基于C语言设计的增量型安全文件系统 SFS
引言
文件系统是计算机系统中为用户提供数据存储服务的一个很好的选择。然而,根据本文有限的调研,大部分通用文件系统在设计上都没有特别考虑文件的永久性存储。这里的永久性指的是,文件及其每一个版本都在底层存储介质上永久保存。因此,“删库跑路”等事故时有发生。例如,一个对高层不满的系统管理员可能会通过运行 rm -rf / 等命令来删除系统中的所有文件,从而表达他的不满。由于被上述命令删除的文件不难恢复,所以,稍有经验的系统管理员可能还会向文件系统写入垃圾数据来覆盖实际上未被清除的数据。此外,菜鸟系统管理员亦可能受到他人的教唆而运行这样的命令,为企业带来损失。此外,对于数据库系统等其他软件系统,也有同样的安全风险。虽然合理的权限控制可以缓解一部分问题,但拥有最高权限的系统管理员仍然是危险的。虽然可以针对特定应用,设计特定的操作日志等永久性记录,但这些方案不具有良好的灵活性,同时不能很方便地迁移到其他系统。对此,本文认为只有在文件系统层面对文件进行增量的、永久性的存储,才能够同时确保安全性、透明性以及灵活性。由此可见,一个能够对文件永久性存储的文件系统是必要的。
注意到 Git [Git. 2018]是一个能够跟踪每一个文件版本的版本控制系统,而 libfuse [libfuse. 2018]使得开发者可以很方便地开发文件系统,本项目在 Git 仓库的基础上利用 libfuse,设计并实现了一种增量型安全文件系统 SFS(Secure File System)。
本文分为这样几个部分:“相关工作”介绍了前人的已有工作,“功能设计”和“具体实现”介绍了本项目的设计与实现思路,“测试”部分给出了对于本项目方法的正确性测试和性能测试以及讨论。最后,“结论”一节对全文进行了总结。
相关工作
Git [Git. 2018]是一个能够跟踪每一个文件不同版本的版本控制系统。Libgit2 [libgit2. 2018]是一个 C 语言开发的操作 Git 仓库的函数库,提供了易于使用的接口方便开发者操作 Git 仓库。gitfs [presslabs. 2018]也是一个基于 Git 的文件系统,不过其核心功能在于让用户能够很方便地以文件系统的方式来访问 Git 仓库及其各个版本和分支。微软公司提出的 GVFS [Microsoft. 2018]同样是基于 Git 的文件系统,这个项目的关注点则在于访问大仓库时的性能,以及减少网络传输的数据量。Libfuse [libfuse. 2018]是一个用户态文件系统函数库,使得开发者可以在用户态开发及调试文件系统,而不用在内核态编写和调试内核模块。Fio [Jens Axboe. 2018]是一个灵活的性能测试工具,在本项目中被用来测试本项目的 I/O 性能。
功能设计
整体系统使用用户态文件系统 libfuse 实现,利用 libgit2 函数库操作 Git 仓库。
具体而言,一个使用 Git 管理的文件仓库可分为工作区、缓冲区和版本库三个部分。工作区即文件目录中直接可见的文件,缓冲区即调用 git add 后暂存的文件,版本库即 .git 目录中的信息。要使用 Git 实现文件系统,最简单的方式是将各项文件操作直接转发为对于工作区的文件操作,只有需要保存增量副本时,才调用 Git 程序将指定文件提交(在 Git 中,被称为 commit)到版本库。然而,这样实际上将每个文件在工作区和版本库中各存了一份副本,空间开销很大。为了优化空间开销,本项目选用 libgit2 函数库直接操作版本库。对于大多数操作,例如列出目录内容、获取文件属性等,可以直接在版本库中操作,而不必提取具体的文件到工作区。当打开(open)一个文件时,为了避免直接对版本库进行操作带来的额外时间开销以及不必要的复杂性,本项目将被打开文件的内容缓存到临时文件中。读(read)、写(write)、改变文件长度(truncate)操作直接对该临时文件进行;而关闭(release)时在版本库中直接构造一个提交(commit),包含该文件的最新内容,并删除该临时文件。
考虑到文件的打开与关闭操作可能比较频繁,而频繁地创建和删除临时文件可能开销过大,未来可以在关闭文件时不删除临时文件,而将临时文件作为版本库中文件的缓存,利用缓存淘汰算法(LRU 等),结合用户配置的最大缓存文件总量等参数来提升性能。
除了在关闭文件时保存增量副本(commit)以外,根据安全性的不同,版本控制的策略也可以有不同的选择。对于文件读写操作,本项目的设计目前支持如下三种版本控制策略:
commit-on-close:文件每次被关闭时,将缓冲区中的文件数据提交到 Git 仓库;timed-commit:可设定一个时间间隔,定时将缓冲区中的文件数据提交到 Git 仓库;commit-on-write:文件每次被写入后,将缓冲区中的文件数据提交到 Git 仓库;
以上三种策略的安全性能、时间和空间开销均依次增大。一般而论,commit-on-close 已经可以提供足够的安全性;对于安全性要求较高的场合,可以尝试 timed-commit,并根据安全性要求的不同,合理地选择时间间隔;commit-on-write 安全性最高,但由于开销过大,只适用于安全性要求极其严苛的场合。
对于其他写操作,包括创建目录、删除目录、创建文件、删除文件、修改文件权限以及重命名,每一次操作都会被提交到 Git 仓库。
此外,本项目还提供了一些人性化功能,例如:
- 在挂载时可以指定 SFS 回滚到某个指定时间之前的最新版本,SFS 会在此版本基础上新建一个分支继续存储,而不会改变原来的数据;
- SFS 可以以只读模式挂载,防止文件被误修改而带来的不必要的版本回退;
同时,我们的文件系统支持并发操作。
具体实现
相关术语
本小节解释了一些 libgit2 中出现的术语。
git_repository代表整个仓库;index可以认为是一个存储区,存放被git add命令记录的变更,被记录的文件的变更被添加到index;blob直接对应存放在仓库中的数据文件,可以认为是文件系统目录中的文件;oid指的是git_object的标识符,事实上是一个 SHA-1 值,20 个字节;tree是一个树形数据结构,tree_entry是这颗树的节点,可能是没有子节点的文件,也有可能是还有子节点的目录;commit即 Git 中的提交,一个commit与一颗tree有关,commit是整个仓库进行版本控制的基本单位,所有commit构成一幅有向图;reference/branch和 Git 中概念一致,是多个commit形成的链。branch可被认为是有名字的reference。它们在本质上是一致的,在libgit2的内部实现也是一致的。
FUSE 接口实现
本小节详细说明 FUSE 各个接口的具体实现。一般地,一个 FUSE 接口大致对应一个系统调用,但并非完全一致。
create
create 会在 Git 的 index 创建一个指定文件名的空文件,然后提交到 Git 仓库。
open
open 的语义为打开文件。前文提到,本项目使用临时文件的做法,因此 open 实现为从 Git 仓库读取一个文件的内容,并将其写入临时文件。同时,还维护打开的文件相关数据结构。
read
read 负责从文件中读取一块数据。读操作直接转发到对临时文件的读操作,提升了文件系统的性能,降低了开发复杂度。
write
write 负责向文件写入一块数据。首先,写操作会将数据写入临时文件。然后,根据版本控制策略配置的不同,若此次写操作需要被提交到 Git 版本库(开启了 commit-on-write 或 timed-commit 的时间间隔已达到),则会在版本库中利用临时文件中的最新数据构造一个 blob,添加到 index 中,最后在 Git 仓库创建一个提交。
release
在一个文件访问结束时,release 会被调用。前文提到,本项目使用临时文件的做法,因此 release 操作会在版本库中利用临时文件中的最新数据构造一个 blob,添加到 index 中,最后在 Git 仓库创建一个提交,并删除该临时文件。
同时,还清理打开的文件相关数据结构。
getattr
getattr 用于获取一个文件或目录的属性。访问权限、文件尺寸、是否为目录的信息,可以直接调用 libgit2 的接口获取。由于 Git 中不存储用户信息,为了保证挂载 SFS 的用户有权访问其中的内容,我们令某文件的所属用户和所属用户组与 Git 仓库(.git)目录一致。这样做有两点好处:如果此 Git 仓库是原来就存在的,这样可以避免无权用户访问此分区;如果此 Git 仓库是挂载时创建的,也能令挂载者成为此分区的属主。此外,Git 不存储根目录信息,因此令根目录的所有属性也与 Git 仓库目录一致。
readdir
readdir 列出一个目录中的所有文件或子目录的文件名和属性。调用 libgit2 的遍历 tree 函数,使其只遍历某一层目录,而不进行递归即可。遍历到目录中的每个文件或子目录时,收集其文件名和属性。
unlink
unlink 主要实现删除文件的文件功能,具体到 Git 实现如下:从仓库 repository 中取得代表当前暂存区的数据结构指针 index;根据文件的路径 path,移除 index 中相关项;最后把修改过后的 index 重建为 tree,更新到仓库的 commit 中即可。
truncate
truncate 主要实现修改文件大小的功能,单位为字节,若文件小则截断尾部多余的字节,反之则填充 0。最初的简要实现是利用 mktemp 系统调用把当前文件备份到临时文件,修改临时文件满足要求后提交改到到 Git 的 commit 中。上述操作会对造成磁盘读取不必要的性能损失,我们注意到 libgit2 中代表文件的结构 blob 可以从内存中创建,这样我们只需要把原始文件的 blob 载入到内存中,通过 memcpy 等操作即可完成对文件大小的修改并避免多余的磁盘读写操作。
rename
rename 主要实现文件及文件夹名字的修改,具体到 Git 实现如下:取出该路径对应的 entry,判断输入路径对应的是一个文件还是文件夹。若输入路径对应一个文件,则将原文件对应的 entry 从 index 中删除,并将新 entry 插入 index,新 entry 中除路径名(path)之外的其他成员变量都与原 entry 一致,路径名(path)改为输入中修改后的路径;若输入路径对应一个文件夹,则要在 index 里寻找所有以输入路径为 path 的前缀的 entry,又由于所有 entry 在 index 中的存储是有序的(以 path 为关键字),所以只需要调用函数找到下标最小的、以输入路径为 path 的前缀的 entry,之后不断地将下标增加一,直到某个 entry 的 path 的前缀不再是输入路径即可,之后就将找到的原 entry 都删除,新 entry 插入 index 即可。
mkdir 与 rmdir
mkdir 和 rmdir 用户增删目录。由于 Git 不将目录当作文件,而只是保存仓库中各个文件的路径,这造成:1. 一个目录中至少有一个文件;2. 增删文件时,其所属目录可以自动被增删。所以 mkdir 只需在目录中创建一个特殊文件;rmdir 只需先检查目录中是否只剩下该特殊文件,若是再将该文件删除即可。我们在 FUSE 的各个接口处对所涉及的文件名做了转义,使用户不可能访问或操作此特殊文件,此特殊文件对用户实际上是透明的。
版本控制
在配置文件中设置类似与 %d-%d-%d %d:%d:%d 格式回滚的时间,即可回到距离时间最近的一次版本。回滚后我们会新开一个分支来表示当前的工作区,而使历史版本不至于丢失。具体来说,实现如下:
- 通过
branch_iterator遍历所有分支,顺便统计出分支数目用以命名新的分支; - 对于每个分支从后往前寻找满足时间要求的
commit,记录最小值; - 找到最近的
commit,据此建立新的branch,将HEAD指过去; - 更新
index为HEAD所指向的tree。
整个过程最难的部分在于更新 index,类似的操作可以用 Git 中的 git reset 和 git checkout 完成,libgit2 中也有类似的函数接口。可调用了接口却没有任何效果,经过多方排查和阅读原码,猜测可能是 reset 和 checkout 都会对两个 commit 之间不同文件的工作区和暂存区进行操作,而我们的架构设计中没有工作区的这可能函数不能正常工作,于是我们简要的自己实现 reset 功能才到达了目的。
需要注意的是,在 libgit2 中表示时间使用的是 time_t,其含义是 1970 年 1 月 1 日 0 时 0 分 0 秒到某一时刻的秒数。time_t 数据类型本质上是 long 类型,它所表示的时间不能晚于 2038 年 1 月 18 日 19 时 14 分 07 秒。
路径转义
由于 Git 仓库中不能保存特定文件名的文件,例如名为 .git 的文件,本项目在 FUSE 文件操作及其对应的 Git 仓库操作之间,加入了路径转义。对于各类文件和目录操作,路径转义将路径中的每一项附加一个前缀 $;特别地,在列目录操作时,返回给调用者的文件名是恢复后的文件名,即对于每一项,删除前缀 $。这样确保了 SFS 文件系统存放的文件均在 Git 仓库中以 $ 为前缀,此时 Git 仓库中的其他文件名可用于 SFS 文件系统记录元数据,例如 mkdir 与 rmdir 中提到的特殊文件。
测试
测试环境
libfuse:版本 2.9.4,使用apt install libfuse-dev安装;libgit2:版本 0.24.1,使用apt install libgit2-dev安装;fio:版本 2.2.10,使用apt install fio安装;- 其他必要的 GCC 工具链。
正确性测试
在分别实现并测试 SFS 的各个接口之后,我们使用在 SFS 上编译运行一个真实项目的方式,来测试 SFS 综合运行各个功能的正确性,以及处理并发请求的正确性。我们选用 ucore 这个微型操作系统作为测试样本,使用 make -j8 并行编译。编译可以顺利完成,且编译后 ucore 可以正常运行。
为了进一步测试 SFS 并发读写的正确性,我们使用 fio 测试工具,并发地读写 4 个文件,每个文件使用 8 个线程进行随机并发读写,利用 CRC32 校验和检查正确性。SFS 可以通过测试。
性能测试
我们使用 fio 进一步进行了性能测试。测试环境如下:
- 底层存储设备:机械硬盘(HDD),Hitachi HTS547564A9E384(JEDOA50A);
- 运行基准测试和 SFS 的底层文件系统:ext4;
- 为确保公平性,测试时开启了操作系统内核文件缓存(buffered mode),这是因为 SFS 内部使用了临时文件,而 fio 无法关闭这些临时文件的缓存;
- 写测试中,所有数据写入完毕后,调用
fsync强制写回底层存储设备。
实验结果
顺序读取 64MB - 带宽

顺序读取 64MB - 延迟

随机读取 4MB - 带宽

随机读取 4MB - 延迟

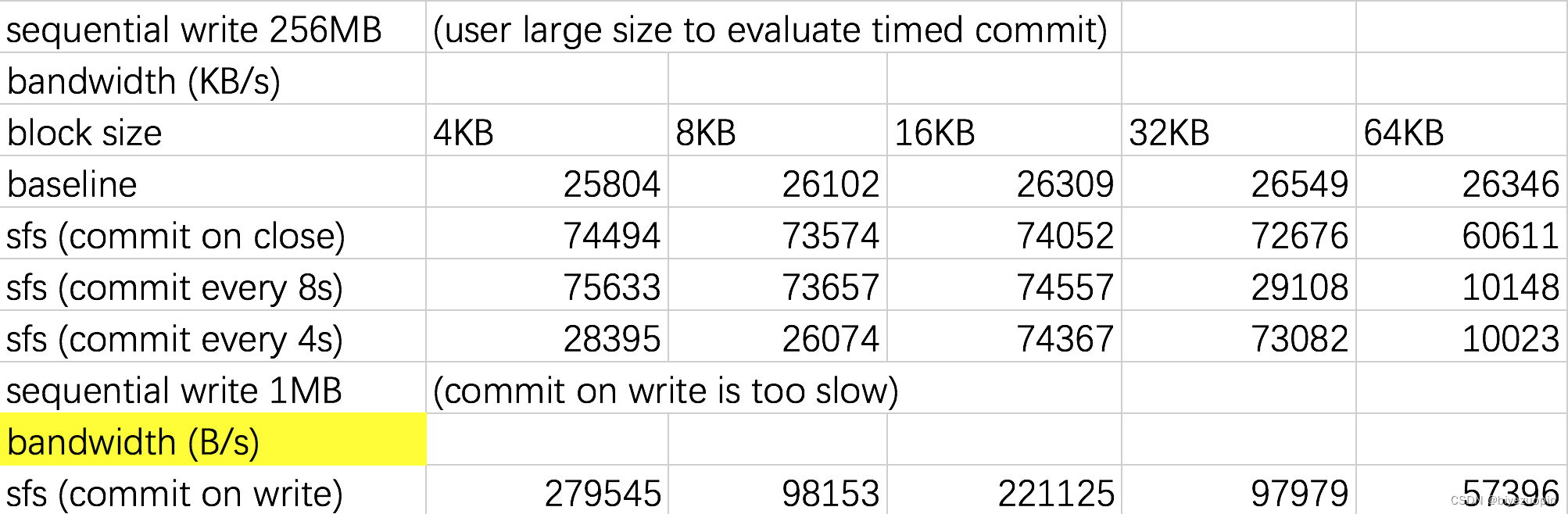
顺序写入 256MB - 带宽
注:由于 commit-on-write 性能相当差,仅对其写入 1MB。
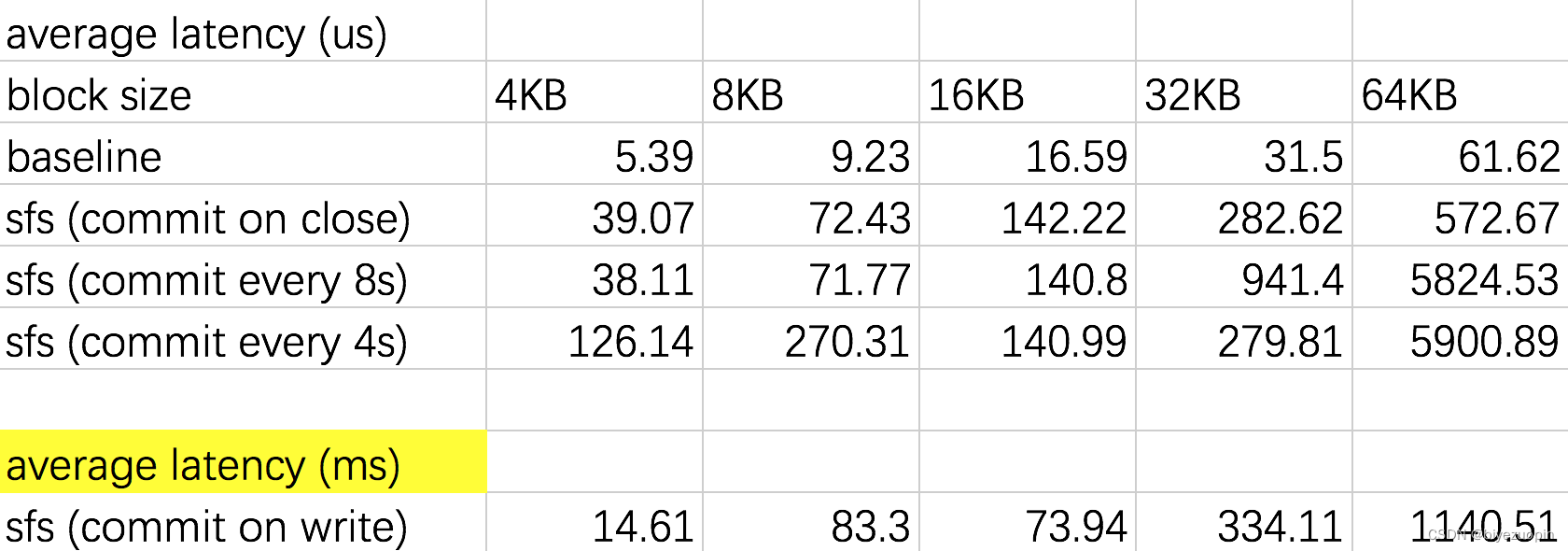
顺序写入 256MB - 延迟
注:由于 commit-on-write 性能相当差,仅对其写入 1MB。
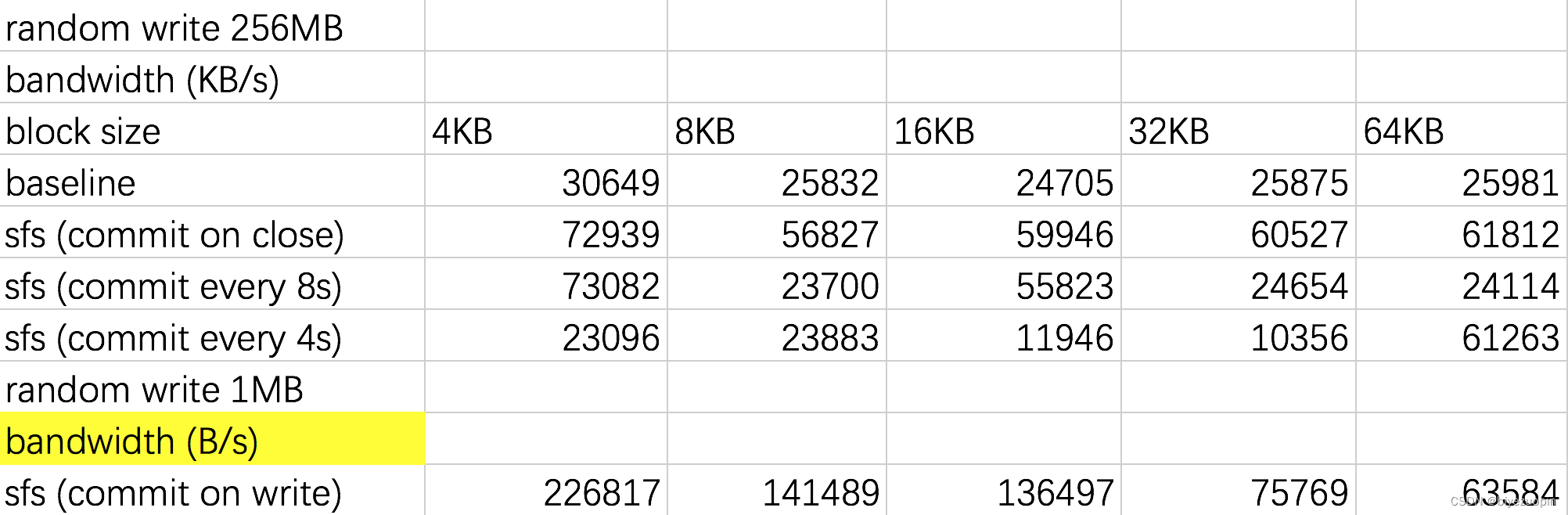
随机写入 256MB - 带宽
注:由于 commit-on-write 性能相当差,仅对其写入 1MB。
随机写入 256MB - 延迟
注:由于 commit-on-write 性能相当差,仅对其写入 1MB。
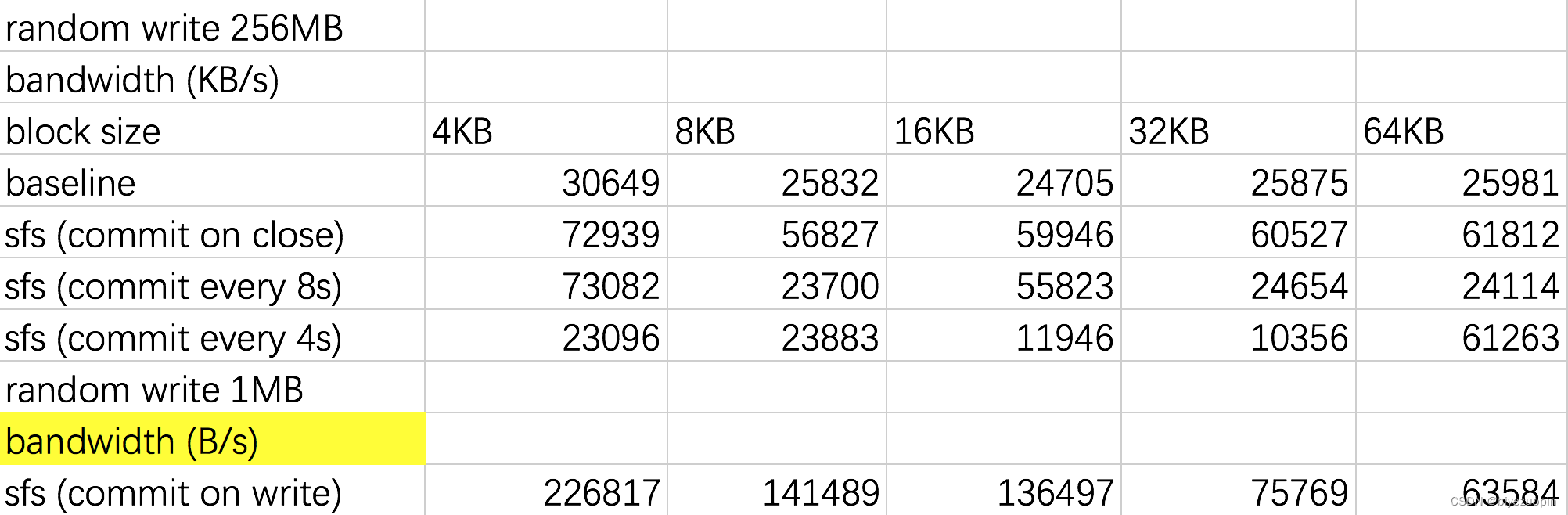
从上面的实验结果可以看出,对于 SFS 的文件操作的性能不比基准文件系统差,本文暂时无法解释此类情况。
对于写操作,分别开启 commit-on-close、timed-commit 以及 commit-on-write 后,带宽依次减小、延迟依次增大。特别地,对于 timed-commit,更小的提交间隔能导致带宽减小、延迟增大。这与上文的理论是相符的。