectors.groupingBy()
- 3.3.13.Collectors.partitioningBy()
- 3.4.Stream 完整实例
前言
lambda表达式是stream的基础,初学者建议先学习lambda表达式—>,Java8新特性之Lambda表达式
一、初识Stream流
1.1.Stream概述
流是有关算法和计算的,允许你以声明性方式处理数据集合,可以看成遍历数据集的的高级迭代器。
此外,和迭代器不同,流还可以并行处理。数据可以分成多段,其中每一个都在不同的线程中执行,最后将结果一起输出。
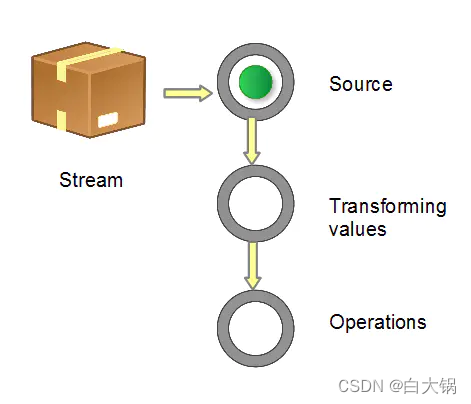
当我们使用一个流的时候,通常包括三个基本步骤:
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道,如下图所示。
1.2.流的三大特点
1.流不储存元素;
2.流不会修改其数据源;
3.流执行具有延迟特性;
二、Sream流的创建
2.1.从数组或集合
1 .
Arrays.stream(T array) or Stream.of()
2 .Collection.stream()
3 .Collection.parallelStream()
@Test
public void testArrayStream() {
//1.通过Arrays.stream
//1.1基本类型
Integer[] arr = new Integer[]{
1,2,3,4,5,6,7};
//通过Arrays.stream
Stream stream1 = Arrays.stream(arr);
stream1.forEach(System.out::print);
//2.通过Stream.of
Stream<Integer> stream2 = Stream.of(1,2,3,4,5,6,7);
stream2.forEach(System.out::print);
}
@Test
public void testCollectionStream(){
List<Integer> strs = Arrays.asList(1,2,3,4,5,6,7);
//创建普通流
Stream<Integer> stream = strs.stream();
//创建并行流
Stream<Integer> stream1 = strs.parallelStream();
}
2.2.创建无限流
@Test
public void test4(){
// 迭代
// public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
//遍历前10个偶数
Stream.iterate(0, t -> t + 2).limit(10).forEach(System.out::print);
System.out.println();
Stream.iterate(1,t->t+2).limit(5).forEach(System.out::print);
System.out.println();
// 生成
// public static<T> Stream<T> generate(Supplier<T> s)
Stream.generate(Math::random).limit(10).forEach(System.out::println);
List<Double> collect = Stream.generate(Math::random).limit(10).collect(Collectors.toList());
Stream.generate(Math::random).limit(10).collect(Collectors.toList());
}
2.3.创建规律流
@Test
public void testUnlimitStream1(){
Stream.iterate(0,x -> x+1).limit(10).forEach(System.out::println);
Stream.iterate(0,x -> x).limit(10).forEach(System.out::println);
}
2.4.通过Stream的of()
@Test
public void test3(){
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
}
三、Stream流的操作及实例详解
流操作分为中间操作和终端操作,中间操作会返回另外一个流,可以继续执行下一个中间操作。
终端操作是返回结果,终端操作触发流执行中间操作,终端操作,到此流的生命结束。
3.1.中间操作
3.1.1.filter
filter对原始Stream进行过滤,符合条件的原数被留下来生成新的流。
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
// 获取空字符串的数量
long count = strings.stream().filter(string -> string.isEmpty()).count();
3.1.2.sorted
sorted对原始Stream中的元素进行排序,排序后生成新的流。
Random random = new Random();
random.ints().limit(10).sorted().forEach(System.out::println);
3.1.3.distinct
去掉重复值
@Test
public void testDistinct() {
Integer[] sixNums = {
1, 2, 4, 3, 5, 5, 6};
Integer[] distinctedNums = Stream.of(sixNums).distinct().toArray(Integer[]::new);
System.out.println(distinctedNums);
}
3.1.4.map
map将现有流转换为新的流。map接收一个函数作为参数,该函数作用于流中的每一个元素,并将其映射成一个新的元素。
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
// 获取对应的平方数
List<Integer> squaresList = numbers.stream().map( i -> i*i).distinct().collect(Collectors.toList());
3.1.5.flatMap
将流扁平化,流中的每一个元素都被拆解成一个新的流。使用flatMap需要提前知道原来的流中的元素类型。
@Test
public void testFlapMap1() {
String[] words = {
"Hello", "World"};
Stream.of(words)
.map(word -> word.split(""))
.flatMap(Arrays::stream).forEach(System.out::println);
}
3.1.6.limit
截断流,该方法返回一个不超过给定长度的流。
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);
3.2.终端操作
遍历流中的每一个元素。当需要为多核系统优化时,可以 parallelStream().forEach(),只是此时原有元素的次序没法保证,并行的情况下将改变串行时操作的行为。
@Test
public void testFlapMap1() {
String[] words = {
"Hello", "World"};
Stream.of(words)
.map(word -> word.split(""))
.flatMap(Arrays::stream).forEach(System.out::println);
}
3.2.1.findFirst, findAny
//两者功能类似,findAny不要求顺序,使用并行流有优势。
@Test
public void testFindFirser() {
String[] arr = new String[]{
"yes", "YES", "no", "NO"};
Arrays.stream(arr).filter(str -> Objects.equals(str, "yes")).findFirst().ifPresent(System.out::println);
}
3.2.2.allMatch, noneMatch, anyMatch
Stream提供了三个match方法,allMatch要求流中所有元素满足条件才返回true, anyMatch中只要有一个元素符合就返回true, noneMatch与allMatch相反,所有元素都不符合,返回true
@Test
public void testMatch() {
String[] arr = new String[]{
"yes", "YES", "no", "NO"};
System.out.println(Arrays.stream(arr).noneMatch( str -> str.length() > 2));
System.out.println(Arrays.stream(arr).anyMatch( str -> str.length() > 2));
System.out.println(Arrays.stream(arr).allMatch( str -> str.length() > 2));
}
3.2.3.reduce
这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于
Integer sum = integers.reduce(0, (a, b) -> a+b);
或
Integer sum = integers.reduce(0, Integer::sum);
@Test
public void testReduce() {
// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").filter(x -> x.compareTo("Z") > 0).reduce("", String::concat);
}
3.2.4.统计(count/averaging)
此处参考文章:Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合
Collectors提供了一系列用于数据统计的静态方法:
计数:count
平均值:averagingInt、averagingLong、averagingDouble
最值:maxBy、minBy
求和:summingInt、summingLong、summingDouble
统计以上所有:summarizingInt、summarizingLong、summarizingDouble
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
// 求总数
Long count = personList.stream().collect(Collectors.counting());
// 求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
// 求最高工资
Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
// 求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
// 一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("员工总数:" + count);
System.out.println("员工平均工资:" + average);
System.out.println("员工工资总和:" + sum);
System.out.println("员工工资所有统计:" + collect);
}
}
运行结果:
员工总数:3
员工平均工资:7900.0
员工工资总和:23700
员工工资所有统计:DoubleSummaryStatistics{
count=3, sum=23700.000000,min=7000.000000, average=7900.000000, max=8900.000000}
3.2.5.collect
这个在实际项目中使用非常多,通过collect生成结果。可以生成各种形式,Array, List, Set, Map。另外,还能进行分组。
public class Student {
private String name;
private Integer score;
//-----getters and setters-----
Student(String name, Integer score) {
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public Integer getScore() {
return score;
}
public String toString() {
return "name: " + name
+ " score: " + score;
}
}
Student[] students;
@Before
public void init(){
students = new Student[10];
for (int i = 0; i <= 3; i++){
Student student = new Student("user", i);
students[i] = student;
}
for (int i = 3; i <= 6; i++){
Student student = new Student("user" + i, i + 1);
students[i] = student;
}
for (int i = 6; i < 10; i++){
Student student = new Student("user" + i, i + 2);
students[i] = student;
}
}
@Test
public void testCollect1(){
/**
* 生成List
*/
List<Student> list = Arrays.stream(students).collect(Collectors.toList());
list.forEach((x) -> System.out.println(x));
/**
* 生成Set
*/
Set<Student> set = Arrays.stream(students).collect(Collectors.toSet());
set.forEach((x)-> System.out.println(x));
/**
* 生成Map,如果包含相同的key,则需要提供第三个参数,否则报错, 这里用了覆盖旧value
*/
Map<String,Integer> map = Arrays.stream(students).collect(Collectors.toMap(Student::getName, Student::getScore, (v1, v2) -> v2));
map.forEach((x, y) -> System.out.println(x + "->" + y));
}
/**
* 生成数组
*/
@Test
public void testCollect2(){
Student[] s = Arrays.stream(students).toArray(Student[]::new);
for (int i=0; i< s.length; i++)
System.out.println(s[i]);
}
3.2.6.groupingBy
groupingBy能够将流按照某个条件进行进行分组和分片,条件为key,分组之后的元素组成新的流,对新的流可以进行中间操作和终端操作,默认生成List。最后生成Map的类型,key就是分组条件,value取决于对分组后的流进行操作后生成的类型。生成Map会有重复key的问题,使用groupingBy将重复key的value值放到一个List, 同样能够解决此问题。
如果想要按照多个条件进行分组,一种方法是groupingB嵌套使用groupBy,多次进行分组;另一种方法是按照多个分组条件进行拼接成一个key,按照这个拼接后的key进行分组。
@Test
public void testGroupBy1(){
Map<String,List<Student>> map = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* 如果只有两类,使用partitioningBy会比groupingBy更有效率
*/
@Test
public void testPartitioningBy(){
Map<Boolean,List<Student>> map = Arrays.stream(students).collect(Collectors.partitioningBy(x -> x.getScore() > 5));
map.forEach((x, y)-> System.out.println(x+ "->" + y));
}
/**
* downstream指定类型
*/
@Test
public void testGroupBy2(){
Map<String,Set<Student>> map = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName, Collectors.toSet()));
map.forEach((x, y)-> System.out.println(x + "->"+ y));
}
/**
* downstream 聚合操作
*/
@Test
public void testGroupBy3(){
/**
* counting
*/
Map<String,Long> map1 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName, Collectors.counting()));
map1.forEach((x, y)-> System.out.println(x + "->" + y));
/**
* summingInt
*/
Map<String,Integer> map2 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName, Collectors.summingInt(Student::getScore)));
map2.forEach((x,y) -> System.out.println(x + "->" + y));
/**
* maxBy
*/
Map<String,Optional<Student>> map3 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName, Collectors.maxBy(Comparator.comparing(Student::getScore))));
map3.forEach((x, y)-> System.out.println(x + "->" + y));
/**
* mapping, 这种也用的比较多,可以用元素的变量作为value, 也可以创建新的对象作为value
*/
Map<String,Set<Integer>> map4 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName, Collectors.mapping(Student::getScore, Collectors.toSet())));
map4.forEach((x, y)-> System.out.println(x + "->" + y));
/**
* mapping, 使用元素多个变量进行分组
*/
Map<String, Map<Integer, List<Student>>> map5 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName, Collectors.groupingBy(Student::getScore)));
map5.forEach((x, y)-> System.out.println(x + "->" + y));
/**
* mapping, 使用元素多个变量进行分组, 第二种方法,将多个变量进行拼接, 个人推荐使用这种
*/
Map<String, List<Student>> map6 = Arrays.stream(students).collect(Collectors.groupingBy(student -> student.getName() + "_" + student.getScore()));
map6.forEach((x, y)-> System.out.println(x + "->" + y));
}
3.3.Stream中的Collectors操作
3.3.1.Collectors.toList()
List<String> listResult = list.stream().collect(Collectors.toList());
log.info("{}",listResult);
将stream转换为list。这里转换的list是ArrayList,如果想要转换成特定的list,需要使用toCollection方法。
3.3.2.Collectors.toSet()
Set<String> setResult = list.stream().collect(Collectors.toSet());
log.info("{}",setResult);
toSet将Stream转换成为set。这里转换的是HashSet。如果需要特别指定set,那么需要使用toCollection方法。
因为set中是没有重复的元素,如果我们使用duplicateList来转换的话,会发现最终结果中只有一个jack。
Set<String> duplicateSetResult = duplicateList.stream().collect(Collectors.toSet());
log.info("{}",duplicateSetResult);
3.3.3.Collectors.toCollection()
上面的toMap,toSet转换出来的都是特定的类型,如果我们需要自定义,则可以使用toCollection()
List<String> custListResult = list.stream().collect(Collectors.toCollection(LinkedList::new));
log.info("{}",custListResult);
上面的例子,我们转换成了LinkedList。
3.3.4.Collectors.toMap()
toMap接收两个参数,第一个参数是keyMapper,第二个参数是valueMapper:
Map<String, Integer> mapResult = list.stream()
.collect(Collectors.toMap(Function.identity(), String::length));
log.info("{}",mapResult);
如果stream中有重复的值,则转换会报IllegalStateException异常:
Map<String, Integer> duplicateMapResult = duplicateList.stream()
.collect(Collectors.toMap(Function.identity(), String::length));
怎么解决这个问题呢?我们可以这样:
Map<String, Integer> duplicateMapResult2 = duplicateList.stream()
.collect(Collectors.toMap(Function.identity(), String::length, (item, identicalItem) -> item));
log.info("{}",duplicateMapResult2);
在toMap中添加第三个参数mergeFunction,来解决冲突的问题。
3.3.5.Collectors.collectingAndThen()
collectingAndThen允许我们对生成的集合再做一次操作。
List<String> collectAndThenResult = list.stream()
.collect(Collectors.collectingAndThen(Collectors.toList(), l -> {
return new ArrayList<>(l);}));
log.info("{}",collectAndThenResult);
3.3.6.Collectors.joining()
Joining用来连接stream中的元素:
String joinResult = list.stream().collect(Collectors.joining());
log.info("{}",joinResult);
String joinResult1 = list.stream().collect(Collectors.joining(" "));
log.info("{}",joinResult1);
String joinResult2 = list.stream().collect(Collectors.joining(" ", "prefix","suffix"));
log.info("{}",joinResult2);
可以不带参数,也可以带一个参数,也可以带三个参数,根据我们的需要进行选择。
3.3.7.Collectors.counting()
counting主要用来统计stream中元素的个数:
Long countResult = list.stream().collect(Collectors.counting());
log.info("{}",countResult);
3.3.8.Collectors.summarizingDouble/Long/Int()
SummarizingDouble/Long/Int为stream中的元素生成了统计信息,返回的结果是一个统计类:
IntSummaryStatistics intResult = list.stream()
.collect(Collectors.summarizingInt(String::length));
log.info("{}",intResult);
输出结果:
22:22:35.238 [main] INFO com.flydean.CollectorUsage - IntSummaryStatistics{
count=4, sum=16, min=3, average=4.000000, max=5}
3.3.9.Collectors.averagingDouble/Long/Int()
averagingDouble/Long/Int()对stream中的元素做平均:
Double averageResult = list.stream().collect(Collectors.averagingInt(String::length));
log.info("{}",averageResult);
3.3.10.Collectors.summingDouble/Long/Int()
summingDouble/Long/Int()对stream中的元素做sum操作:
Double summingResult = list.stream().collect(Collectors.summingDouble(String::length));
log.info("{}",summingResult);
3.3.11.Collectors.maxBy()/minBy()
maxBy()/minBy()根据提供的Comparator,返回stream中的最大或者最小值:
Optional<String> maxByResult = list.stream().collect(Collectors.maxBy(Comparator.naturalOrder()));
log.info("{}",maxByResult);
3.3.12.Collectors.groupingBy()
GroupingBy根据某些属性进行分组,并返回一个Map:
Map<Integer, Set<String>> groupByResult = list.stream()
.collect(Collectors.groupingBy(String::length, Collectors.toSet()));
log.info("{}",groupByResult);
3.3.13.Collectors.partitioningBy()
PartitioningBy是一个特别的groupingBy,PartitioningBy返回一个Map,这个Map是以boolean值为key,从而将stream分成两部分,一部分是匹配PartitioningBy条件的,一部分是不满足条件的:
Map<Boolean, List<String>> partitionResult = list.stream()
.collect(Collectors.partitioningBy(s -> s.length() > 3));
log.info("{}",partitionResult);
看下运行结果:
22:39:37.082 [main] INFO com.flydean.CollectorUsage - {
false=[bob], true=[jack, alice, mark]}
结果被分成了两部分。
3.4.Stream 完整实例
import java.util.ArrayList;
import java.util.Arrays;
import java.util.IntSummaryStatistics;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.Map;
public class Java8Tester {
public static void main(String args[]){
System.out.println("使用 Java 7: ");
// 计算空字符串
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
System.out.println("列表: " +strings);
long count = getCountEmptyStringUsingJava7(strings);
System.out.println("空字符数量为: " + count);
count = getCountLength3UsingJava7(strings);
System.out.println("字符串长度为 3 的数量为: " + count);
// 删除空字符串
List<String> filtered = deleteEmptyStringsUsingJava7(strings);
System.out.println("筛选后的列表: " + filtered);
// 删除空字符串,并使用逗号把它们合并起来
String mergedString = getMergedStringUsingJava7(strings,", ");
System.out.println("合并字符串: " + mergedString);
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
// 获取列表元素平方数
List<Integer> squaresList = getSquares(numbers);
System.out.println("平方数列表: " + squaresList);
List<Integer> integers = Arrays.asList(1,2,13,4,15,6,17,8,19);
System.out.println("列表: " +integers);
System.out.println("列表中最大的数 : " + getMax(integers));
System.out.println("列表中最小的数 : " + getMin(integers));
System.out.println("所有数之和 : " + getSum(integers));
System.out.println("平均数 : " + getAverage(integers));
System.out.println("随机数: ");
// 输出10个随机数
Random random = new Random();
for(int i=0; i < 10; i++){
System.out.println(random.nextInt());
}
System.out.println("使用 Java 8: ");
System.out.println("列表: " +strings);
count = strings.stream().filter(string->string.isEmpty()).count();
System.out.println("空字符串数量为: " + count);
count = strings.stream().filter(string -> string.length() == 3).count();
System.out.println("字符串长度为 3 的数量为: " + count);
filtered = strings.stream().filter(string ->!string.isEmpty()).collect(Collectors.toList());
System.out.println("筛选后的列表: " + filtered);
mergedString = strings.stream().filter(string ->!string.isEmpty()).collect(Collectors.joining(", "));
System.out.println("合并字符串: " + mergedString);
squaresList = numbers.stream().map( i ->i*i).distinct().collect(Collectors.toList());
System.out.println("Squares List: " + squaresList);
System.out.println("列表: " +integers);
IntSummaryStatistics stats = integers.stream().mapToInt((x) ->x).summaryStatistics();
System.out.println("列表中最大的数 : " + stats.getMax());
System.out.println("列表中最小的数 : " + stats.getMin());
System.out.println("所有数之和 : " + stats.getSum());
System.out.println("平均数 : " + stats.getAverage());
System.out.println("随机数: ");
random.ints().limit(10).sorted().forEach(System.out::println);
// 并行处理
count = strings.parallelStream().filter(string -> string.isEmpty()).count();
System.out.println("空字符串的数量为: " + count);
}
private static int getCountEmptyStringUsingJava7(List<String> strings){
int count = 0;
for(String string: strings){
if(string.isEmpty()){
count++;
}
}
return count;
}
private static int getCountLength3UsingJava7(List<String> strings){
int count = 0;
for(String string: strings){
if(string.length() == 3){
count++;
}
}
return count;
}
private static List<String> deleteEmptyStringsUsingJava7(List<String> strings){
List<String> filteredList = new ArrayList<String>();
for(String string: strings){
if(!string.isEmpty()){
filteredList.add(string);
}
}
return filteredList;
}
private static String getMergedStringUsingJava7(List<String> strings, String separator){
StringBuilder stringBuilder = new StringBuilder();
for(String string: strings){
if(!string.isEmpty()){
stringBuilder.append(string);
stringBuilder.append(separator);
}
}
String mergedString = stringBuilder.toString();
return mergedString.substring(0, mergedString.length()-2);
}
private static List<Integer> getSquares(List<Integer> numbers){
List<Integer> squaresList = new ArrayList<Integer>();
for(Integer number: numbers){
Integer square = new Integer(number.intValue() * number.intValue());
if(!squaresList.contains(square)){
squaresList.add(square);
}
}
return squaresList;
}
private static int getMax(List<Integer> numbers){
int max = numbers.get(0);
for(int i=1;i < numbers.size();i++){
Integer number = numbers.get(i);
if(number.intValue() > max){
max = number.intValue();
}
}
return max;
}
private static int getMin(List<Integer> numbers){
int min = numbers.get(0);
for(int i=1;i < numbers.size();i++){
Integer number = numbers.get(i);
if(number.intValue() < min){
min = number.intValue();
}
}
return min;
}
private static int getSum(List numbers){
int sum = (int)(numbers.get(0));
for(int i=1;i < numbers.size();i++){
sum += (int)numbers.get(i);
}
return sum;
}
private static int getAverage(List<Integer> numbers){
return getSum(numbers) / numbers.size();
}
}
执行以上脚本,输出结果为:
$ javac Java8Tester.java
$ java Java8Tester
使用 Java 7:
列表: [abc, , bc, efg, abcd, , jkl]
空字符数量为: 2
字符串长度为 3 的数量为: 3
筛选后的列表: [abc, bc, efg, abcd, jkl]
合并字符串: abc, bc, efg, abcd, jkl
平方数列表: [9, 4, 49, 25]
列表: [1, 2, 13, 4, 15, 6, 17, 8, 19]
列表中最大的数 : 19
列表中最小的数 : 1
所有数之和 : 85
平均数 : 9
随机数:
-393170844
-963842252
447036679
-1043163142
-881079698
221586850
-1101570113
576190039
-1045184578
1647841045
使用 Java 8:
列表: [abc, , bc, efg, abcd, , jkl]
空字符串数量为: 2
字符串长度为 3 的数量为: 3
筛选后的列表: [abc, bc, efg, abcd, jkl]
合并字符串: abc, bc, efg, abcd, jkl
Squares List: [9, 4, 49, 25]
列表: [1, 2, 13, 4, 15, 6, 17, 8, 19]
列表中最大的数 : 19
列表中最小的数 : 1
所有数之和 : 85
平均数 : 9.444444444444445
随机数:
-1743813696
-1301974944
-1299484995
-779981186
136544902
555792023
1243315896
1264920849
1472077135
1706423674
空字符串的数量为: 2