一、什么是交并比?
1、交并比(IOU)概述
交并比(Intersection over Union) 是一种评估指标,用于衡量目标检测器在特定数据集上的准确性。任何提供预测边界框作为输出的算法都可以使用 IoU 进行评估。
只要有测试集手工标记的边界框和我们模型预测的边界框。就可以计算交并比。
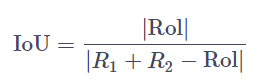
- R1:真实的边界框矩形的范围;
- R2:预测出来的矩形的范围;
- Rol:R1和R2重合的范围。
如下图所示

IOU值体现了单个对象预测的准确性。 一般来说,如果 IOU 分数 > 0.5,则认为它是一个很好的注释。不过,这还是因项目而异。

2、计算交并比(IOU)
参考代码
import numpy as np
# get IoU overlap ratio
def iou(a, b):
# get area of a
area_a = (a[2] - a[0]) * (a[3] - a[1])
# get area of b
area_b = (b[2] - b[0]) * (b[3] - b[1])
# get left top x of IoU
iou_x1 = np.maximum(a[0], b[0])
# get left top y of IoU
iou_y1 = np.maximum(a[1], b[1])
# get right bottom of IoU
iou_x2 = np.minimum(a[2], b[2])
# get right bottom of IoU
iou_y2 = np.minimum(a[3], b[3])
# get width of IoU
iou_w = iou_x2 - iou_x1
# get height of IoU
iou_h = iou_y2 - iou_y1
# get area of IoU
area_iou = iou_w * iou_h
# get overlap ratio between IoU and all area
iou = area_iou / (area_a + area_b - area_iou)
return iou
# [x1, y1, x2, y2]
a = np.array((50, 50, 150, 150), dtype=np.float32)
b = np.array((60, 60, 170, 160), dtype=np.float32)
print(iou(a, b))
计算如下两个矩形的交并比
a = np.array((50, 50, 150, 150), dtype=np.float32)
b = np.array((60, 60, 170, 160), dtype=np.float32)输出
0.627907
可视化


二、评估模型整体的准确性
上面说IOU是单个对象预测的准确性评价,但是对于整体模型或者说任务,怎么评价其识别的好坏呢?这就引出了下面的F1分数/F2分数/F3分数等。
1、基础概念
(1)TP/TN/FN/FP
在评估模型在指定数据集上的得分之前,让我们先了解一些术语:
True Positive (TP):正确绘制的 IOU 分数 > 0.5 的注释。
True Negative (TN): 当不需要注释时,不绘制注释。
False Negative (FN): 当需要注释时,不绘制注释。
False Positive (FP): 这些是错误绘制的注释,其 IOU 分数 <0.5。
可以从分类的角度来对比理解下:
- TP:被模型预测为好瓜的好瓜(是真正的好瓜,而且也被模型预测为好瓜)
- TN:被模型预测为坏瓜的坏瓜(是真正的坏瓜,而且也被模型预测为坏瓜)
- FN:被模型预测为坏瓜的好瓜(瓜是真正的好瓜,但是被模型预测为了坏瓜)
- FP:被模型预测为好瓜的坏瓜(瓜是真正的坏瓜,但是被模型预测为了好瓜)
(2)准确率(Accuary)
使用准确度方法来衡量我们的模型的性能。准确性是衡量任务性能最直观的方法,因为它只是正确绘制的注释与总预期注释的比率。

虽然准确性很直观也简单,但它也是最缺乏洞察力的。在大多数现实生活中,存在严重的类不平衡,并且没有考虑 FN 和 FP,这可能导致偏见或错误结论。
(3)精确度(Precision)
精度是正确绘制的注释与绘制的注释总数的比率。

(4)召回率(Recall)
召回率是正确绘制的注释与注释总数的比率。

2、什么是F-score?
(1)F分数概述
F-score(也叫F-measure)常用于信息检索领域,用于衡量搜索、文档分类和查询分类性能。F-score 也用于机器学习。F-score 已广泛用于自然语言处理文献,例如命名实体识别和分词的评估。
F分数使用精度和召回率来衡量测试的准确性。
F-score的一般公式如下:

对于F1分数,β=1;对于F2分数, β=2;依此类推。
sklearn.metrics提供了测量fbeta_score分数的函数。
(2)F1分数
F1分数是 Precision 和 Recall 的调和平均值,可以更好地衡量不正确的注释情况。
# calculate the f1-measure
from sklearn.metrics import fbeta_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
# perfect precision, 50% recall
y_true = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
y_pred = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
p = precision_score(y_true, y_pred)
r = recall_score(y_true, y_pred)
f = fbeta_score(y_true, y_pred, beta=1.0)
print('Result: p=%.3f, r=%.3f, f=%.3f' % (p, r, f))(3)F2分数
F2分数背后的直觉是它对召回率的权重高于精度。
# calculate the f2-measure
from sklearn.metrics import fbeta_score
from sklearn.metrics import f1_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
# perfect precision, 50% recall
y_true = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
y_pred = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
p = precision_score(y_true, y_pred)
r = recall_score(y_true, y_pred)
f = fbeta_score(y_true, y_pred, beta=2.0)
print('Result: p=%.3f, r=%.3f, f=%.3f' % (p, r, f))