【20】面向流水线的指令设计(上):一心多用的现代CPU
引言
构造一个完整功能的 CPU,引入了三个“周期”的概念,分别是指令周期、机器周期(或者 CPU 周期)以及时钟周期。
我们说程序的性能,是由三个因素相乘来衡量的,我们还专门说过“指令数×CPI×时钟周期”这个公式。这里面和周期相关的只有一个时钟周期,也就是我们 CPU 的主频倒数。当时讲的时候我们说,一个 CPU 的时钟周期可以认为是可以完成一条最简单的计算机指令的时间。
那么,为什么我们在构造 CPU 的时候,一下子出来了那么多个周期呢?这一讲,我就来为你说道说道,带你更深入地看看现代 CPU 是怎么一回事儿。
一、单指令周期处理器【电脑和手机的CPU并未使用】
学过前面三讲,你现在应该知道,一条 CPU 指令的执行,是由“取得指令(Fetch)- 指令译码(Decode)- 执行指令(Execute) ”这样三个步骤组成的。这个执行过程,至少需要花费一个时钟周期。因为在取指令的时候,我们需要通过时钟周期的信号,来决定计数器的自增。
那么,很自然地,我们希望能确保让这样一整条指令的执行,在一个时钟周期内完成。这样,我们一个时钟周期可以执行一条指令,CPI 也就是 1,看起来就比执行一条指令需要多个时钟周期性能要好。采用这种设计思路的处理器,就叫作单指令周期处理器(Single Cycle Processor),也就是在一个时钟周期内,处理器正好能处理一条指令。
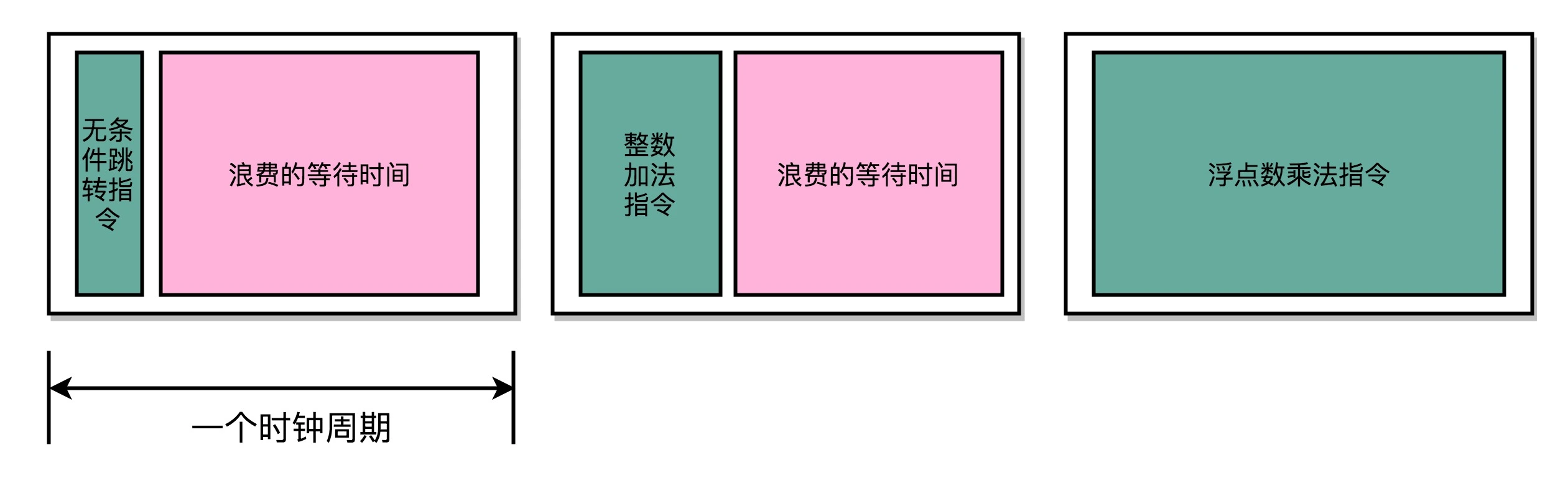
不过,我们的时钟周期是固定的,但是指令的电路复杂程度是不同的,所以实际一条指令执行的时间是不同的。例如:加法器和乘法器的复杂程度就不同。
不同指令的执行时间不同,但是我们需要让所有指令都在一个时钟周期内完成,那就只好把时钟周期和执行时间最长的那个指令设成一样。
不使用单指令周期处理器的原因:
所以,在单指令周期处理器里面,无论是执行一条用不到 ALU 的无条件跳转指令,还是一条计算起来电路特别复杂的浮点数乘法运算,我们都要等满一个时钟周期。在这个情况下,虽然 CPI 能够保持在 1,但是我们的时钟频率却没法太高。因为太高的话,有些复杂指令没有办法在一个时钟周期内运行完成。那么在下一个时钟周期到来,开始执行下一条指令的时候,前一条指令的执行结果可能还没有写入到寄存器里面。那下一条指令读取的数据就是不准确的,就会出现错误。


到这里你会发现,这和我们之前第 3 讲和第 4 讲讲时钟频率时候的说法不太一样。当时我们说,一个 CPU 时钟周期,可以认为是完成一条简单指令的时间。为什么到了这里,单指令周期处理器,反而变成了执行一条最复杂的指令的时间呢?
重点:
这是因为,无论是 PC 上使用的 Intel CPU,还是手机上使用的 ARM CPU,都不是单指令周期处理器,而是采用了一种叫作指令流水线(Instruction Pipeline)的技术。
二、现代处理器的流水线设计【和产线的流水线生产一个道理】
其实,CPU 执行一条指令的过程和我们开发软件功能的过程很像。
如果我们有一个开发团队,我们不会让后端工程师开发完 API 之后,就歇着等待前台 App 的开发、测试乃至发布,而是会在客户端 App 开发的同时,着手下一个需求的后端 API 开发。每一个后面的步骤,都要依赖前面的步骤。那么,同样的思路我们可以一样应用在 CPU 执行指令的过程中。
通过过去三讲,你应该已经知道了,CPU 的指令执行过程,其实也是由各个电路模块组成的。我们在取指令的时候,需要一个译码器把数据从内存里面取出来,写入到寄存器中;在指令译码的时候,我们需要另外一个译码器,把指令解析成对应的控制信号、内存地址和数据;到了指令执行的时候,我们需要的则是一个完成计算工作的 ALU。这些都是一个一个独立的组合逻辑电路,我们可以把它们看作一个团队里面的产品经理、后端工程师和客户端工程师,共同协作来完成任务。

这样一来,我们就不用把时钟周期设置成整条指令执行的时间,而是拆分成完成这样的一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,也不需要等待整个指令执行完成,而是可以直接执行下一条指令的对应阶段。
这就好像我们的后端程序员不需要等待功能上线,就会从产品经理手中拿到下一个需求,开始开发 API。这样的协作模式,就是我们所说的指令流水线。这里面每一个独立的步骤,我们就称之为流水线阶段或者流水线级(Pipeline Stage)。
如果我们把一个指令拆分成“取指令 - 指令译码 - 执行指令”这样三个部分,那这就是一个三级的流水线。如果我们进一步把“执行指令”拆分成“ALU 计算(指令执行)- 内存访问 - 数据写回”,那么它就会变成一个五级的流水线。
五级的流水线,就表示我们在同一个时钟周期里面,同时运行五条指令的不同阶段。这个时候,虽然执行一条指令的时钟周期变成了 5,但是我们可以把 CPU 的主频提得更高。【我们不需要确保最复杂的那条指令在时钟周期里面执行完成,而只要保障一个最复杂的流水线级的操作,在一个时钟周期内完成就好了。】
如果某一个操作步骤的时间太长,我们就可以考虑把这个步骤,拆分成更多的步骤,让所有步骤需要执行的时间尽量都差不多长。这样,也就可以解决我们在单指令周期处理器中遇到的,性能瓶颈来自于最复杂的指令的问题。像我们现代的 ARM 或者 Intel 的 CPU,流水线级数都已经到了 14 级。
虽然我们不能通过流水线,来减少单条指令执行的“延时”这个性能指标,但是,通过同时在执行多条指令的不同阶段,我们提升了 CPU 的“吞吐率”。在外部看来,我们的 CPU 好像是“一心多用”,在同一时间,同时执行 5 条不同指令的不同阶段。【在 CPU 内部,其实它就像生产线一样,不同分工的组件不断处理上游传递下来的内容,而不需要等待单件商品生产完成之后,再启动下一件商品的生产过程。】
三、超长流水线的性能瓶颈【产生更多的overhead开销】
既然流水线可以增加我们的吞吐率,你可能要问了,为什么我们不把流水线级数做得更深呢?为什么不做成 20 级,乃至 40 级呢?这个其实有很多原因,我在之后几讲里面会详细讲解。这里,我先讲一个最基本的原因,就是增加流水线深度,其实是有性能成本的。
我们用来同步时钟周期的,不再是指令级别的,而是流水线阶段级别的。每一级流水线对应的输出,都要放到流水线寄存器(Pipeline Register)里面,然后在下一个时钟周期,交给下一个流水线级去处理。所以,每增加一级的流水线,就要多一级写入到流水线寄存器的操作。虽然流水线寄存器非常快,比如只有 20 皮秒(ps,10−12 秒)。
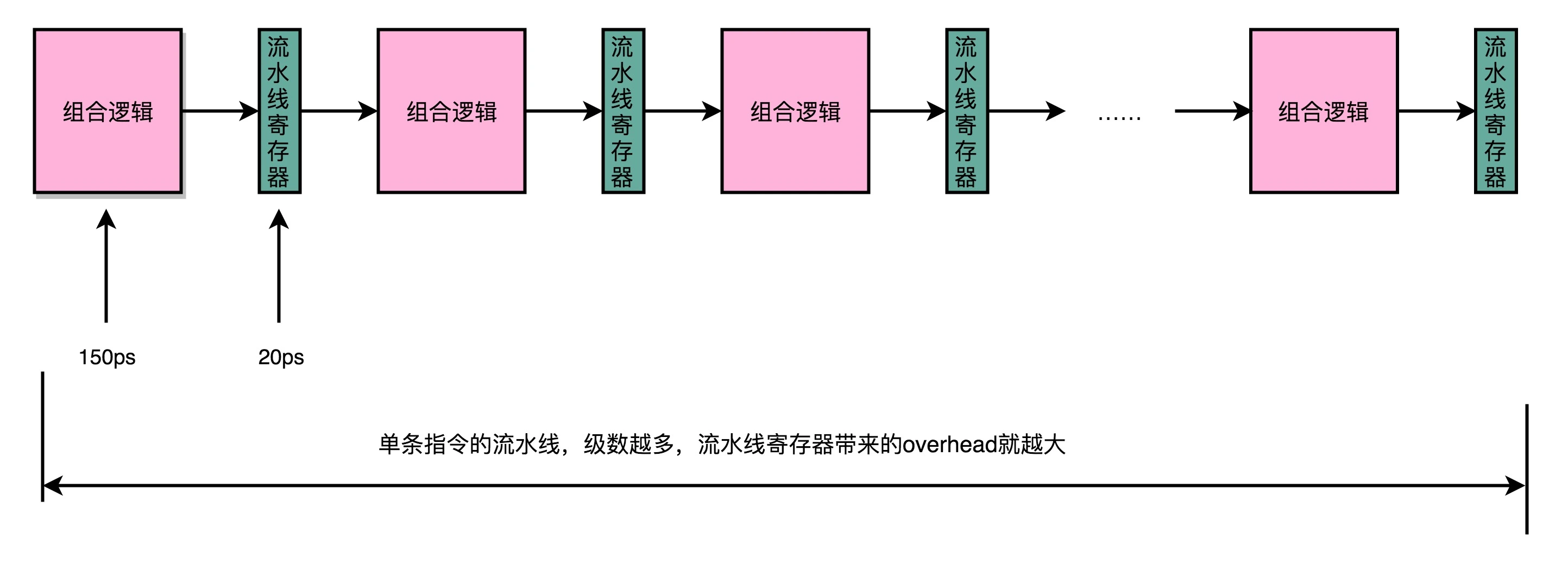
但是,如果我们不断加深流水线,这些操作占整个指令的执行时间的比例就会不断增加。最后,我们的性能瓶颈就会出现在这些 overhead 上。如果我们指令的执行有 3 纳秒,也就是 3000 皮秒。我们需要 20 级的流水线,那流水线寄存器的写入就需要花费 400 皮秒,占了超过 10%。如果我们需要 50 级流水线,就要多花费 1 纳秒在流水线寄存器上,占到 25%。这也就意味着,单纯地增加流水线级数,不仅不能提升性能,反而会有更多的 overhead 的开销。所以,设计合理的流水线级数也是现代 CPU 中非常重要的一点。
四、总结【个人总结的重点】
-
单指令周期处理器:程序的 CPU 执行时间 =指令数×CPI×时钟周期时间 中的CPI为1【每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)】,即 在一个时钟周期内,处理器正好能处理一条指令。
-
现代的手机和电脑CPU都不使用 单指令周期处理器。
-
现代处理器的流水线设计:指令流水线(Instruction Pipeline),可提升 CPU 的吞吐率;类似产线的流水线;现代的 ARM 或者 Intel 的 CPU,流水线级数都已经到了14 级。
-
超长流水线的性能瓶颈:每增加一级的流水线,就要多一级写入到流水线寄存器的操作。单纯地增加流水线级数,不仅不能提升性能,反而会有更多的 overhead 的开销。
-
一个 CPU 的时钟周期,可以认为是完成一条简单指令的时间 的理解?:随着流水线设计的引入,一个指令被拆分为14个子流程。一个CPU的时钟时间,应该是14个子流程中最长的那条的耗时时间。