1. 最小生成树的介绍
最小生成树(Minimum Cost Spanning Tree),简称MST。给定一个带权的无向连通图, 选取一棵生成树, 生成树所有顶点都能连通但不能形成回路。使树上所有边的权的总和为最小, 就是最小生成树。如下所示:
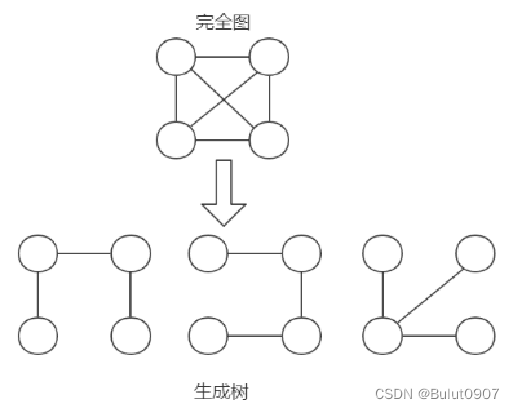
所以N个顶点,一定有N-1条边
实现最小生成树的算法主要有普里姆算法和克鲁斯卡尔算法
2. 普里姆算法的介绍
普利姆(Prim)算法求最小生成树,就是在包含N个顶点的完全图中,找出只有(N-1)条边且包含所有N个顶点的最小总权重值的连通子图
思路如下:
- 对于第一顶点,直接标记为已访问
- 找出所有边,其中一个顶点已访问,另一个顶点未访问。取权重值最小的一条边,并将该条边的未访问的顶点标记为已访问
- 不断的重复步骤2,直到所有顶点都被访问
3. 修路问题的介绍
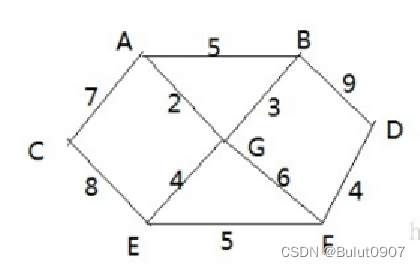
问题:有7个村庄A、B、C、D、E、F、G,各个村庄之间的距离(权)用边线表示,比如A -> B距离5公里。如何让各个村庄都能连通,并且总的修路里程最短
基本思路:尽可能少的选择路线,并且选择的路线距离最短,才能保证总的修路里程数最短
程序如下:
import java.util.Arrays;
public class PrimAlgorithm {
public static void main(String[] args) {
// 顶点集合
char[] vertexs = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
// 顶点个数
int vertexNum = vertexs.length;
// N个顶点形成的N * N二维数组,用来保存顶点之间的距离
// 用10000表示距离无限大,不能连通
int[][] weights = new int[][]{
{10000, 5, 7, 10000, 10000, 10000, 2},
{5, 10000, 10000, 9, 10000, 10000, 3},
{7, 10000, 10000, 10000, 8, 10000, 10000},
{10000, 9, 10000, 10000, 10000, 4, 10000},
{10000, 10000, 8, 10000, 10000, 5, 4},
{10000, 10000, 10000, 4, 5, 10000, 6},
{2, 3, 10000, 10000, 4, 6, 10000}
};
// 创建Graph对象
Graph graph = new Graph(vertexNum);
graph.addData2Graph(vertexs, weights);
// 输出weights
graph.showWeights();
// 创建MinTree对象
MinTree minTree = new MinTree();
// 测试普利姆算法
minTree.prim(graph, 1);
}
}
// 图
class Graph {
// 顶点个数
int vertexNum;
// 顶点集合
char[] vertexs;
// N个顶点形成的N * N二维数组,用来保存顶点之间的距离
int[][] weights;
// 进行初始化,但并未向数组保存值
public Graph(int vertexNum) {
this.vertexNum = vertexNum;
this.vertexs = new char[vertexNum];
this.weights = new int[vertexNum][vertexNum];
}
// 向图的数组保存值
public void addData2Graph(char[] vertexs, int[][] weights) {
for (int i = 0; i < this.vertexNum; i++) {
this.vertexs[i] = vertexs[i];
for (int j = 0; j < this.vertexNum; j++) {
this.weights[i][j] = weights[i][j];
}
}
}
// 显示图的二维数组,即显示顶点之间的距离
public void showWeights() {
for (int[] line : this.weights) {
System.out.println(Arrays.toString(line));
}
}
}
// 创建最小生成树
class MinTree {
// prim算法实现,生成最小生成树
// vertexIndex表示顶点在vertexs的index
public void prim(Graph graph, int vertexIndex) {
// 用来标记顶点是否被访问过。初始化都是未访问的0
int[] visited = new int[graph.vertexNum];
for (int i = 0; i < visited.length; i++) {
visited[i] = 0;
}
// 当前这个结点标记为已访问
visited[vertexIndex] = 1;
// 临时的已访问的顶点index,和临时的未访问的顶点index
int tmpVisitedVertexIndex = -1;
int tmpNotVisitedVertexIndex = -1;
// 初始化minWeight为一个大数,在遍历过程中,会被赋予较小的权重值
int minWeight = 10000;
// 每一次遍历,都能找到一个满足条件的顶点,和一条满足条件的边
for (int k = 1; k < graph.vertexNum; k++) {
// 进行双层for循环处理
for (int i = 0; i < graph.vertexNum; i++) {
for (int j = 0; j < graph.vertexNum; j++) {
// 第一层for循环表示已访问的顶点, 第二层for循环表示未访问的顶点
// 如果当前边的权重值,比minWeight还小,则找到了一条更优的边
if (visited[i] == 1 && visited[j] == 0 && graph.weights[i][j] < minWeight) {
minWeight = graph.weights[i][j];
// 更优的边的两个顶点的index
tmpVisitedVertexIndex = i;
tmpNotVisitedVertexIndex = j;
}
}
}
// 遍历完成,就会找到一条权重值最小的边
System.out.println("找到的边<" + graph.vertexs[tmpVisitedVertexIndex] + " -> " + graph.vertexs[tmpNotVisitedVertexIndex] + ">, 权重值为: " + minWeight);
// 将找到的未访问的顶点,标记为已访问
visited[tmpNotVisitedVertexIndex] = 1;
// 再次将minWeight重置
minWeight = 10000;
}
}
}
运行程序,结果如下:
[10000, 5, 7, 10000, 10000, 10000, 2]
[5, 10000, 10000, 9, 10000, 10000, 3]
[7, 10000, 10000, 10000, 8, 10000, 10000]
[10000, 9, 10000, 10000, 10000, 4, 10000]
[10000, 10000, 8, 10000, 10000, 5, 4]
[10000, 10000, 10000, 4, 5, 10000, 6]
[2, 3, 10000, 10000, 4, 6, 10000]
找到的边<B -> G>, 权重值为: 3
找到的边<G -> A>, 权重值为: 2
找到的边<G -> E>, 权重值为: 4
找到的边<E -> F>, 权重值为: 5
找到的边<F -> D>, 权重值为: 4
找到的边<A -> C>, 权重值为: 7