1.backbone
Deformable detr 使用resnet 50作为主干网络,网络返回最后三层的结果,分别为下采样8/16/32倍的结果,输出维度为:

2.neck
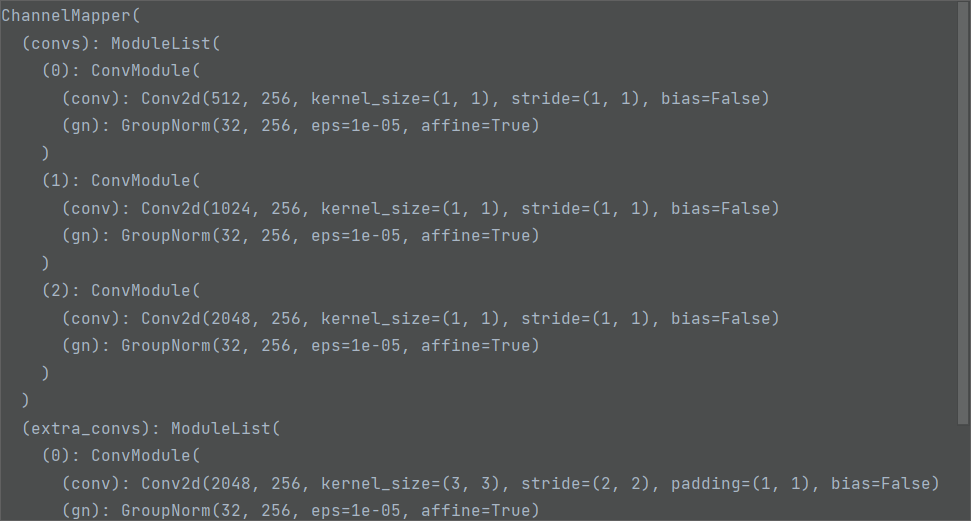
neck的主要作用为降低通道数,组成为3个1*1的卷积和1个3*3的卷积,将backbone输出结果通道数降为256 ,同时,对最后一层的结果再进行一次卷积,得到降低72倍的特征图(FPN),输出结果如下图所示:

3.head
head主要为transformer部分,主要包括ecoder和decoder
输入:head部分所需要的输入主要为图像信息和特征图信息
图像信息:
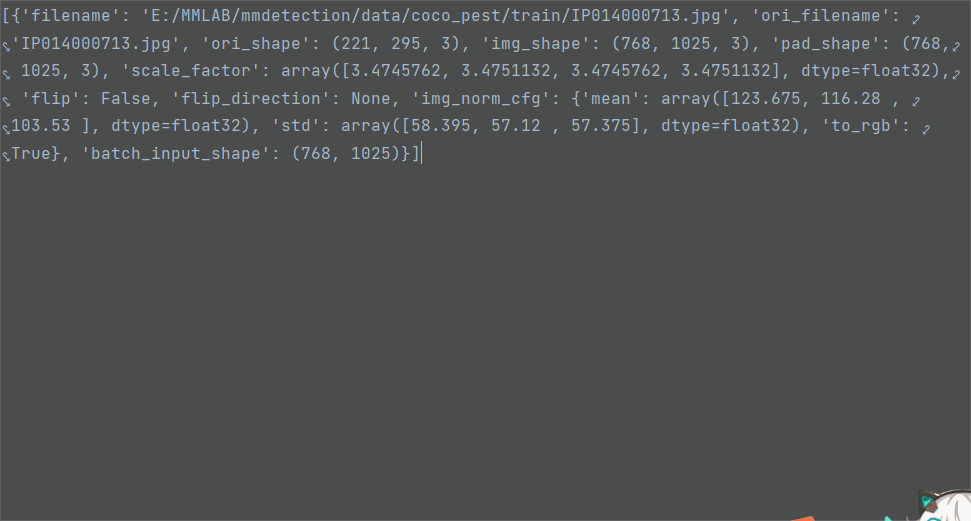
特征图信息:主要为neck输出的四层特征图的信息

encoder的准备
mask:创建一个与图像同样大小的mask,同时考虑到padding,对mask进行填充,然后对mask进行下采样,生成各层级特征图对应的mask。
位置编码:首先,对每个层级的特征图生成正弦位置编码,然后分别加入各层级level编码。
然后,对各层级的特征图进行展平,拼接成一个向量,并保留每个层级的特征图的索引。
reference_points:多特征融合,每一个特征点都是由四个特征点融合而来,如果相对位置坐标不存在实际的点,则通过双线性插值。
ecoder层
ecoder的value值是通过query全连接得到
偏移量:
偏移量也是通过query全连接得到,其中输入维度为256,输出维度为256,输出256表示的是有8个头,每个头有4个层级,每个层级做4个采样,每个采样的偏移量有两个。
偏移量的初始化采样为最近的四个点,例如:
Attention:Attention 权重也是query经过全连接得到,其中输出维度为128,即8个头,4个level和4个采样点。
偏移量对齐:将reference_points与上面得到的偏移量相减即可得到位置的偏移量对齐。
输出为bs*num_queries*8*8*4*2
ecoder的对齐:首先将相对位置坐标由[0,1]转为[-1,1],然后对每层特征图,经过双线性插值得到对应点的坐标。
def multi_scale_deformable_attn_pytorch(value, value_spatial_shapes,
sampling_locations, attention_weights):
"""CPU version of multi-scale deformable attention.
Args:
value (torch.Tensor): The value has shape
(bs, num_keys, mum_heads, embed_dims//num_heads)
value_spatial_shapes (torch.Tensor): Spatial shape of
each feature map, has shape (num_levels, 2),
last dimension 2 represent (h, w)
sampling_locations (torch.Tensor): The location of sampling points,
has shape
(bs ,num_queries, num_heads, num_levels, num_points, 2),
the last dimension 2 represent (x, y).
attention_weights (torch.Tensor): The weight of sampling points used
when calculate the attention, has shape
(bs ,num_queries, num_heads, num_levels, num_points),
Returns:
torch.Tensor: has shape (bs, num_queries, embed_dims)
"""
bs, _, num_heads, embed_dims = value.shape
_, num_queries, num_heads, num_levels, num_points, _ =\
sampling_locations.shape
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes],
dim=1)
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
for level, (H_, W_) in enumerate(value_spatial_shapes):
# bs, H_*W_, num_heads, embed_dims ->
# bs, H_*W_, num_heads*embed_dims ->
# bs, num_heads*embed_dims, H_*W_ ->
# bs*num_heads, embed_dims, H_, W_
value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape(
bs * num_heads, embed_dims, H_, W_)
# bs, num_queries, num_heads, num_points, 2 ->
# bs, num_heads, num_queries, num_points, 2 ->
# bs*num_heads, num_queries, num_points, 2
sampling_grid_l_ = sampling_grids[:, :, :,
level].transpose(1, 2).flatten(0, 1)
# bs*num_heads, embed_dims, num_queries, num_points
sampling_value_l_ = F.grid_sample(
value_l_,
sampling_grid_l_,
mode='bilinear',
padding_mode='zeros',
align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (bs, num_queries, num_heads, num_levels, num_points) ->
# (bs, num_heads, num_queries, num_levels, num_points) ->
# (bs, num_heads, 1, num_queries, num_levels*num_points)
attention_weights = attention_weights.transpose(1, 2).reshape(
bs * num_heads, 1, num_queries, num_levels * num_points)
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) *
attention_weights).sum(-1).view(bs, num_heads * embed_dims,
num_queries)
return output.transpose(1, 2).contiguous()decoder:
ecoder的输出为维度为 (hw,bs,256), 将维度变换为bs,hw,256;
对于decoder 的query,首先初始化300*512为向量,分为300*256维的query和300*256的position 向量,将position向量经过reference_points的计算,再经过sigmoid操作,表示初始化的位置编码。
将ecoder的输出与query,query pos 经过维度变换后,输入decoder中,此时注意力权重还是由query学习得到,因此没有key。
将query position也做与ecoder同样的操作,将query position转化为四个层级的特征图的相对位置。
Attention:
首先对query做self attention,做法与ecoder相同
cross_attention:
对300维的query,做相同的偏移,与经过偏移的ecoder的输出做Attention的计算。
最后对结果进行分类与回归。