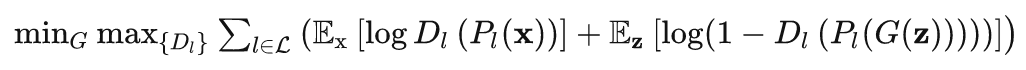We obtain features from four layers Ll of a pretrained Feature Network F at resolutions (L1 = , L2 = , L3 = , L4 = ). We associate a separate discriminator Dl with the features at layer Ll , respectively. Each discriminator Dl uses a simple convolutional architecture with spectral normalization at each convolutional layer. We observe better performance if all discriminators output logits at the same resolution ( ). Accordingly, we use fewer down-sampling blocks for lower resolution inputs. Following common practice, we sum all logits for computing the overall loss. For the generator pass, we sum the losses of all discriminators. More complex strategies [1, 13] did not improve performance in our experiments.
1、在预训练的Feature Network F 上获得四层特征L1、L2、L3、L4;
2、将每一层的Li与Di连接起来;
(2)随机投影(Random Projections)
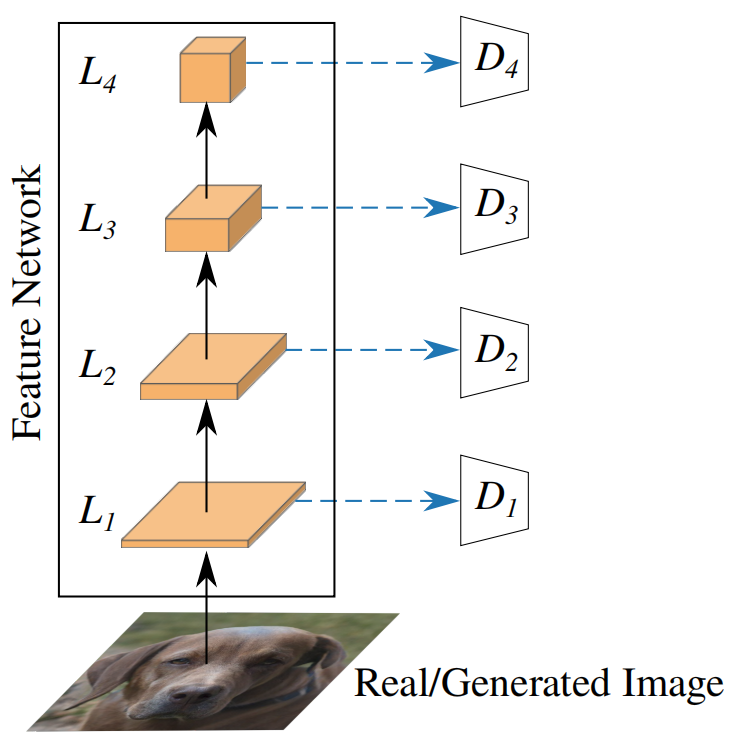
We observe that features at deeper layers are significantly harder to cover. We hypothesize that a discriminator can focus on a subset of the feature space while wholly disregarding other parts. This problem might be especially prominent in the deeper, more semantic layers. Therefore, we propose two different strategies to dilute prominent features, encouraging the discriminator to utilize all available information equally. Common to both strategies is that they mix features using differentiable random projections which are fixed, i.e., after random initialization, the parameters of these layers are not trained.
Empirically, we found two properties to be desirable: (i) the random projection should be information preserving to leverage the full representational power of F,随机投影应该是信息保留的,以充分利用F的表示能力 (ii) it should not be trivially invertible.它不应该是简单的可逆的。
The easiest way to mix across channels is a 1×1 convolution. A 1×1 convolution with an equal number of output and input channels is a generalization of a permutation [28] and consequently preserves information about its input. In practice, we find that more output channels lead to better performance as the mapping remains injective and therefore information preserving. Kingma et al. [28] initialize their convolutional layers as a random rotation matrix as a good starting point for optimization. We do not fifind this to improve GAN performance (see Appendix), arguably since it violates (ii). We therefore randomly initialize the weights of the convolutional layer via Kaiming initialization [16]. Note that we do not add any activation functions. We apply this random projection at each of the four scales and feed the transformed feature to the discriminator as depicted in Fig. 2.
Figure 2: CCM(蓝色虚线箭头)使用带有随机权值的1×1卷积。
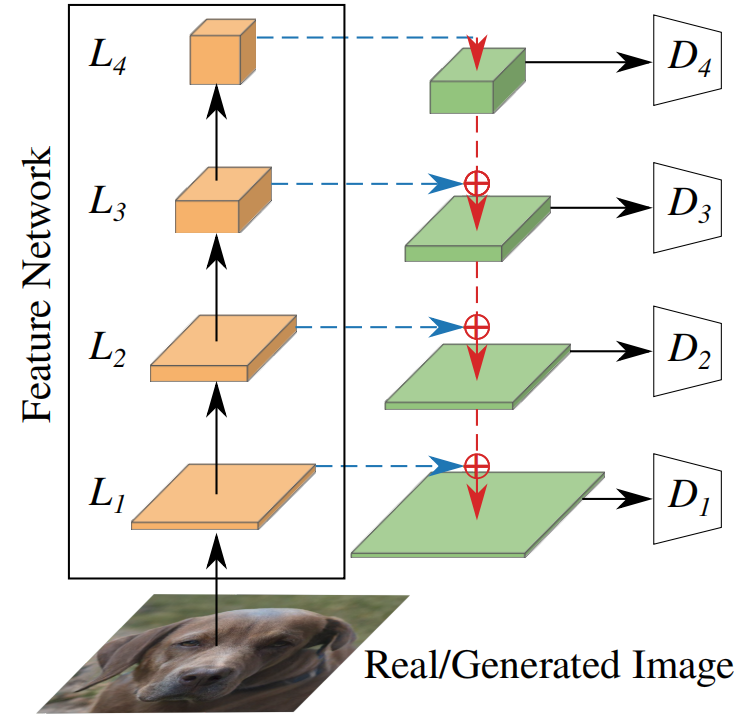
2、Cross-Scale Mixing(CSM):跨尺度的特征混合
To encourage feature mixing across scales, CSM extends CCM with random 3×3 convolutions and bilinear upsampling, yielding a U-Net [50] architecture, see Fig. 3. However, our CSM block is simpler than a vanilla U-Net [50]: we only use a single convolutional layer at each scale. As for CCM, we utilize Kaiming initialization for all weights.
Figure 3: CSM(红色虚线箭头)添加了随机3×3卷积和双线性上采样,产生了一个u网络。
3、Pretrained Feature Networks:预训练特征网络
We ablate over varying feature networks. First, we investigate different versions of EffificientNets, which allow for direct control over model size versus performance. EfficientNets are image classification models trained on ImageNet [7] and designed to provide favorable accuracy-compute tradeoffs. Second, we use ResNets of varying sizes. To analyze the dependency on ImageNet features (Section 4.3), we also consider R50-CLIP [46], a ResNet optimized with a contrastive language-image objective on a dataset of 400 million (image, text) pairs. Lastly, we utilize a vision transformer architecture (ViTBase) [9] and its efficient follow-up (DeiT-small distilled) [62]. We do not choose an inception network [60] to avoid strong correlations with the evaluation metric FID [17]. In the appendix, we also evaluate several other neural and non-neural metrics to rule out correlations. These additional metrics reflect the rankings obtained by FID.
实验中尝试了EfficientNet、Resnet、R50-CLIP和VIT-Base.
三、Experiments and Ablation Study
(用来探索上述所提的strategies最好的config,所以放在实验部分之前也不奇怪)
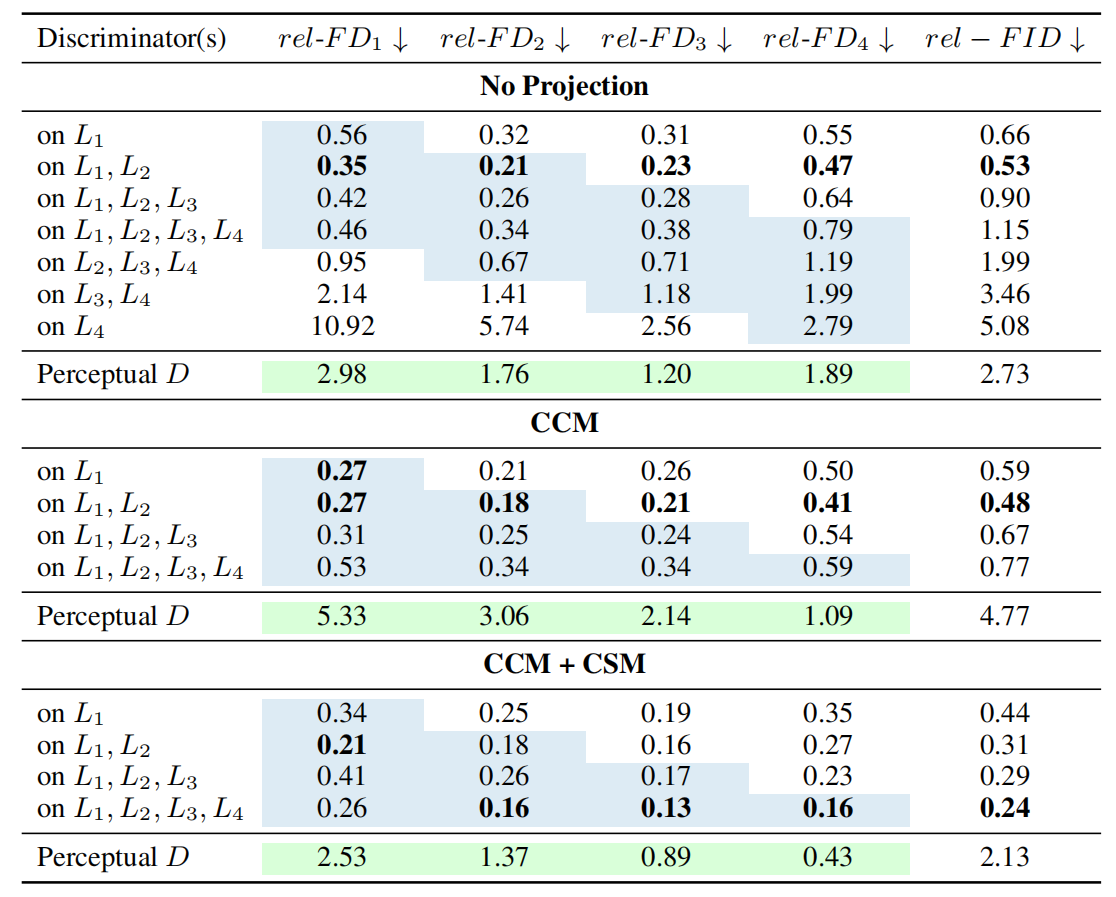
1、Feature Space Fréchet Distances(特征空间距离)
Q1:Feature Network的哪一层是最具有信息量的?
表中结论:浅层的特征更应该被利用,且随着层数的叠加,网络的性能反倒会下降。
Q2:Pretrained features应该怎么样被利用?
表中结论:CCM+CSM+四个判别器
2、哪一个特征提取网络是最有效的?
Table 2: Pretrained Feature Networks Study. We train the projected GAN with different pretrained feature networks. We find that compact EfficientNets outperform both ResNets and Transformers.
结论:生成效果跟准确率是没有关系的,Efficient-Lite1是我们后续实验选用的P。
3、Comparison to SOTA
1、相同训练时间下,表现更好(更高的FID)
Figure 1: Convergence with Projected GANs. Evolution of samples for a fixed latent code during training on the AFHQ-Dog dataset [5]. We find that discriminating features in the projected feature space speeds up convergence and yields lower FIDs. This finding is consistent across many datasets.
2、 Convergence Speed and Data efficiency:
Training Properties.
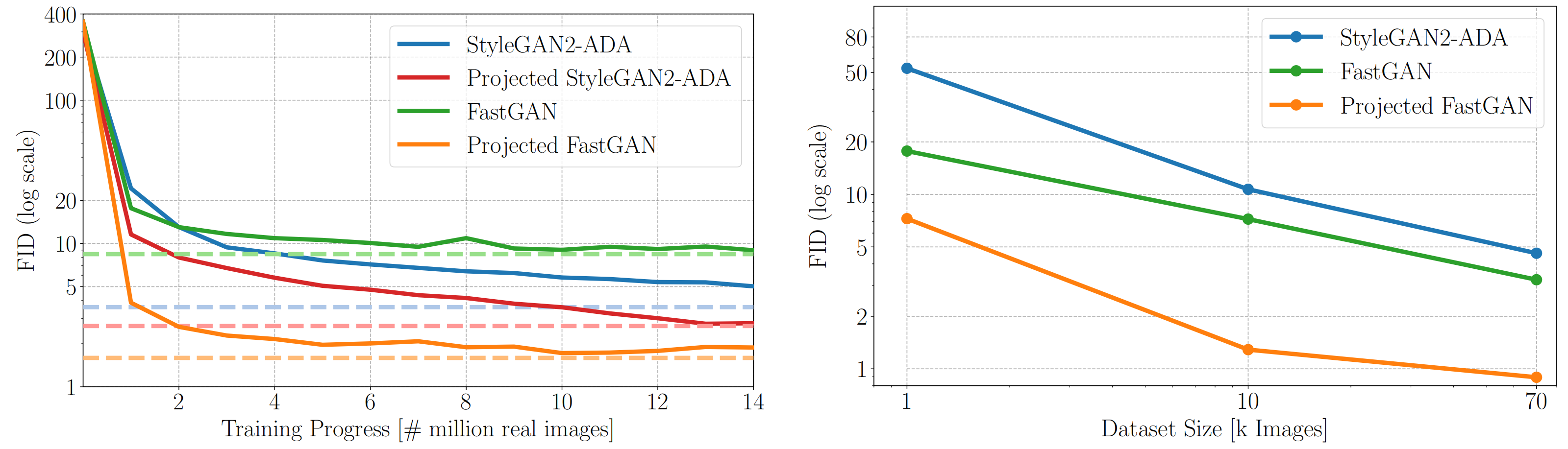
Figure 4: Left: Projected FastGAN surpasses the best FID of StyleGAN2 (at 88 M images) after just 1.1 M images on LSUN-Church. Right: Projected FastGAN yields significantly improved FID scores, even when using subsets of CLEVR with 1k and 10k samples.
supplement:k是千、万是10k、M是兆(即百万)。
个人理解:将预训练的表示能力用来提升判别器,从而给生成器提供更好的反馈是一个很好的思路,但是正如文章也讨论了,如果是很强的预训练网络,就会让判别器过强,自然能够很简单的对生成数据和真实数据进行判别,尤其是笔者的研究方向:GANs under limited data而言,判别器显然会在预训练的加持下,过拟合的更严重。所以有没有可能在利用预训练提升D的判别特征学习能力的同时,也让G更懂得如何生成D难以判别的图片,这一点值得思考。