Deformable DETR(2020 ICLR)
detr训练epochs缩小十倍,小目标性能更好
Deformable attention
-
结合变形卷积的稀疏空间采样和Transformer的关系建模能力
-
使用多层级特征层特征,不需要使用FPN的设计(直接使用backbone多层级输出)
两种提升方法:
- bbox迭代细化机制
- 2.两阶段Deformable DETR
整体结构:
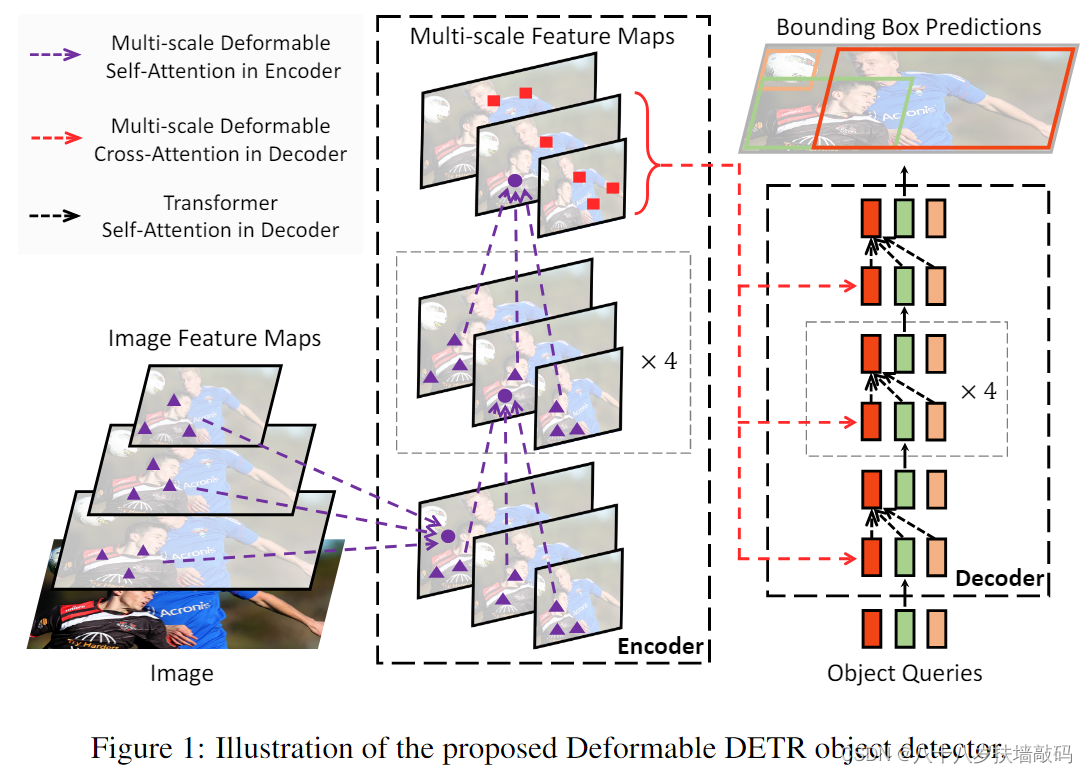
同样是6encoder,6decoder。
首先,运用了多层的图像特征,在一个采样点周围进行多层级的可变形注意力模块(紫色部分)
decoder用交叉注意力,红色的线指向第二个(cross,第一个是selfattention)
object query一样
详细展示
multihead-attention:
MultiHeadAttn ( z q , x ) = ∑ m = 1 M W m ⏟ \ R C × C v [ ∑ k ∈ Ω k A m q k W m ′ ⏟ \ R C v × C x k ] where A m q k ∝ exp { ( U m z q ) T ( V m x k ) C v } U m , V m ∈ \ R C p × C \begin{array}{c} \text { MultiHeadAttn }\left(\mathrm{z}_{\mathrm{q}}, \mathrm{x}\right)=\sum_{m=1}^{M} \underbrace{W_{m}}_{\backslash \mathrm{R}^{C \times C_{v}}}[\sum_{k \in \Omega_{k}} A_{m q k} \underbrace{W_{m}^{\prime}}_{\backslash \mathrm{R}^{C_{v} \times C}} x_{k}] \\ \text { where } A_{m q k} \propto \exp \left\{\frac{\left(U_{m} z_{q}\right)^{T}\left(V_{m} x_{k}\right)}{\sqrt{C_{v}}}\right\} \quad U_{m}, V_{m} \in \backslash \mathbf{R}^{C_{p} \times C} \end{array} MultiHeadAttn (zq,x)=∑m=1M\RC×Cv
Wm[∑k∈ΩkAmqk\RCv×C
Wm′xk] where Amqk∝exp{
Cv(Umzq)T(Vmxk)}Um,Vm∈\RCp×C
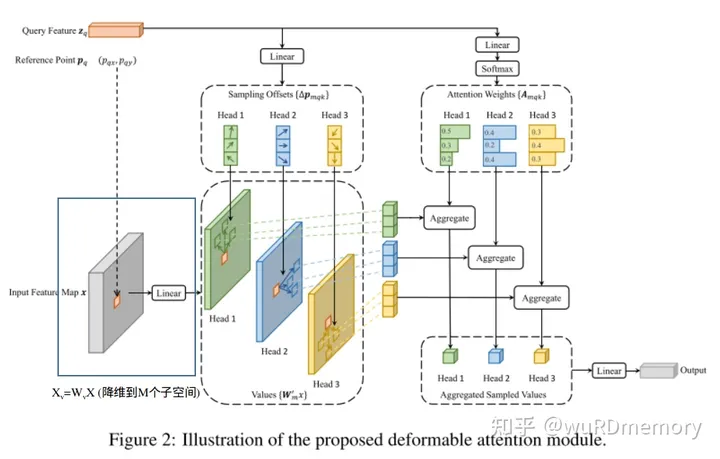
deformable-attention:
DeformAttn ( z q , p q , x ) = ∑ m = 1 M W m ⏟ \ R C × C v [ ∑ k = 1 K A m q k W m ′ ⏟ \ R C v × C x ( p q + Δ p m q k ) ] \operatorname{DeformAttn}\left(\mathrm{z}_{\mathrm{q}}, \mathrm{p}_{\mathrm{q}}, \mathrm{x}\right)=\sum_{m=1}^{M} \underbrace{W_{m}}_{\backslash \mathrm{R}^{C \times C v}}[\sum_{k=1}^{K} A_{m q k} \underbrace{W_{m}^{\prime}}_{\backslash \mathrm{R}^{C_{v} \times C}} x\left(p_{q}+\Delta p_{m q k}\right)] DeformAttn(zq,pq,x)=m=1∑M\RC×Cv
Wm[k=1∑KAmqk\RCv×C
Wm′x(pq+Δpmqk)]
M:head
K:采样点
特征图:xl,l∈[1,L],表示多个尺度的特征图
p_q:参考点,query的坐标点
这里每个像素点z_q只和其对应的k个采样点算attention
- z_q:query可以是encoder的图像或上一个decoder的输出(特征图中每个像素点都是一个维度为C的向量z_q)
- 每个像素点的Reference Point也就是二维位置坐标为 p_q(在图像上生成很多采样点p_q,文章最后写了如何在encoder和decoder处获得reference point,one-stage的参考点是get_reference_points函数生成的,而two-stage参考点是通过gen_encoder_output_proposals函数生成的,后续two-stage再讲。)。
- M代表多头注意力机制中头的数目(论文中M=8)
- 每一个头中只考虑 z_q 附近 K 个点(K远小于H x W,论文K=4)。
- Δpmqk代表采样的位置偏移量(第一个linear),是一个二维的坐标(初始化采样点是固定的,但后续将通过全连接层计算预测更加值得关注的点的坐标)
K 个采样点由参考点 p_q和偏移量 Δpmqk共同得到,当然这个偏移量不可能就是一个整数,这里获取该偏移量上的特征时是使用了双线性插值的;
之后再接通过权重norm,输出。
Deformable Attention使用的地方:
- Encoder中的Self-Attention使用Deformable Attention替换.
- Decoder中的Cross-Attention使用Deformable Attention替换,selfattention没替换,关注的还是原始的qkv
原始DETR:分类头,bbox预测头输出四个值(中心点和宽高)
deformable detr:bbox的预测头的预测结果是相对于参考点的坐标偏移量,这样的设计可以降低优化难度网络
首先会经过Linear得出参考点的初始坐标,因此最后的bbox的输出不再是表示坐标值,而是表示了坐标的偏移量,用以对参考点的坐标进行修正,这样也更加符合网络的设计

deformable detr几个变体:
变体1:bbox强化 bbox refinement(不是辅助分类)
reference point:encoder:gird H*W
decoder:经过linear后生成的300个坐标( 参考点的获取方法为object queries通过一个nn.Linear得到每个对应的reference point)
不适用bbox强化,decoder连续作用
实现方法:
过一个decoder,算一次bbox坐标(加上reference point),传入下一层,反复
即,若使用了iterative bbox refine策略,则Decoder每层都会预测bbox,这些bbox就会作为新一轮的参考点供下一层使用,相当于coarse-to-fine的过程,不断地对参考点进行校正,最终会返回最后一层的校正结果。
由此可知,即便不是2-stage模式,只要使用了iterative bbox refine策略,这里返回的参考点也会变为4d的形式。因为检测头部的回归分支预测出来的结果是4d(xywh)形式的,而且是相对于参考点的偏移量(并非绝对坐标位置)。如果初始进来的参考点是2d的,那么wh就仅由检测头部的预测结果决定。
变体2:two-stage(如何获得reference point -one stage/two stage)
6encoder -> memory(output)-> 传入两个FFN分类头(cls,bbox) -> bbox输出 和memory-> 6decoder
2-stage模式下,输入到Decoder的参考点是Encoder预测的top-k proposal boxes,也就是说是4d的(非2-stage情况下是2d)
得到参考点(reference points):需要说明下,在2-stage模式下,参考点和输入到Decoder的object query及query embedding的生成方式和形式会有所不同:
–如果是2-stage模式,那么参考点就是由Encoder预测的top-k得分最高的proposal boxes(注意,这时参考点是4d的,是bbox形式)。然后通过对参考点进行位置嵌入(position embedding)来生成Decoder的object query(target) 和对应的 query embedding;
–否则,Decoder的 object query(target )和 query embedding 就是预设的nn.embedding,然后将query embedding经过全连接层输出2d参考点,这时的参考点是归一化的中心坐标形式。
另外,两种情况下生成的参考点数量可能不同:2-stage时是有top-k(作者设置为300)个,而1-stage时是num_queries(作者也设置为300)个,也就是和object query的数量一致(可以理解为,此时参考点就是object query本身的位置)。
其他:
num_class没有no object(+1),但是有类似的处理过程
matcher的label loss计算不同:
原始:直接过softmax
这里用的是focal bce loss
参考:
https://www.bilibili.com/video/BV1B8411M73e/?spm_id_from=333.788&vd_source=4e2df178682eb78a7ad1cc398e6e154d