
目录
目标网站:
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=0
前置环境需求
pip3 config set global.index-url https://repo.huaweicloud.com/repository/pypi/simple
pip3 config list
pip3 install --upgrade pip
pip3 install requests
pip3 install scrapy
爬取需求:前五页的以下内容
1、课程标题
2、主讲人
3、章节数
4、学习时长
5、学习人数
6、课程简介
文件保存需求:
将5页内容的所有课程以每门课程一个【课程名称.txt】文件的方式进行保存。
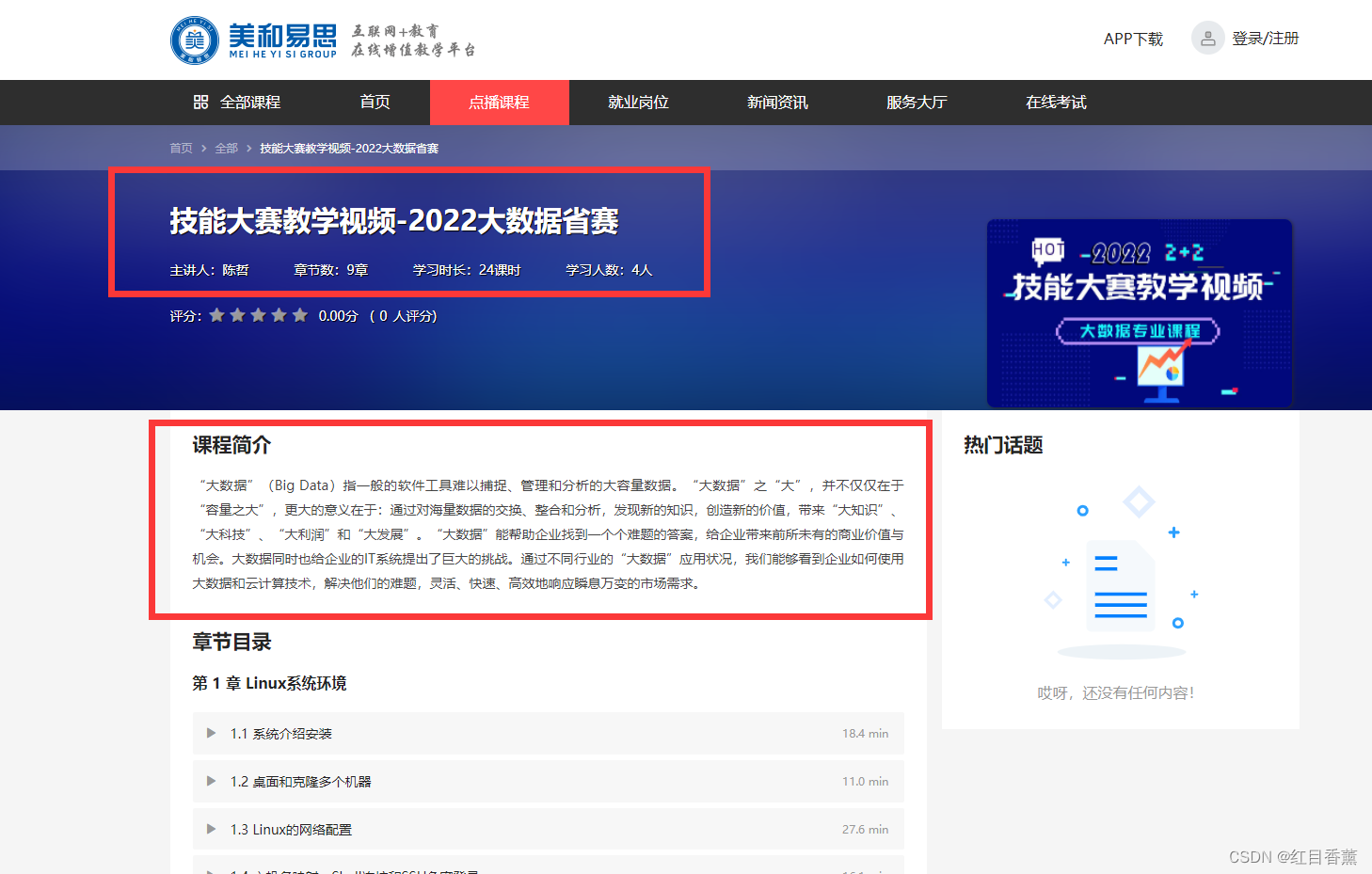
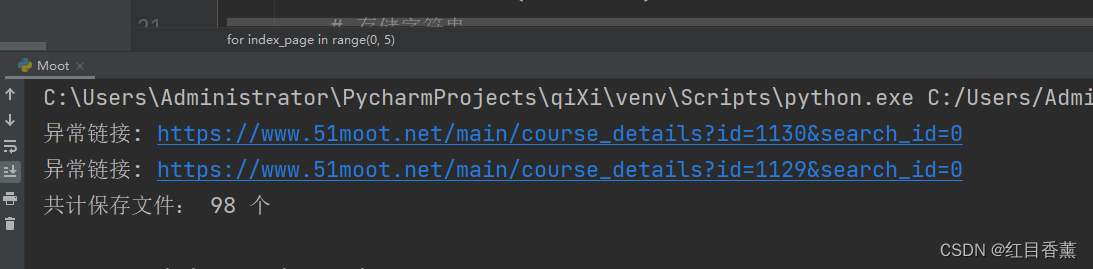
如果有异常链接:内容为空的try:except:跳过
页码逻辑:page_index=[0-4]
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=0
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=1
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=2
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=3
https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index=4
所以一个循环搞定。
HTML-CSS拆解:
第一层CSS拆解

第二层CSS拆解


示例编码:
import pathlib
import uuid
from requests import get
from scrapy.selector import Selector
# 域名
urlHttp = "https://www.51moot.net"
# 有效链接统计
count = 0
for index_page in range(0, 5):
html = get(
"https://www.51moot.net/main/course?search_id=0&is_free=-1&page_index={0}".format(index_page)).content.decode(
"utf-8")
sel = Selector(text=html)
result = sel.css("div.course-details-cont-view ul li a::attr(href)").extract()
for x in result:
# 添加域名
x = urlHttp + x
html = get(x).content.decode("utf-8")
sel = Selector(text=html)
# 存储字符串
strInfo = ""
title = sel.css("div.course-details-title-cont-text h2::text").extract()[0]
infos = sel.css(
"div.course-details-title-cont-text li.course-details-title-cont-text-chapter span::text").extract()
introduce = sel.css(
"div.course-details-view-list div.course-details-view-list-introduce-cont p::text").extract()[0]
strInfo += title + "\n"
strInfo += "主讲人:{0}\t章节数:{1}\t学习时长:{2}课时\t学习人数:{3}人\n".format(infos[0], infos[1], infos[2], infos[3])
strInfo += "课程简介:{0}".format(introduce)
# 有异常直接继续
try:
saveUrl = str.format("D:/save51Moot/{0}{1}", title, ".txt")
path = pathlib.Path(saveUrl)
if path.exists():
saveUrl = str.format("D:/save51Moot/{0}{1}{2}", title, uuid.uuid4(), ".txt")
file = open(saveUrl, "w", encoding="utf-8")
file.write(strInfo)
file.close()
count += 1
except:
print("异常链接:", x)
print("共计保存文件:", count, "个")
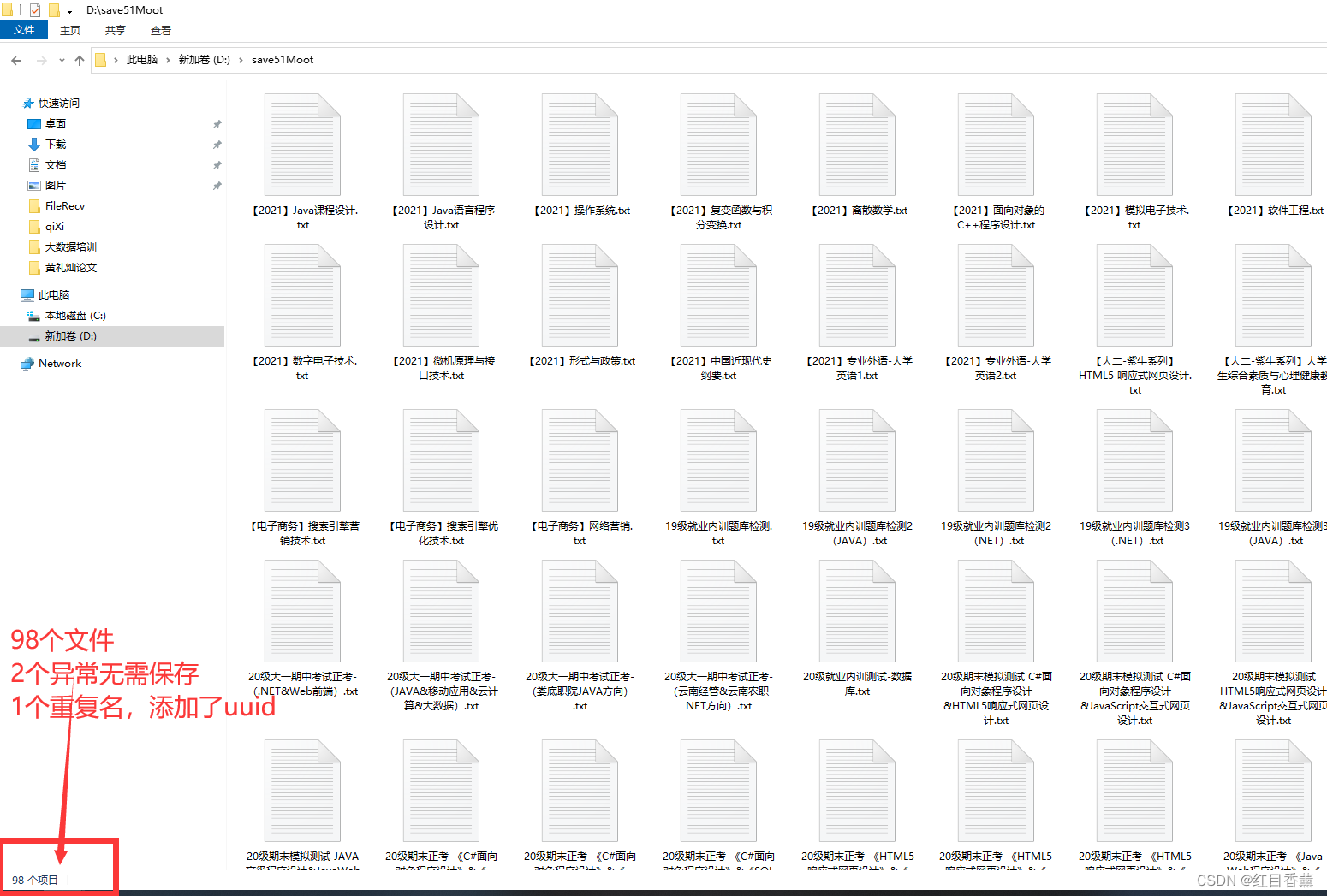 可以看到有一个多添加了uuid这样简单一些,我没做set去重。
可以看到有一个多添加了uuid这样简单一些,我没做set去重。

提交需求:
1、项目压缩包
2、截图,截图要求如下:
