文章目录
写在前面:《水文》;月刊;中文核心期刊
这一篇论文和我之前看的一篇专利是对应的。
专利链接:https://blog.csdn.net/weixin_42521185/article/details/124959089

1 摘要
- 方法:基于单场降雨类型直方图 分析的降雨站点相似性比较模型
- 重点是:选择和提取单场降雨特征,然后使用K-mean聚类分析
2 结论
- 陈晓宏等,在东江流域对降雨时空分布的研究较多,将模式分类引入降雨分析。
- 本文则从 单场降雨过程 切入,基于降雨数据本身的特性分析,综合降雨时间序列的多个统计特征,利用基于 D-B指数的 K-means 聚类算法,首次建立了基于单场降雨类型直方图分析降雨站点相似性比较模型。
3 引言
-
降雨序列实质是不连续的时间序列,此前(2012年前)大多研究都是基于单纯日、月或年降雨量累积的宏观统计分析,没有从更细粒度分析单场降雨的统计特征。
-
若单纯利用年降雨量的累计而不考虑单场降雨的具体情况,则无法区分一年内两个站点降雨类型的差异, 更无法区分降雨时空分布等信息; 若考虑单场降雨, 则可分析更多具有区分度的降雨信息,包括单场降雨和, 单场降雨日均值 ,大于或小于某个临界值的日降雨量, 单场降雨天数等。
-
目前国内对单场降雨序列的相似性研究基本是空白,但是单场降雨能够包含更多细节性的过程信息,因此基于单场降雨对各种特征量进行统计分析。
-
通过研究基于单场降雨的降雨序列相似性,继而探索区域降雨的相似性方法。

4 实验流程
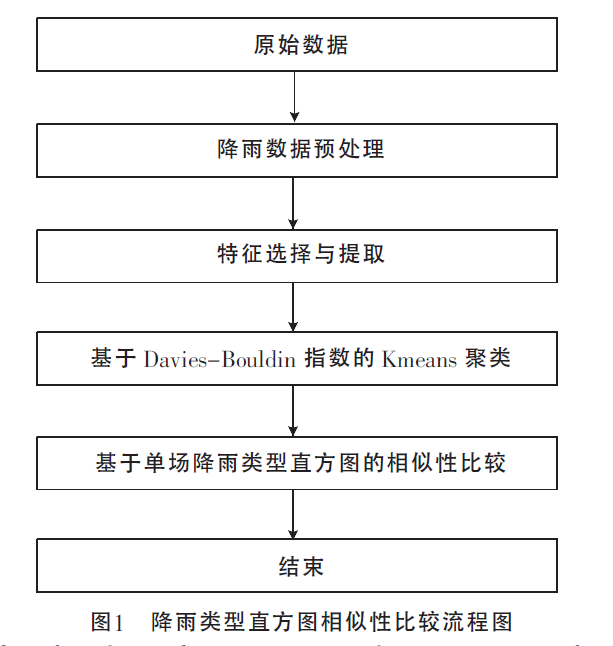
4.1 特征选择
- 选择9个基于单场降雨的特征统计量
(1)单场降雨总量
(2)单场降雨持续天数
(3)日平均降雨量
(4)日降雨量最大值
(5)日降雨量最小值
(6)日降雨量小于1.27mm
4.2 基于Dacies-Bouldin指数的K-means聚类
-
K-means算法存在一定局限性,如聚类数目K需要事先指定。

-
基于Davies-Bouldin指数的 K-means聚类算法,可以自动确定最佳聚类个数!!


4.3 基于单场降雨的降雨类型直方图
-
将基于 Davies-Bouldin 指数的K-means 聚类结果,得到的降雨类型分别看做一个单词,相同类别的单场降雨向量统计在相同的降雨类型袋中,这种新的模型被命名为降雨类型词袋模型。
-
每一个类别好所对应的降雨场次为bin 的频度值,每一个站点对应的各个类别降雨场次的组合构成直方图。
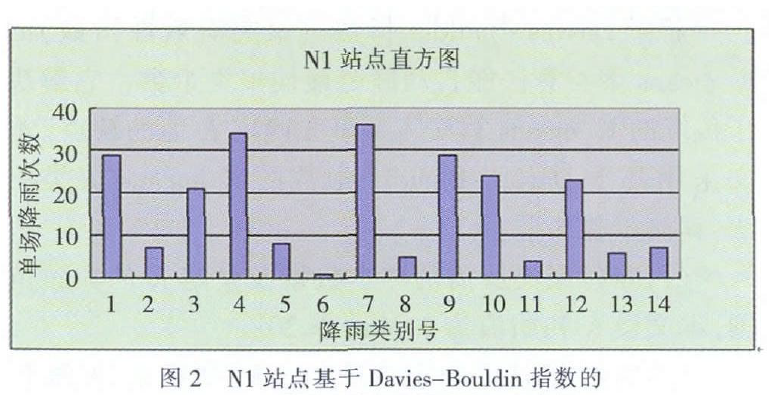
4.4 基于降雨类型直方图的相似性度量
-
得到降雨类型直方图后,需要进一步建立降雨站点间的相似性。
-
对所有站点都建立降雨类型直方图。
-
利用 直方图相交的方法 获取两站点之间的相似性。

5 实验结果与分析
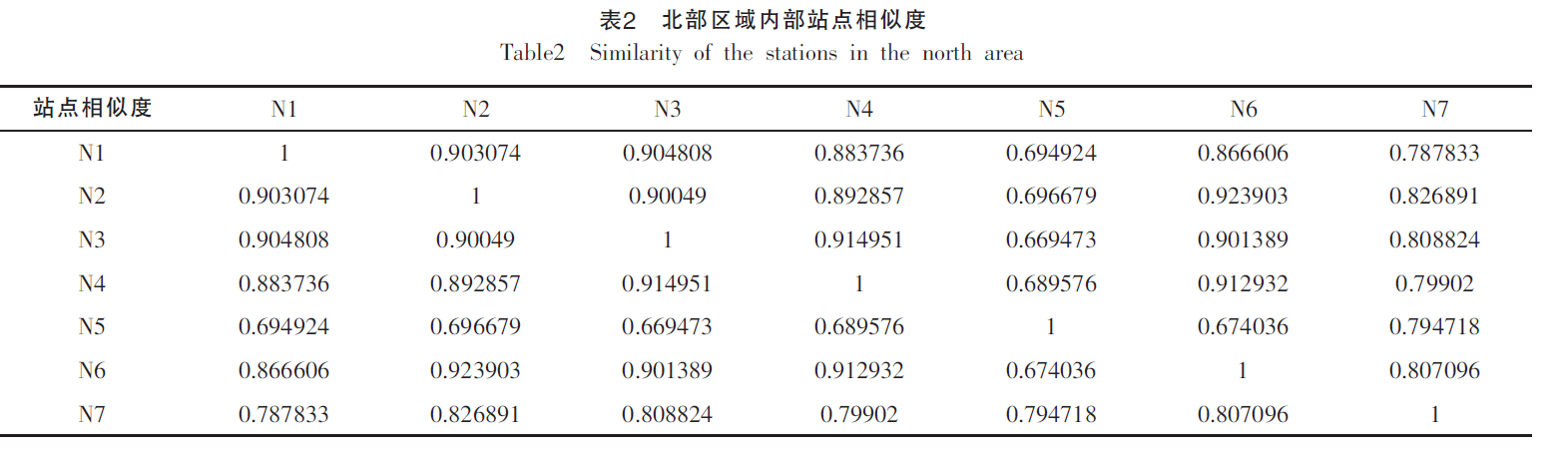
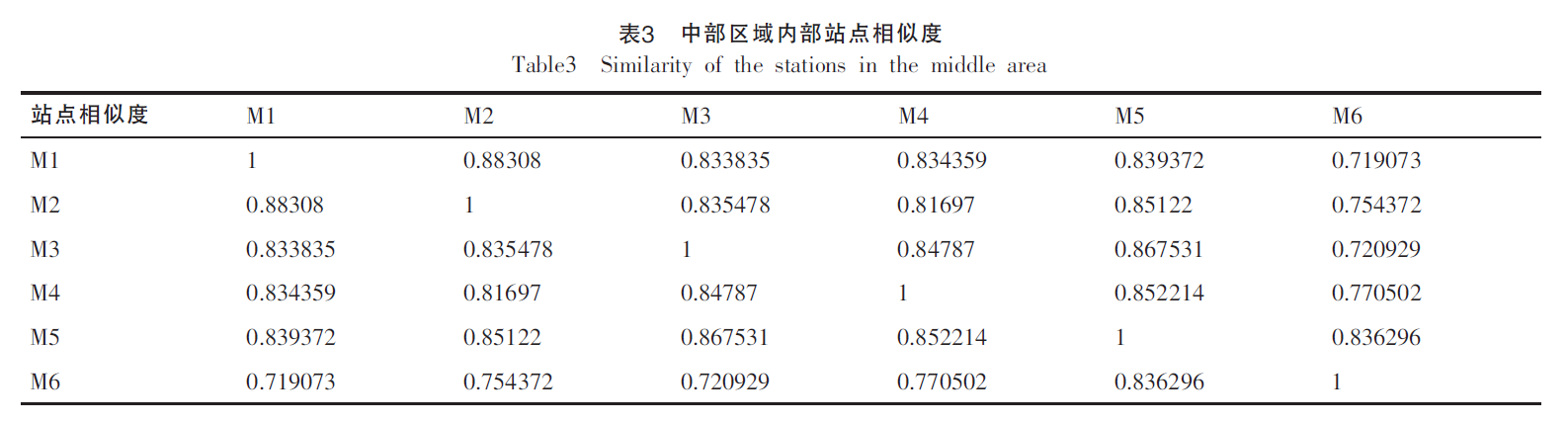
- 数据:江苏省的近十年水文数据(2001-2011),选择了北部、中部、南部三个区域的雨量站,分别是7个、6个、8个。 这些站点数据完整,且能代表江苏省 南、北、中 不同区域的降雨特点。
- 按照第四部分的内容,计算模型的相似度。

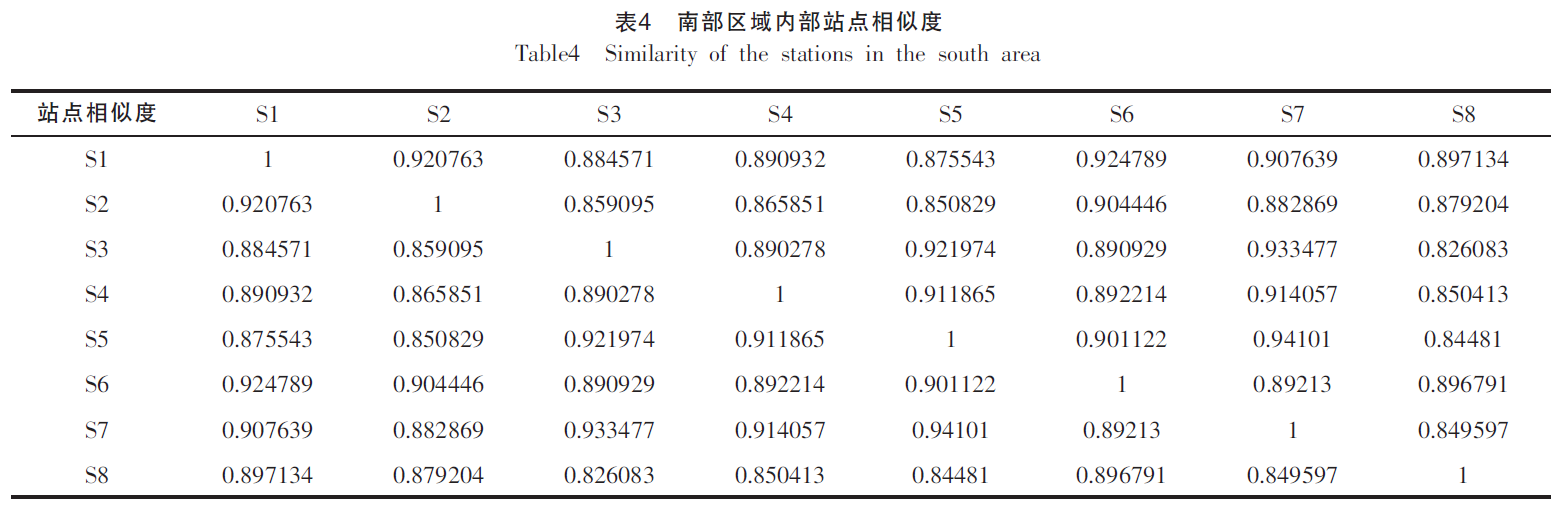
6 结论
- 不难发现,站点间 地理位置 和 长江流域南北 这两个因素是构成降雨相似性差异的主要原因。【以长江为分水岭,南北区域的降雨有较大差异】