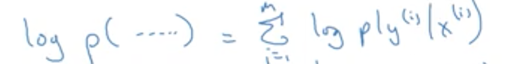课程来源:吴恩达 深度学习课程 《神经网络基础》
笔记整理:王小草
时间:2018年5月15日
1.什么是二分类
1.1 二分类?
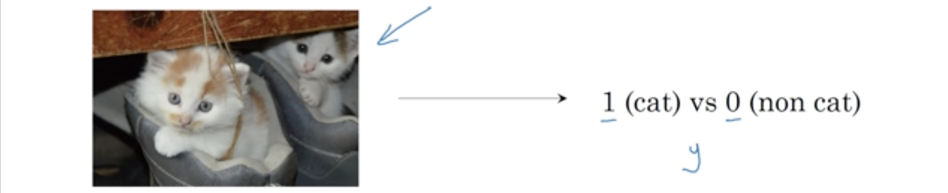
给定一张图片,要识别出这张图片,“是猫”或“不是猫“的问题就是二分类问题。
输入以x表示,输出以y表示。
如何表示图片:计算机是如何计算图片的呢?
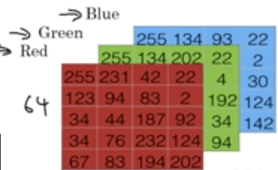
一张图片实际上由一堆像素构成,一堆像素可以由矩阵表示出来。如果你输入的是一张64*64像素的彩色图片,那么表示成三个64*64的矩阵(彩色图片有RGB三个通道,每个通道对应一个矩阵)
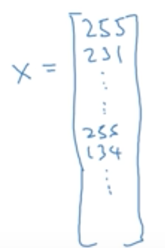
将这些像素亮度转换成一个向量形式的特征x。维度是64*64*3=12288的向量
讲特征向量输入模型,预测输出结果标签y是1还是0(比如1代表有猫,0代表无猫)
1.2 符号约定
定义一下接下去所有课程中都会统一用到的符号。
一个样本用(x,y)表示,x是nx维的实属向量,y是一个属于{0,1}集合内的整数
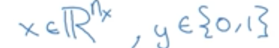
符号表示:
m个样本如下表示:
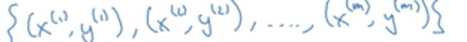
样本会分为训练集于测试集,训练集的数目用Mtrain表示,测试集的数目用Mtest表示。
矩阵表示:
用矩阵表示样本的特征x,每一列是一个样本特征,若有m个样本的话,每个样本有nx维的话,该矩阵就有nx * m大小
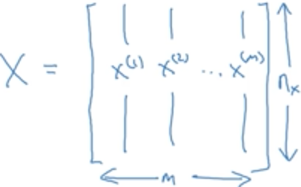
注:平时会每行放一个样本,但在神经网络中1列一个样本会更方便计算。
用矩阵表示样本的标签y,大小为1 * m的矩阵
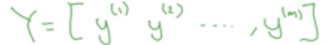
2.logistic回归
对于二分类,输入特征向量x, 期望输出一个概率,根据这个概率去判断是输出1还是0.
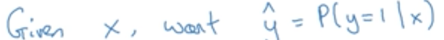
那要选择什么样的函数或模型,去做二分类呢?若使用线性函数:
参数:
输出: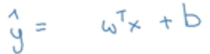
可见输出的y并非是一个0-1之间的概率,因此不能选用。
于是逻辑回归在线性函数的外面又加了一层sigmoid函数:
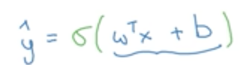
sigmoid函数长这样:
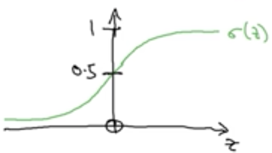
将线性函数的输出作为z,即sigmoid函数的输入。而sigmoid的输出是分布再[0,1]之间的值,符合概率取值。
sigmoid函数的公式:
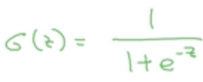
如果z越大,则simoid输出越接近于1
如果z越小,则simoid输出越接近于0
3.logistic回归损失函数
要通过训练得到w,b两个参数的正确值,则需要损失函数。
回顾逻辑回归的函数:
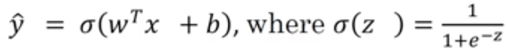
给出一组样本{(x{1),y(1)),…,(x(m),y(m))},希望得到y^ ≈ y。 (y^是以上逻辑回归函数的预测值,y是真实值)。
也就是希望去得到参数w,b,使得逻辑回归函数的预测与真实值尽量一致。而y^与y不一致的部分就成为损失。
针对单个样本的损失函数:
可以如下用误差平方和定义损失函数,但是再逻辑回归中不采取,因为这不是一个凸函数,梯度下降发求解时会有多个局部最优解。
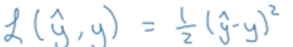
在逻辑回归中,我们使用交叉熵损失函数:
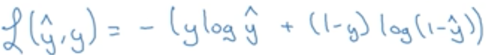
如何理解交叉熵损失函数呢?
当真实值y=1,则损失L(y^, y) = -logy^,要使损失越小,logy^希望越大,则y^需要越大,由于y^最大为1,则意味着越接近于真实值;
当真实值y=0,则损失L(y^, y) = -log(1-y^),要使损失越小,log(1-y^)希望越大,则y^需要越小,由于y^最大为0,则意味着越接近于真实值;
针对多个样本的成本函数:
成本函数是将每个样本的损失函数加起来求均值:
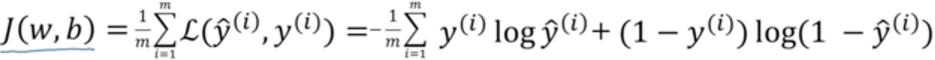
在训练模型得到参数的过程中,我们追求的是使成本函数降到最小。
4.梯度下降法 Gradient descent
要获取成本函数最小的时候的参数w,b,可以通过梯度下降法求解。
目标:
J(w,b)是成本函数,横坐标是参数w,b,也就是求这个凸函数最低点时的w,b值。
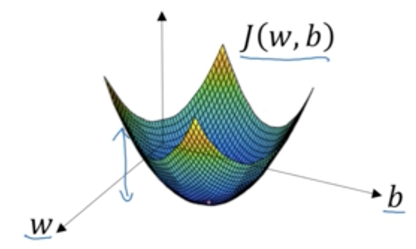
梯度下降法的步骤:
(1)首先随机初始化w,b的值
(2)然后针对每个样本重复以下过程:
更新w:w = w - a (dJ(w,b) / dw)
更新b:b = b - a (dJ(w,b) / db)
a是学习率, dJ(w,b) / dw是成本函数对w求偏导,dJ(w,b) / db是成本函数对b求偏导。
为何以上过程就可以求取成本函数的最小值呢?
如下图,纵轴是成本函数,横轴是参数w
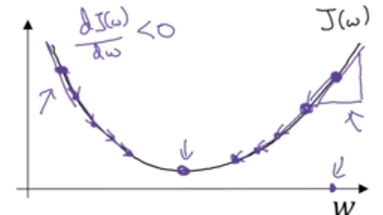
若当前w的取值在成本函数最低点对左侧,对w的导数为负,w = w - a (dJ(w,b) / dw)的运算后,新的w值会增加,即向右移动,更靠近最低点;
若当前w的取值在成本函数最低点对右侧,对w的导数为正,w = w - a (dJ(w,b) / dw)的运算后,新的w值会减少,即向左移动,更靠近最低点;
因此通过梯度下降法,参数会越来越接近成本函数最小值时的参数值。
5.导数基础知识
直线上的导数计算:
直线上所有位置导数相同
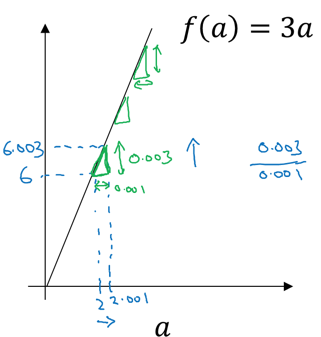
a = 2时:
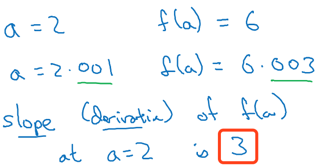
a = 5时:
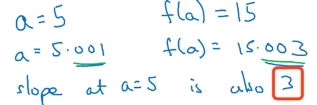
曲线上的导数计算:
曲线上不痛位置斜率不同
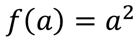
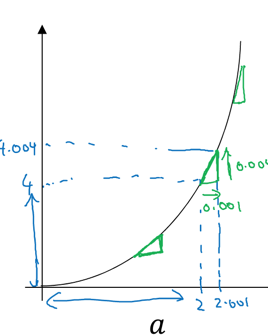
a = 2时:

a = 5时:
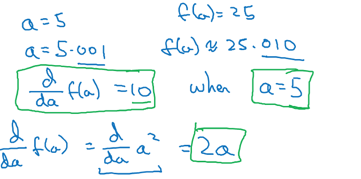
更多导数的例子:
平方:

三次方:
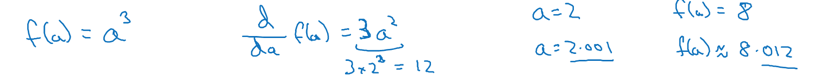
log:

6.计算图的导数计算
6.1 什么是计算图
神经网络可以用计算图表示,先前向计算,然后根据输出求损失与成本函数,再根据梯度反向传播。
先以一个小栗子来了解什么是计算图。
假设有一个函数J(a,b,c) = 3(a + bc),它的计算步骤应该是:
u = bc
v = a + u
J = 3v
将着3步画成计算图:
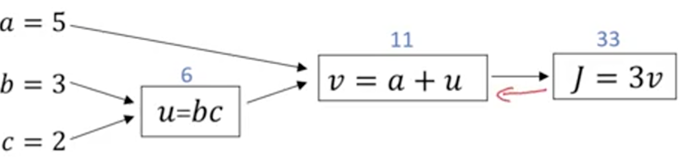
从左到右可以计算出函数J的值,若J是逻辑回归的成本函数,要求它最小值时的参数a,b,c,就可以用梯度下降法从右到左求梯度。
6.2计算图的导数计算
通过计算图求导数,其实就是求偏导的过程,因此课程中讲的细节不再这里赘述,对偏导若不懂,建议额外找资料来学习一下。
J(a,b,c) = 3(a + bc) 对a,b,c分别求偏导对结果如下:
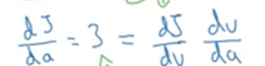
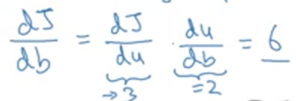
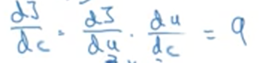
7.logistic回归中的梯度下降法
回顾逻辑回归与单个样本的损失函数:
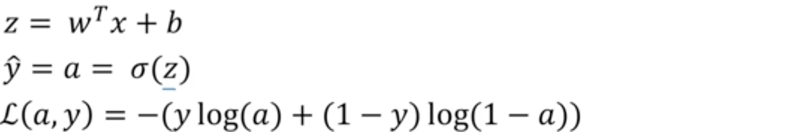
画出一个样本的计算图:
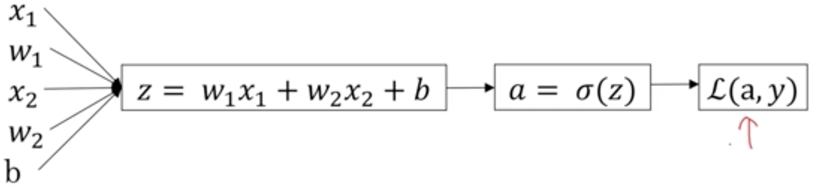
要使损失函数L(a,y)最小,通过对参数求偏导的梯度下降法,寻找最优的参数。
首先使L(a,y)对a进行求偏导
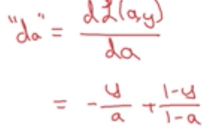
再向后一步计算,使L(a,y)对z求导
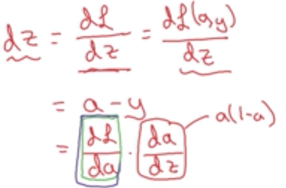
再向后一步,求L(a,y)对w1,w2,b的偏导
dw1 = x1*dz
dw2 = x2*dz
db = dz
有了偏导数之后,就可以进行梯度下降更新参数了:
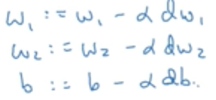
8.m个样本的梯度下降法
上面介绍的是对单个样本的梯度下降法,现在把它应用到m个样本上。
首先回归cost function成本函数:

再回顾逻辑回归的计算公式:(i表示第i个样本)
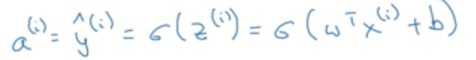
对成本函数进行求导,其实就是对m个样本分别求参数梯度,然后将所有m个样本对梯度求均值,作为最终对梯度区更新参数。
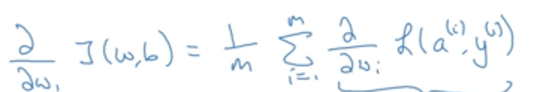
梯度下降过程:
(1)初始化参数dw1=0,dw2=0, db=0
(2)对每个参数求梯度,并求的最终参数
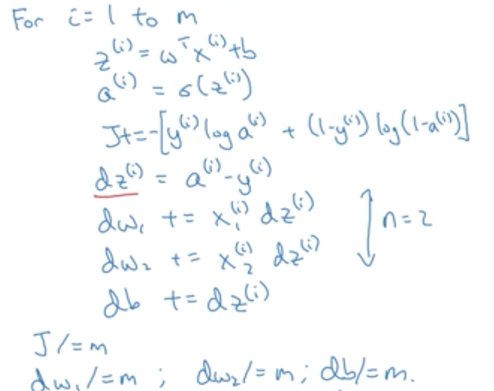
(3)利用梯度更新参数
(4)利用新的参数,重新前向计算损失函数,并重复(2)(3)两步,知道到达终止条件(迭代次数到了,或者损失小于给定阀值,或者参数的更新量小雨某个阀值等)
以上步骤的缺点:
对1-m个样本分别进行1-n次迭代的for循环计算量是非常庞大的。解决办法就是将数据向量化,从而拜托for循环。
10.向量化vectorization
向量化的好处是消除你代码中的for循环。
对于以下计算

若有x有n个维度,则也有n个w,对每个样本进行如上计算时,使用for循环需要n次计算:
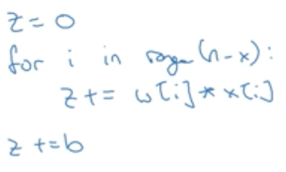
但若使用向量化,则只需要计算一次:(np.dot(w,x)是将w,x进行点乘
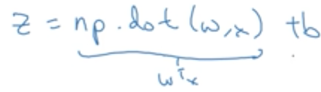
其他例子:
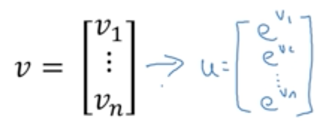
要从v转换成U,直接调用numpy中的exp()函数即可:
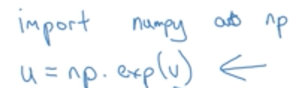
其他这样的函数还有求log,绝对值,最大值等等:
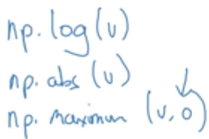
11.向量化logistict回归
当有m个样本的时候,我们需要去前向计算m次,对每个样本都计算z和a:
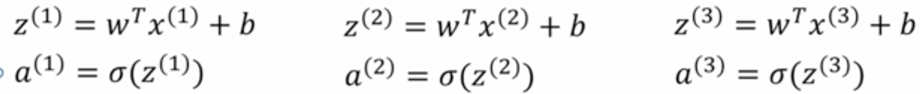
现在我们使用向量化的方法避免m次循环。
将样本特征x(i)向量化,定义一个矩阵X,每个向量的x是其一列,若每个x有n维特征,则改矩阵大小是(n*m)
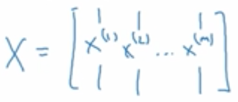
Z的向量计算
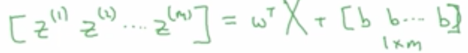
python代码一句搞定:z = np.dot(wT, x) + b
其中b是一个常数,但是由于它和一个vector相乘,就会自动广播成1 * m的vector,称其为广播变量。
A的向量计算

之久调用sigmoid函数即可。
12.向量化logistic回归的梯度输出
上面讲的是逻辑回归前向计算得到a的向量化计算过程,现在讲一讲求梯度的向量化计算过程。
dZ是所有dz(i)组成的向量:
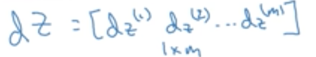
其中:
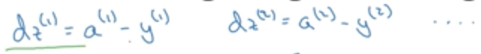
将所有a与y向量化:

于是dZ可以通过A,Y矩阵一次性求得:

db可以如下计算:
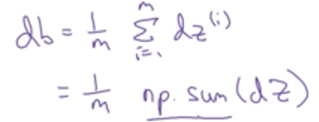
dw可以如下计算:
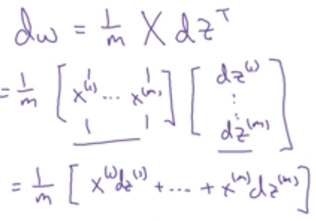
因此,如果不向量化计算,则代码如下:
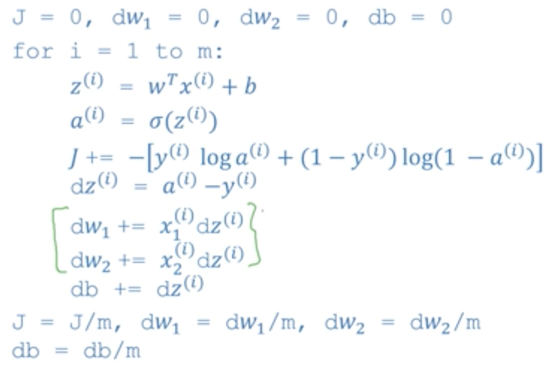
每次迭代都需要进行m次for循环
但如果使用向量化计算则代码如下:
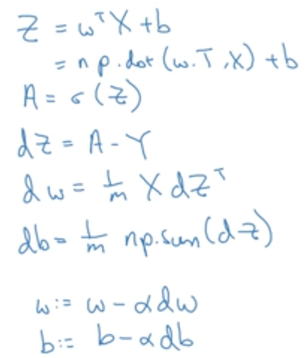
13.损失函数的解释
之前给出了逻辑回归得损失函数,现在来解释一下为什么逻辑回归的损失函数要用这种形式表达。
设y^是当y=1时得预测值:y^ = P(y=1/x)
if y=1: P(y/x) = y^
if y=0: P(y/x) = 1-y^
可见这是一个二项分布,用最大似然法求解二项分布:

因为上式是一个单调递增函数,因此可以转换成log形式
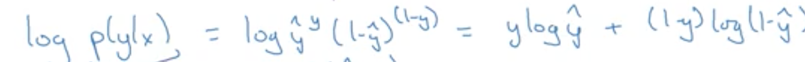
因为直观上希望损失越小越好,因此在上式基础上加上负号
推广到m个样本上:
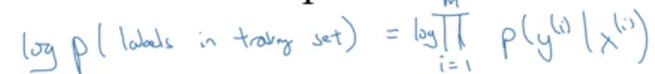
变形以下得到: