文章目录

Flink高手之路3-Flink的入门案例
一、Flink的API
二、Flink的编程模型
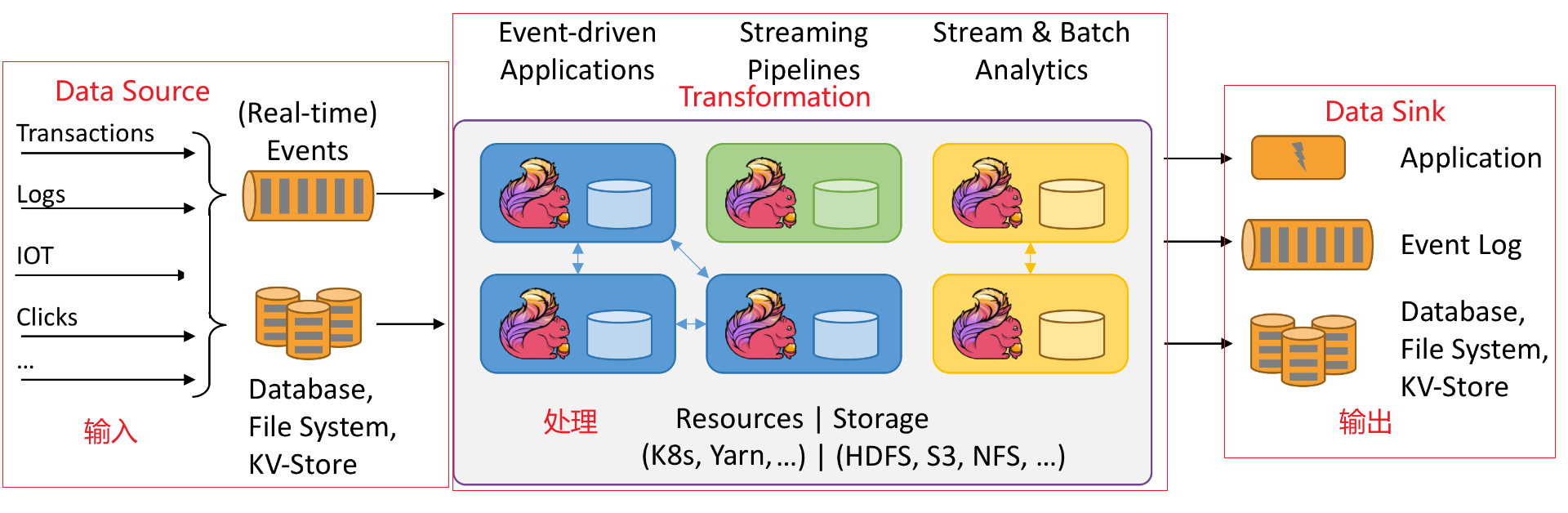
Flink的应用程序的结构跟MapReduce程序一样,主要包括三部分:
- Data Source:数据的来源
- Transformations:数据的处理
- Data Sink:数据的目的地
三、Flink的编程步骤
查看官网案例:https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/dev/dataset/overview/
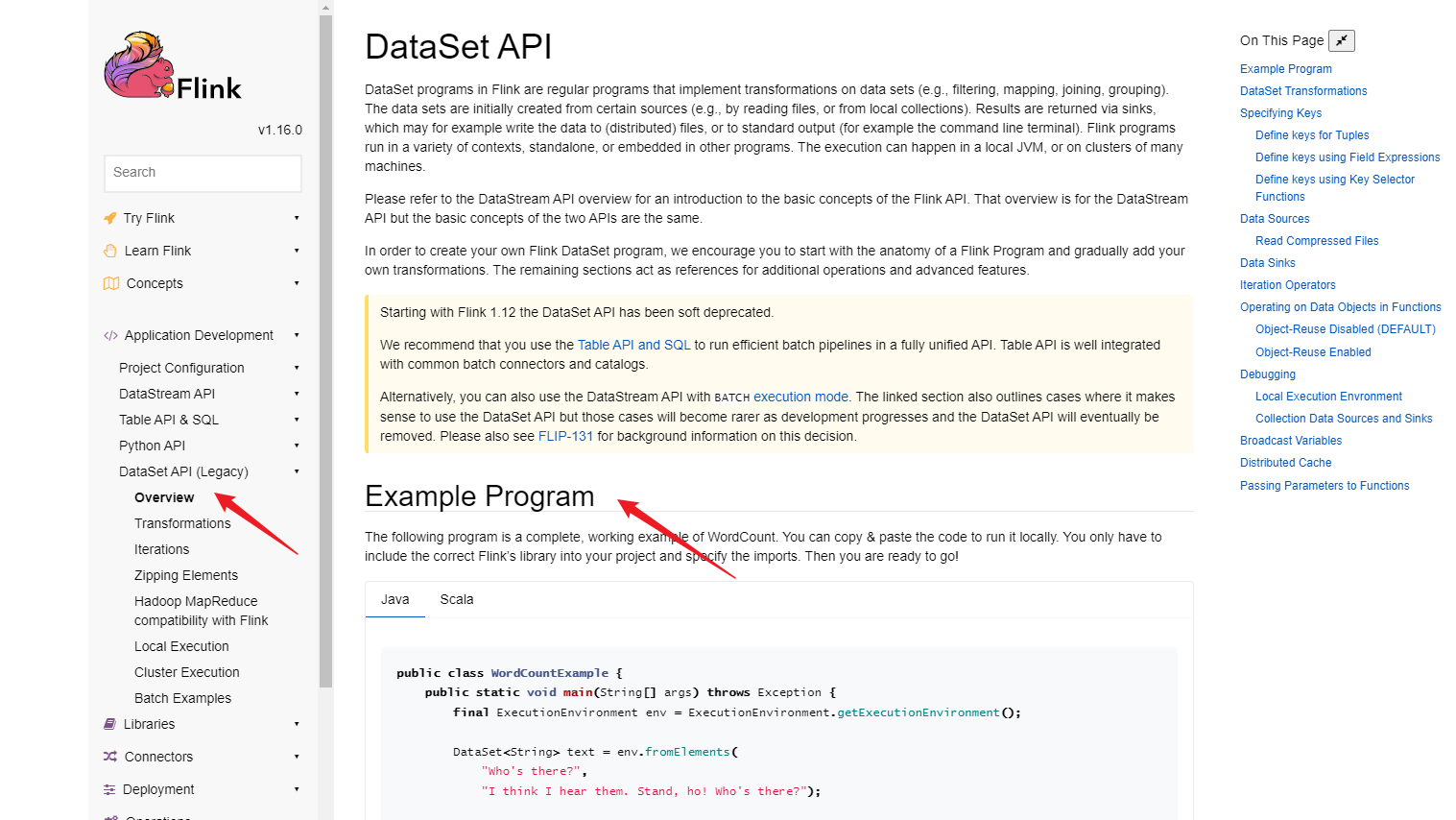
通过官网案例,主要步骤:
- 准备环境:env
- 准备数据:source
- 处理数据:transformations
- 输出结果:sink
- 触发执行
四、Flink的入门案例之一:批处理DataSet的处理
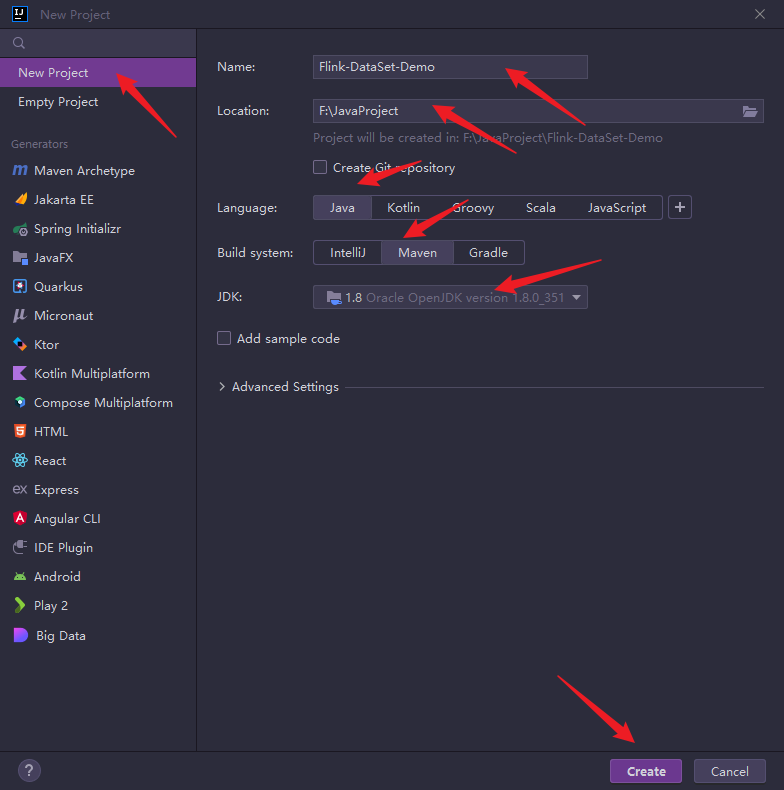
1.创建一个maven项目
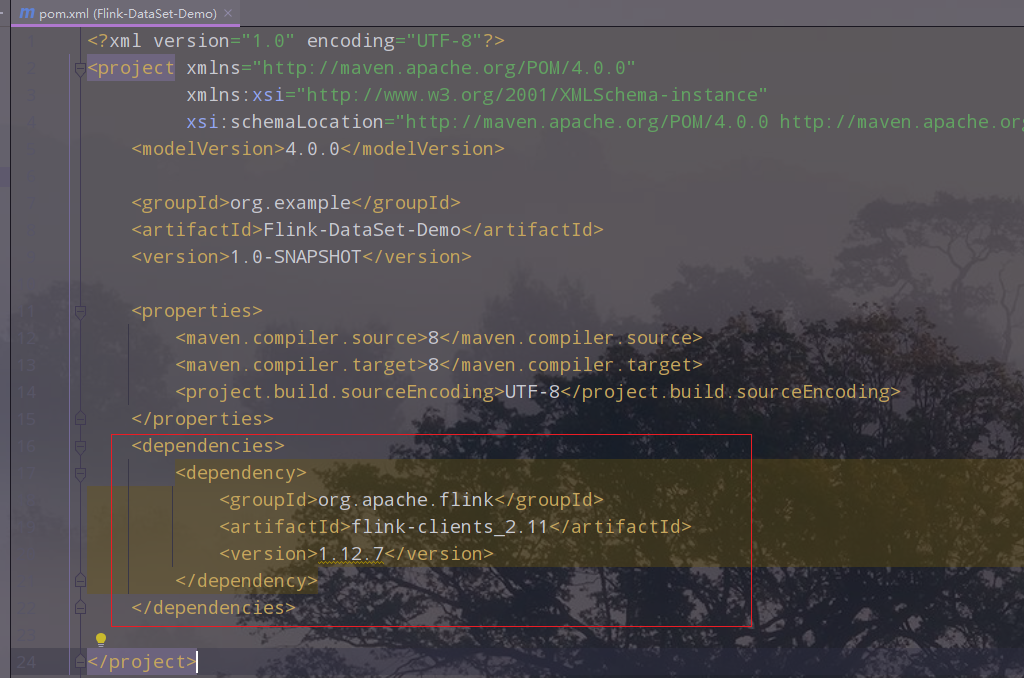
2. 改pom文件,引入Flink的依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.12.7</version>
</dependency>
</dependencies>
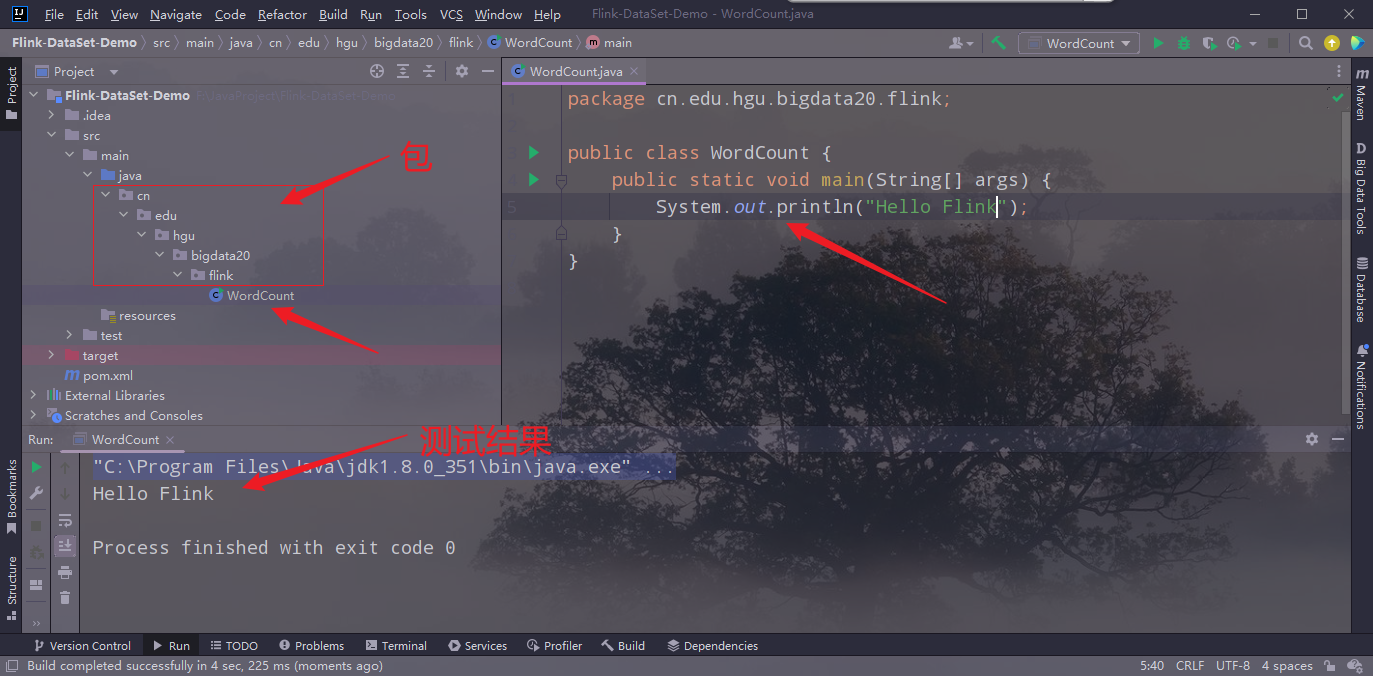
3.创建相关的包和类,并测试环境是否搭建成功
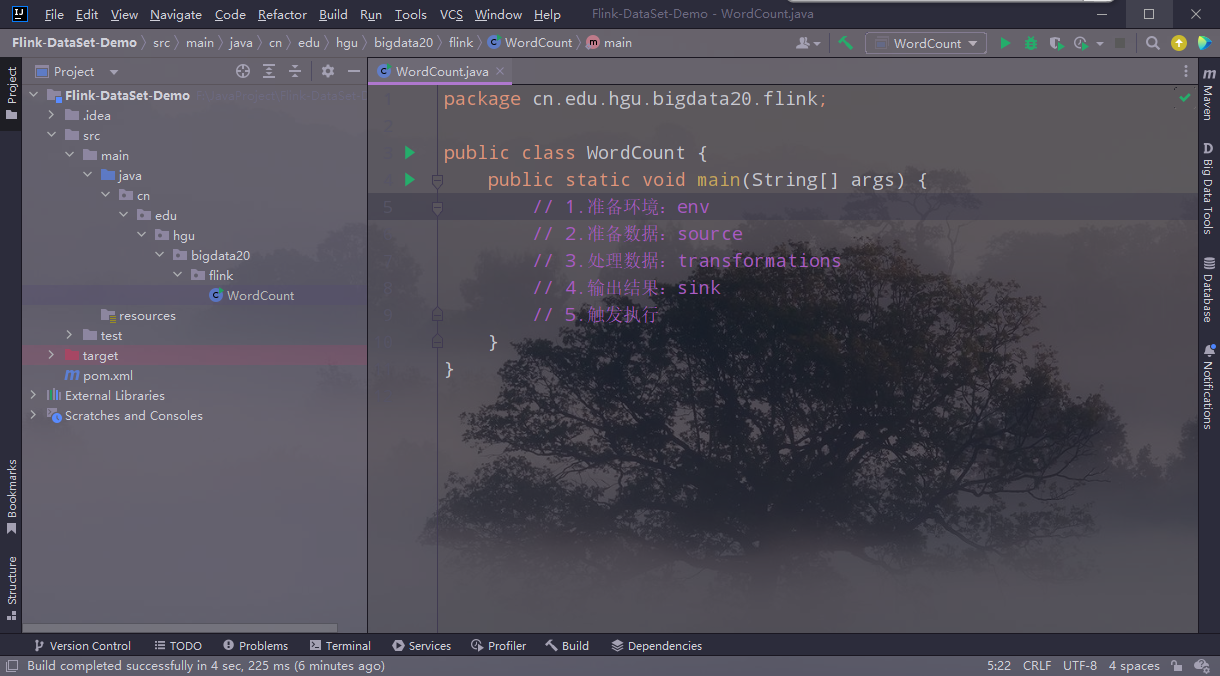
4.编写代码
(1)主要步骤
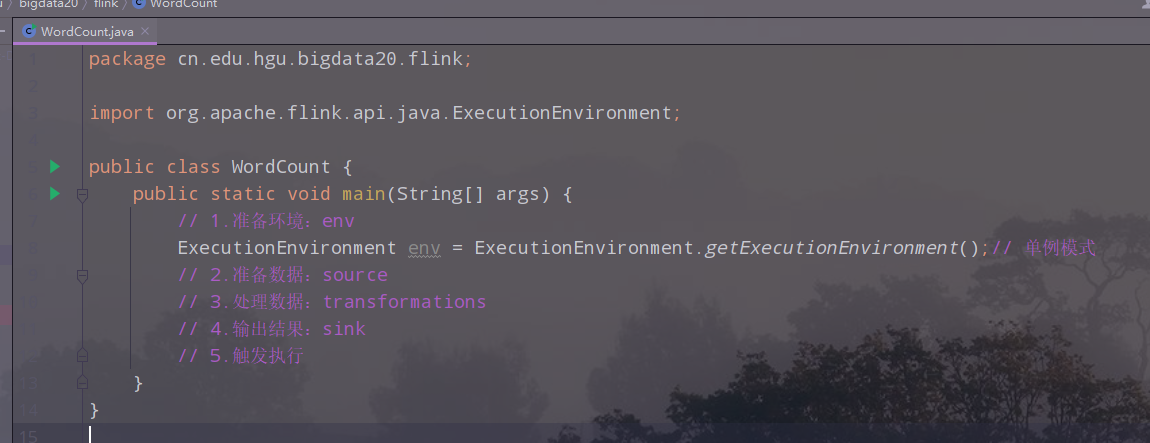
(2)准备环境
单例模式创建环境
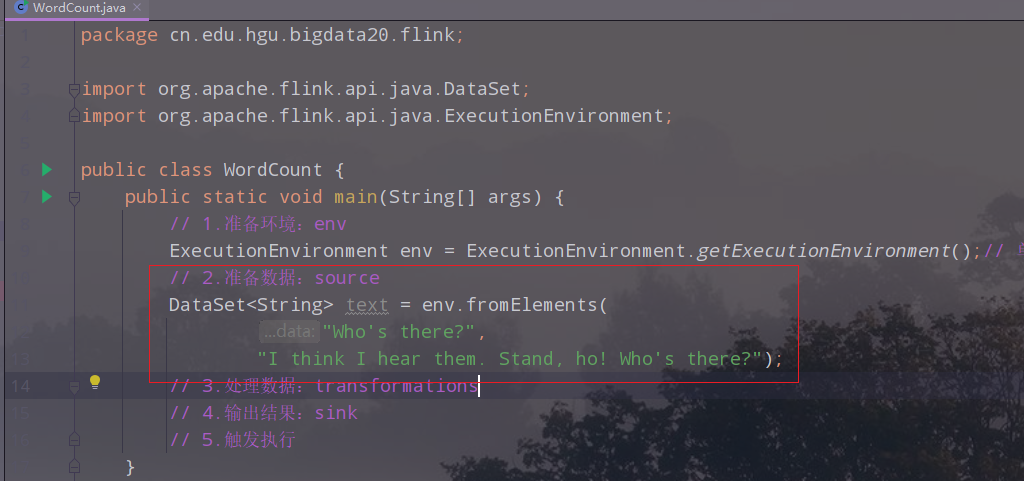
(3)准备数据
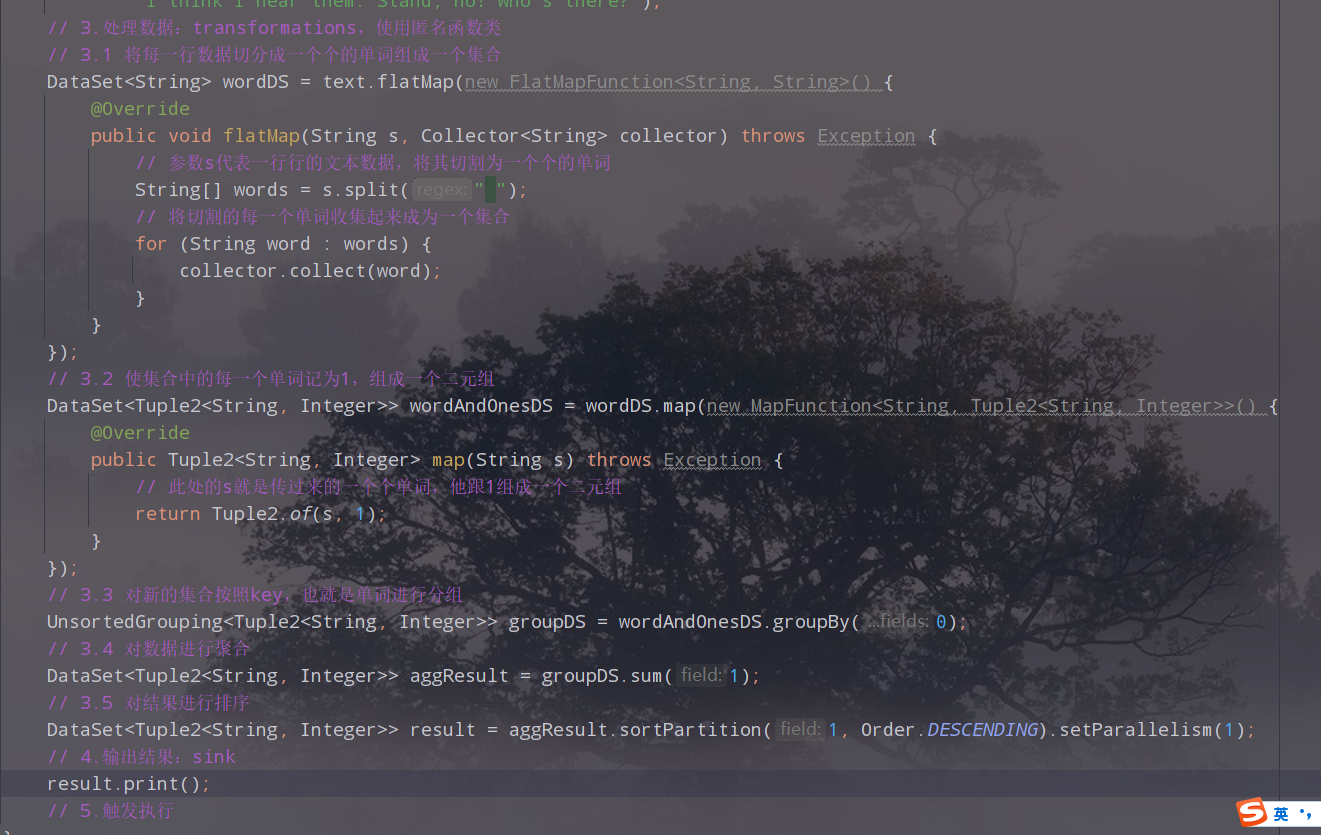
(4)处理数据
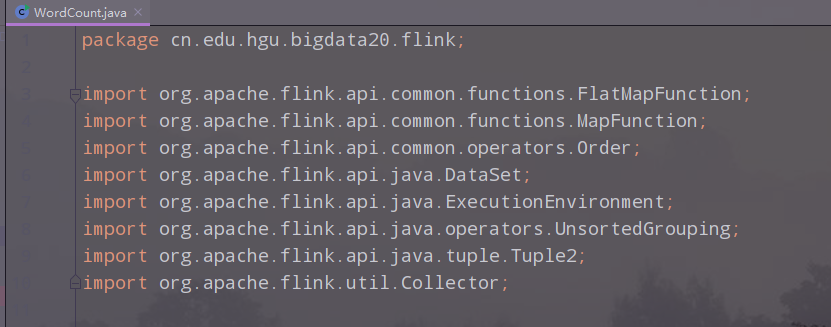
导入的类文件
(5)执行
对于DataSet的数据结果如果使用print,就不需要execute执行
(6)完整代码
package cn.edu.hgu.bigdata20.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* description:使用Flink的批处理进行单词计数
* author:wangchuanqi
* date:2023/03/24
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 1.准备环境:env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 单例模式
// 2.准备数据:source
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
// 3.处理数据:transformations,使用匿名函数类
// 3.1 将每一行数据切分成一个个的单词组成一个集合
DataSet<String> wordDS = text.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
// 参数s代表一行行的文本数据,将其切割为一个个的单词
String[] words = s.split(" ");
// 将切割的每一个单词收集起来成为一个集合
for (String word : words) {
collector.collect(word);
}
}
});
// 3.2 使集合中的每一个单词记为1,组成一个二元组
DataSet<Tuple2<String, Integer>> wordAndOnesDS = wordDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
// 此处的s就是传过来的一个个单词,他跟1组成一个二元组
return Tuple2.of(s, 1);
}
});
// 3.3 对新的集合按照key,也就是单词进行分组
UnsortedGrouping<Tuple2<String, Integer>> groupDS = wordAndOnesDS.groupBy(0);
// 3.4 对数据进行聚合
DataSet<Tuple2<String, Integer>> aggResult = groupDS.sum(1);//此处的1表示二元组的第二个元素
// 3.5 对结果进行排序
DataSet<Tuple2<String, Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
// 4.输出结果:sink
result.print();
// 5.触发执行
// 对于DataSet如果有print,可以省略execute
}
}
5.运行项目,查看结果
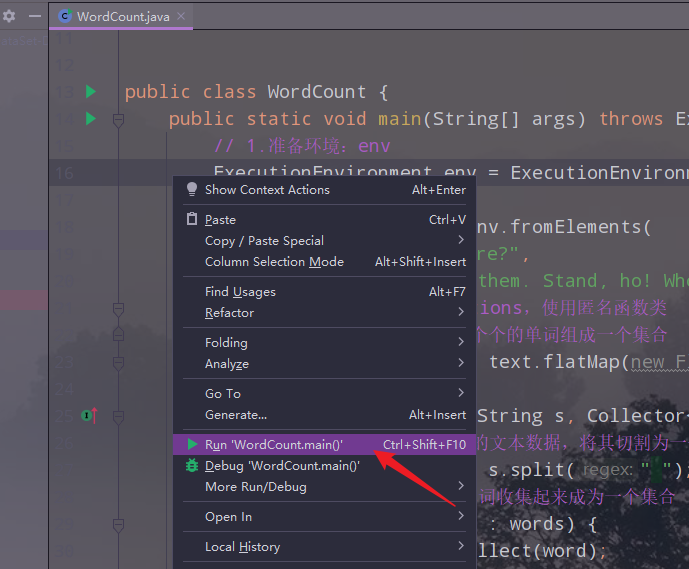
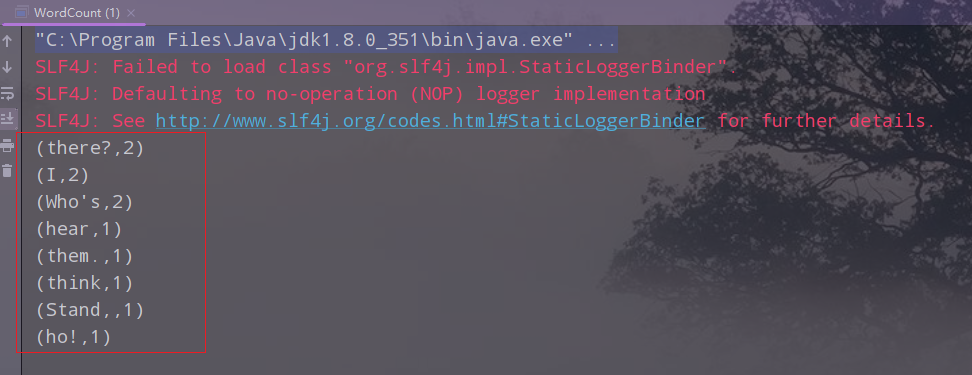
五、Flink的入门案例之二:流处理DataStream
1.创建一个类,并编写代码
package cn.edu.hgu.bigdata20.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* description:使用Flink的流处理进行单词计数
* author:wangchuanqi
* date:2023/03/24
*/
public class WordCountDataStream {
public static void main(String[] args) throws Exception {
// 1.准备环境:env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.准备数据:source
DataStream<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
// 3.处理数据:transformations,使用匿名函数类
// 3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordDS = text.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
// 参数s代表一行行的文本数据,将其切割为一个个的单词
String[] words = s.split(" ");
// 将切割的每一个单词收集起来成为一个集合
for (String word : words) {
collector.collect(word);
}
}
});
// 3.2 使集合中的每一个单词记为1,组成一个二元组
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
// 此处的s就是传过来的一个个单词,他跟1组成一个二元组
return Tuple2.of(s, 1);
}
});
// 3.3 对新的集合按照key,也就是单词进行分组
KeyedStream<Tuple2<String, Integer>, String> groupDS = wordAndOnesDS.keyBy(t -> t.f0);//lambda形式,fo表示二元组的第一个元素
// 3.4 对数据进行聚合
DataStream<Tuple2<String, Integer>> aggResult = groupDS.sum(1);//此处的1表示二元组的第二个元素
// 3.5 对结果进行排序
//DataSet<Tuple2<String, Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
// 4.输出结果:sink
aggResult.print();
// 5.触发执行
// 对于DataSet如果有print,可以省略execute
env.execute();
}
}
2.执行,查看结果
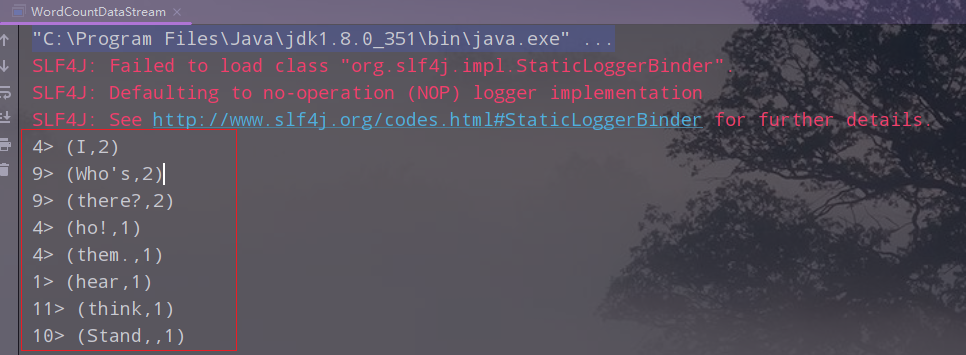
六、在hadoop集群上运行
1.启动zookeeper集群
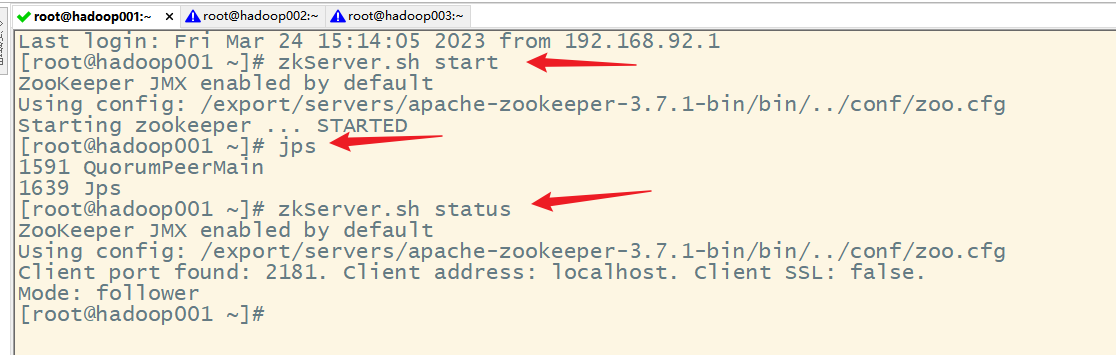
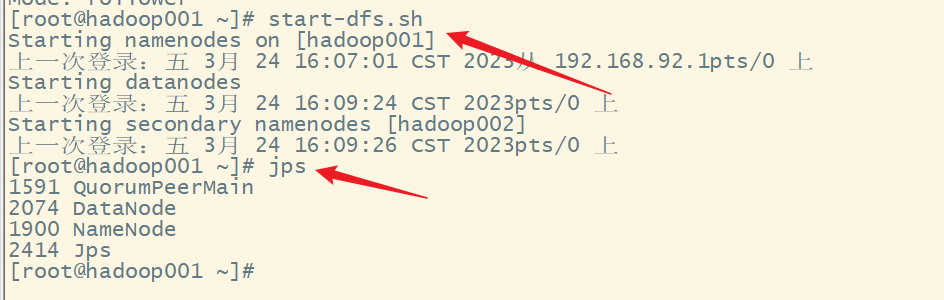
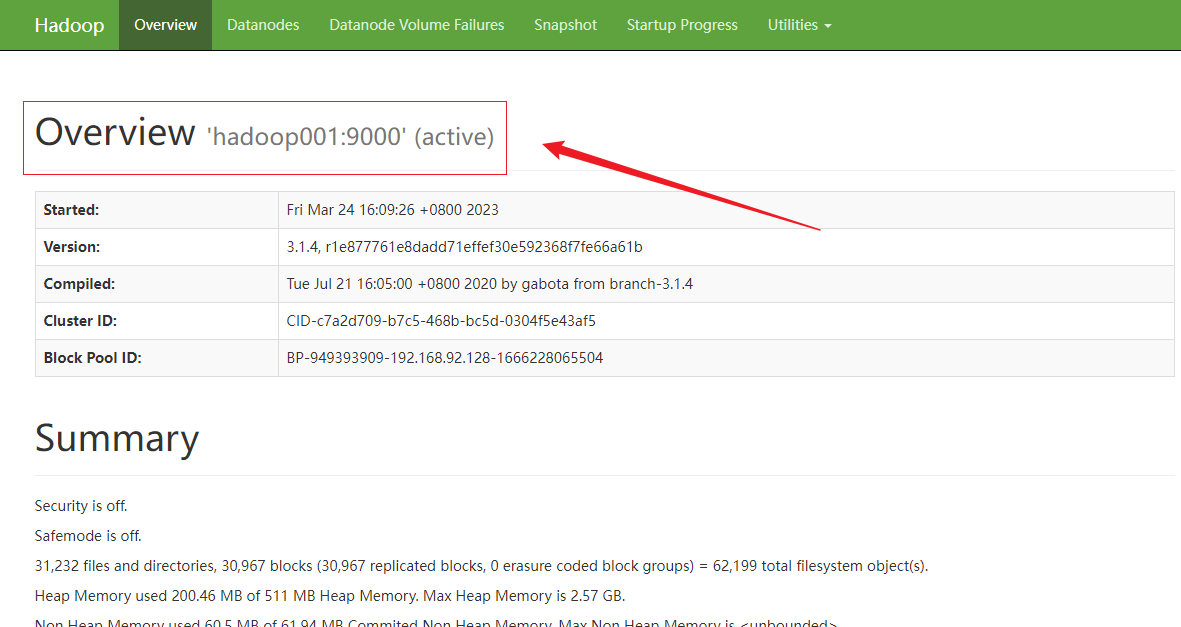
2.启动hdfs集群
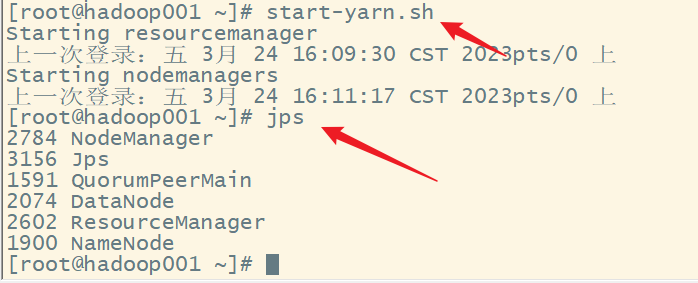
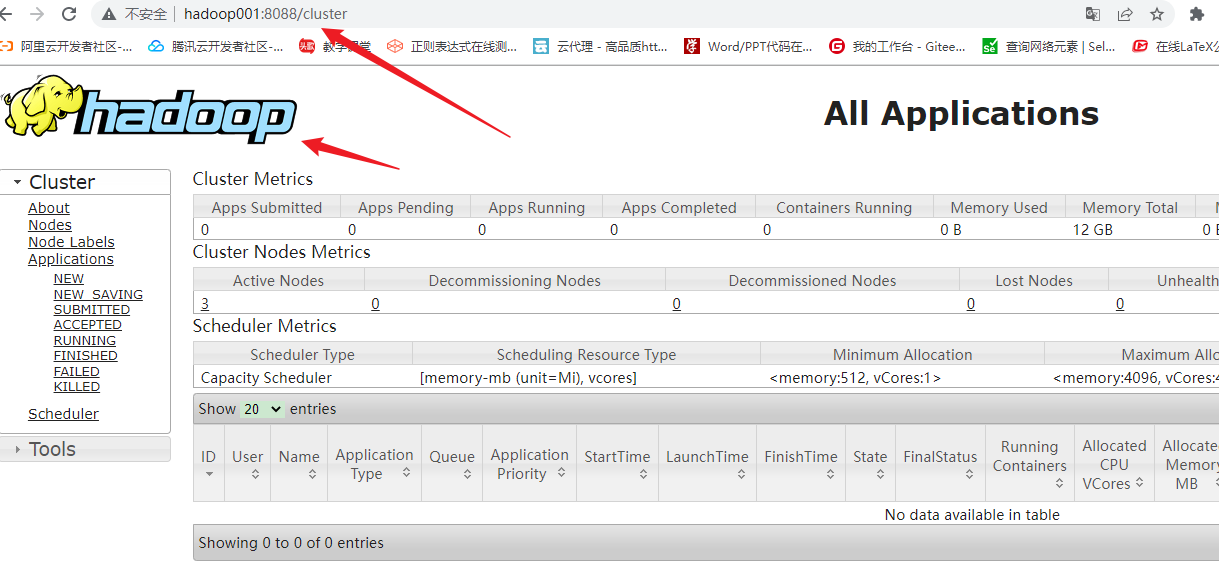
3.启动yarn集群
4.启动Flink集群
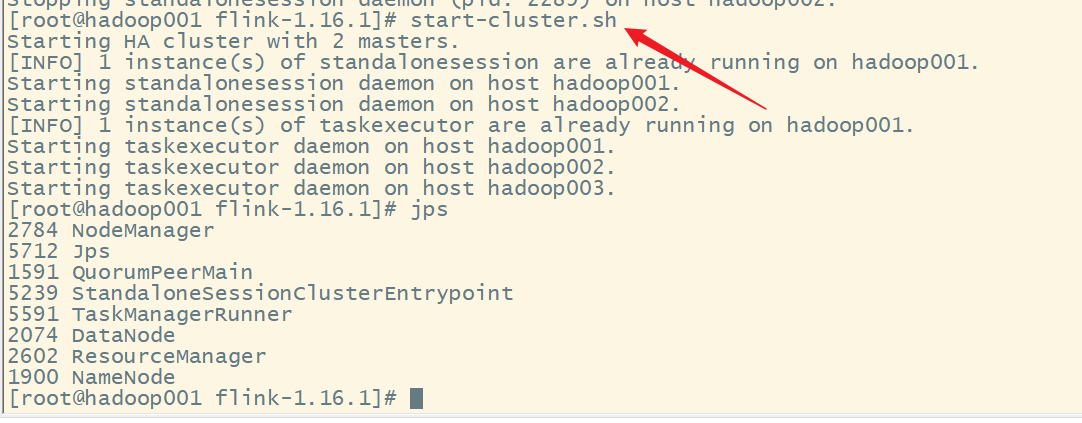
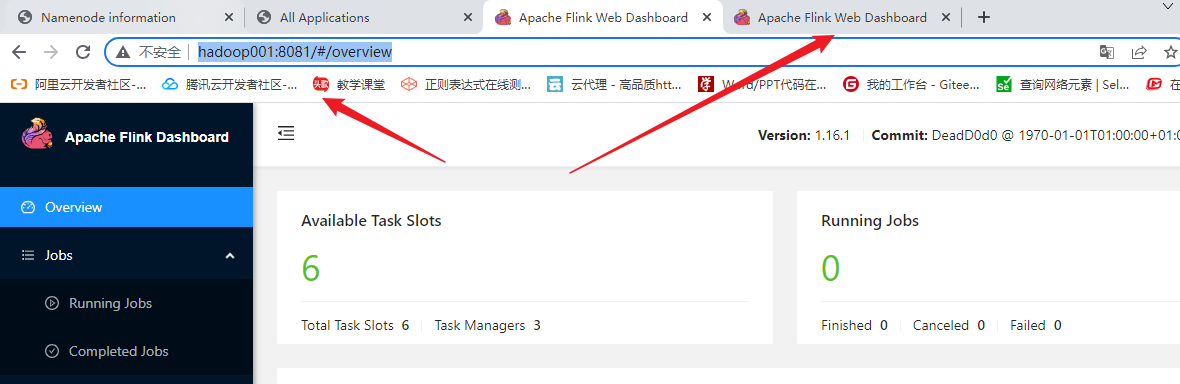
5.打jar包
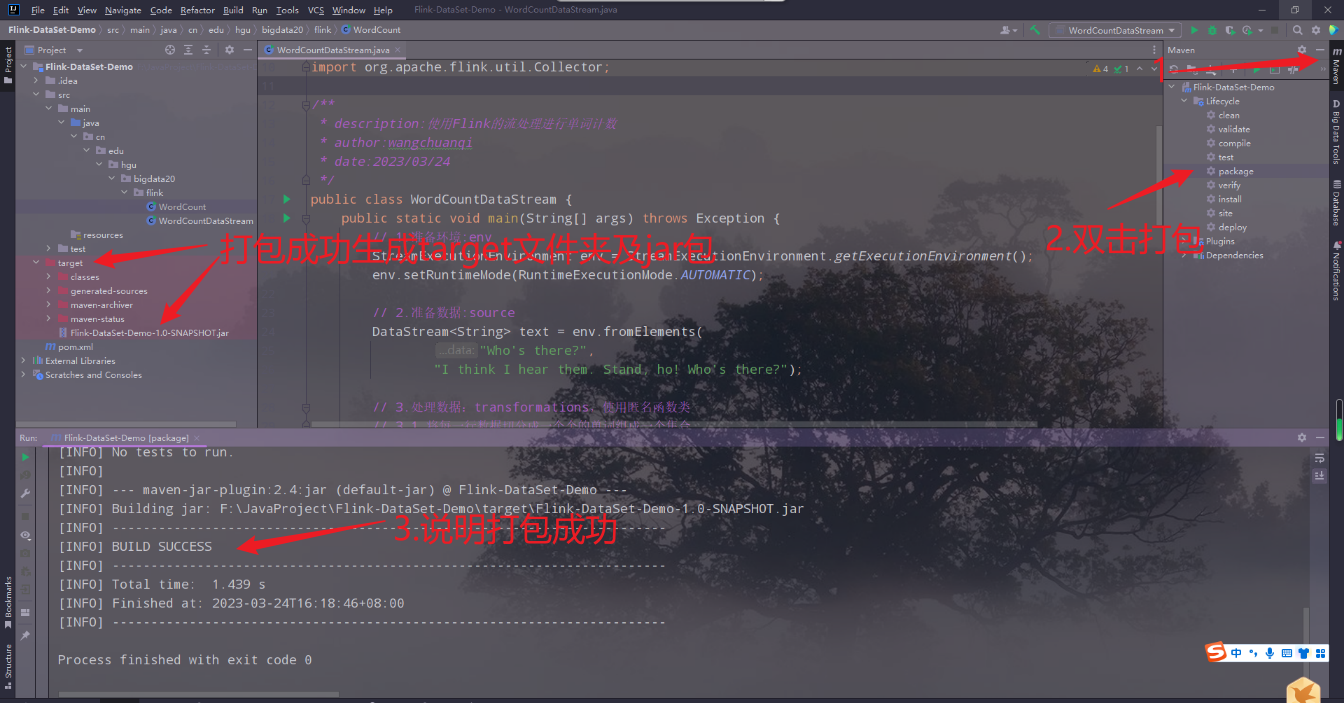
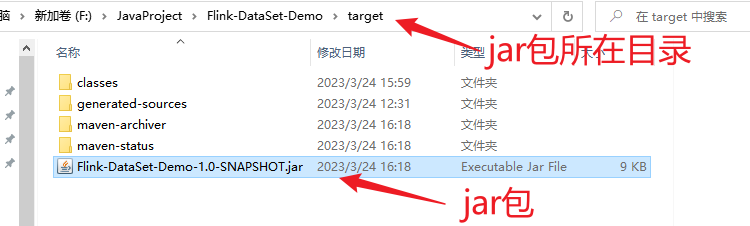
6.把打好的jar包上传服务器
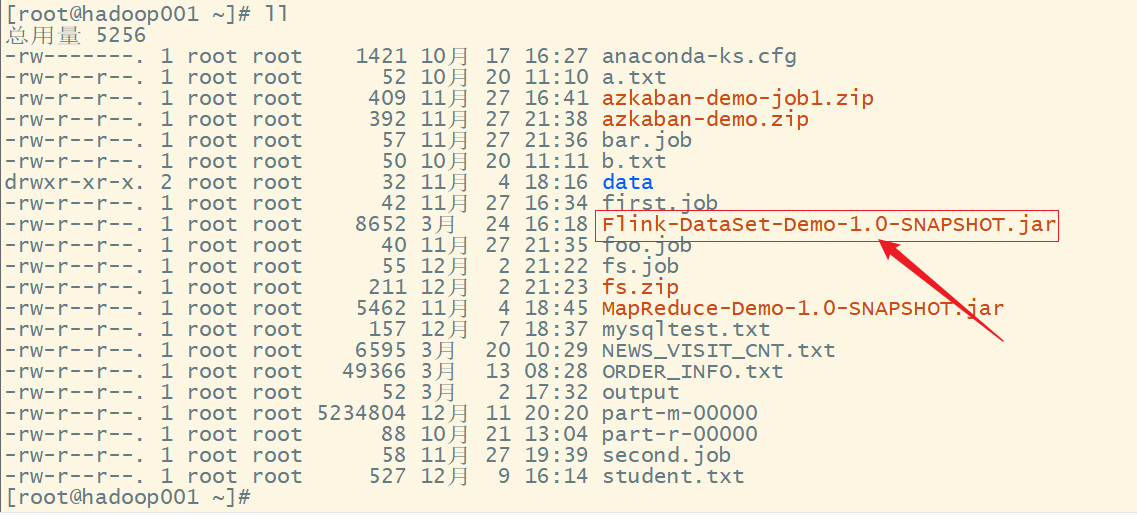
找到 jar 包所在目录:
上传 jar 包:

7.以per-job模式提交任务
flink run -m yarn-cluster -yjm 1024 -ytm 1024 Flink-DataSet-Demo-1.0-SNAPSHOT.jar
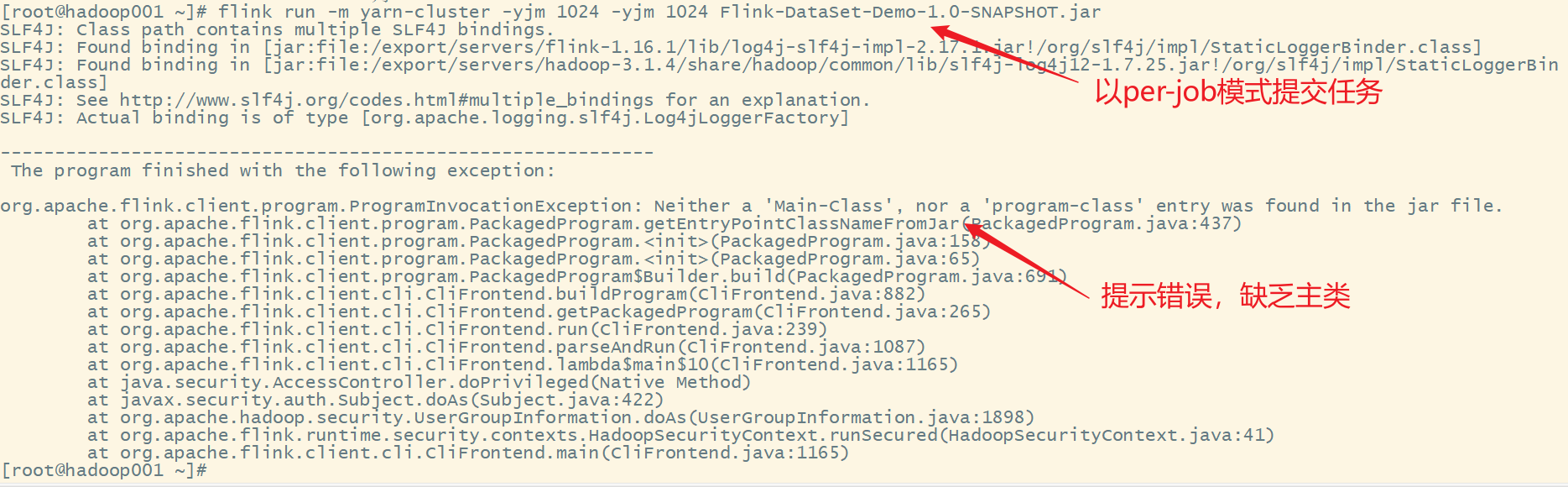
8.获取主类完整名称
cn.edu.hgu.bigdata20.flink.WordCount
9.指定主类重新提交
flink run -m yarn-cluster -yjm 1024 -ytm 1024 -c cn.edu.hgu.bigdata20.flink.WordCount Flink-DataSet-Demo-1.0-SNAPSHOT.jar

10.在yarn的web ui上查看执行过程
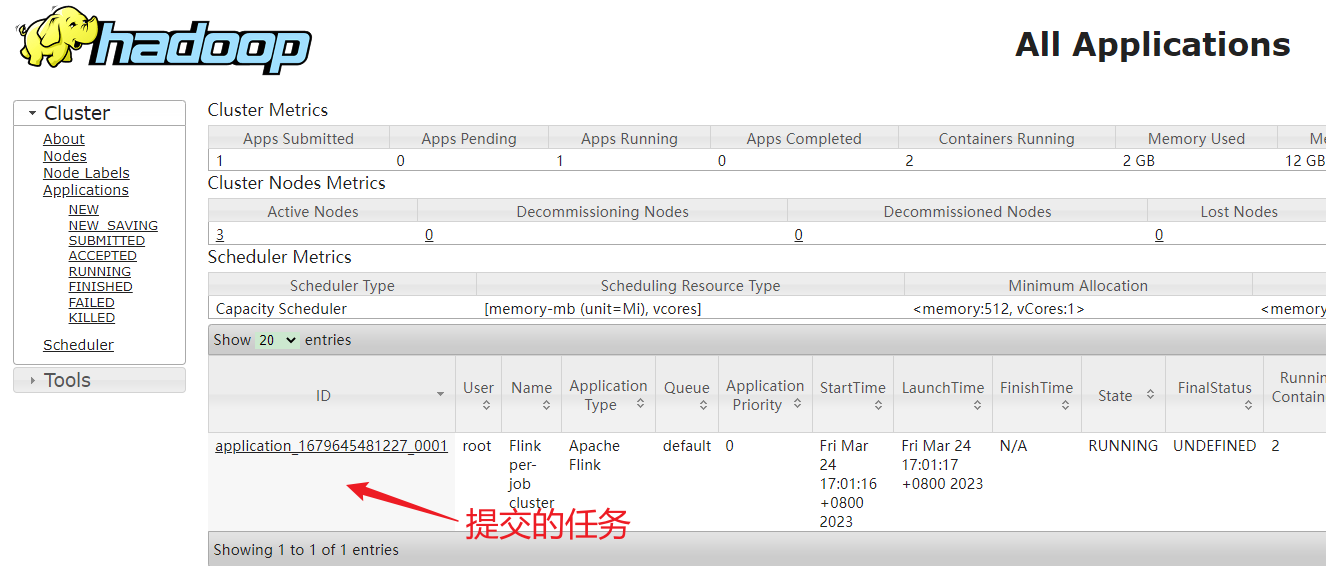
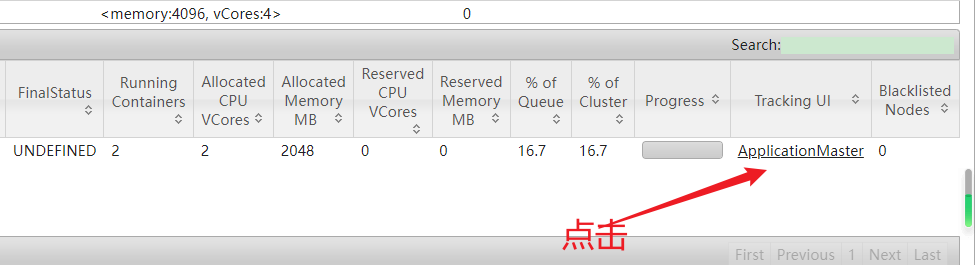
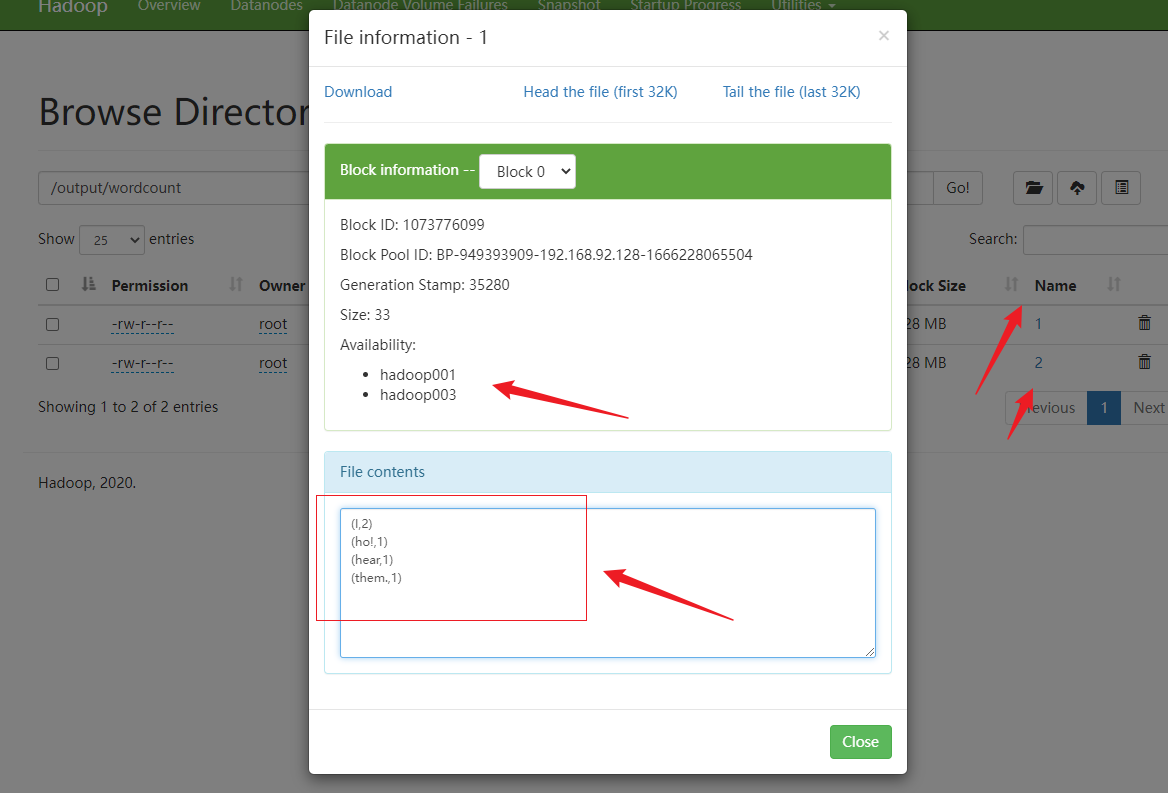
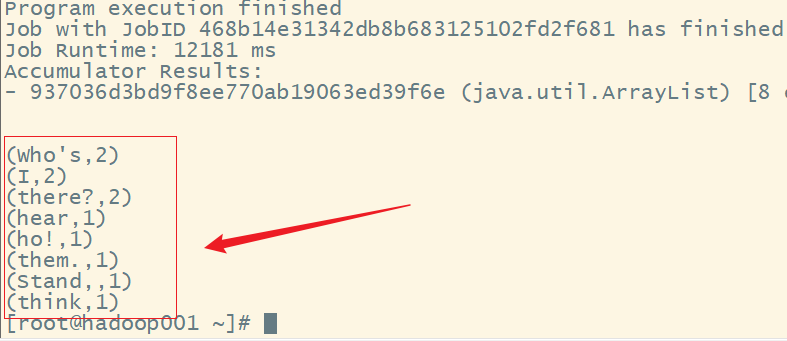
11.查看执行结果
12.获取流处理程序的完整类名,再次以流处理程序提交集群执行
cn.edu.hgu.bigdata20.flink.WordCountDataStream
提交任务
flink run -m yarn-cluster -yjm 1024 -ytm 1024 -c cn.edu.hgu.bigdata20.flink.WordCountDataStream Flink-DataSet-Demo-1.0-SNAPSHOT.jar

yarn的web ui查看
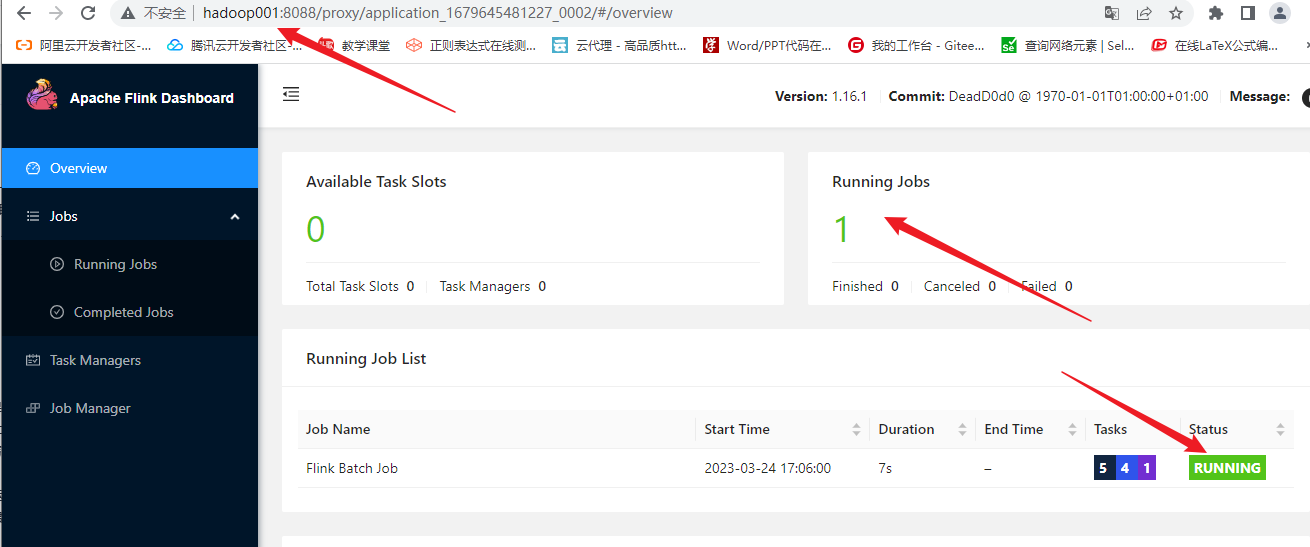
查看结果
13.修改流处理类的代码
package cn.edu.hgu.bigdata20.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* description:使用Flink的流处理进行单词计数
* author:wangchuanqi
* date:2023/03/24
*/
public class WordCountDataStream {
public static void main(String[] args) throws Exception {
// 1.准备环境:env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.准备数据:source
DataStream<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
// 3.处理数据:transformations,使用匿名函数类
// 3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordDS = text.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
// 参数s代表一行行的文本数据,将其切割为一个个的单词
String[] words = s.split(" ");
// 将切割的每一个单词收集起来成为一个集合
for (String word : words) {
collector.collect(word);
}
}
});
// 3.2 使集合中的每一个单词记为1,组成一个二元组
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
// 此处的s就是传过来的一个个单词,他跟1组成一个二元组
return Tuple2.of(s, 1);
}
});
// 3.3 对新的集合按照key,也就是单词进行分组
KeyedStream<Tuple2<String, Integer>, String> groupDS = wordAndOnesDS.keyBy(t -> t.f0);//lambda形式,fo表示二元组的第一个元素
// 3.4 对数据进行聚合
DataStream<Tuple2<String, Integer>> aggResult = groupDS.sum(1);//此处的1表示二元组的第二个元素
// 3.5 对结果进行排序
//DataSet<Tuple2<String, Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
// 4.输出结果:sink
aggResult.print();
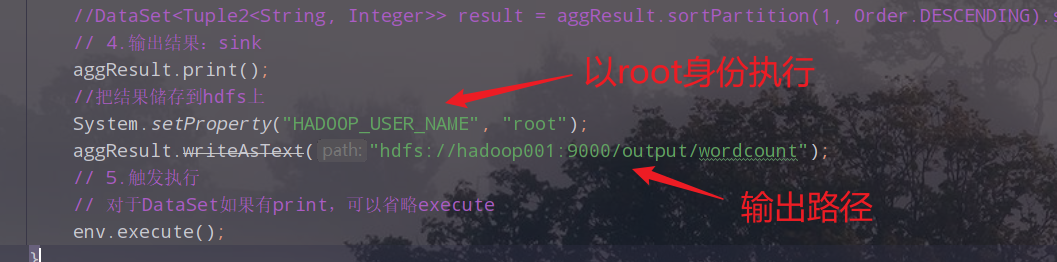
//把结果储存到hdfs上
System.setProperty("HADOOP_USER_NAME", "root");
aggResult.writeAsText("hdfs://hadoop001:9000/output/wordcount");
// 5.触发执行
// 对于DataSet如果有print,可以省略execute
env.execute();
}
}
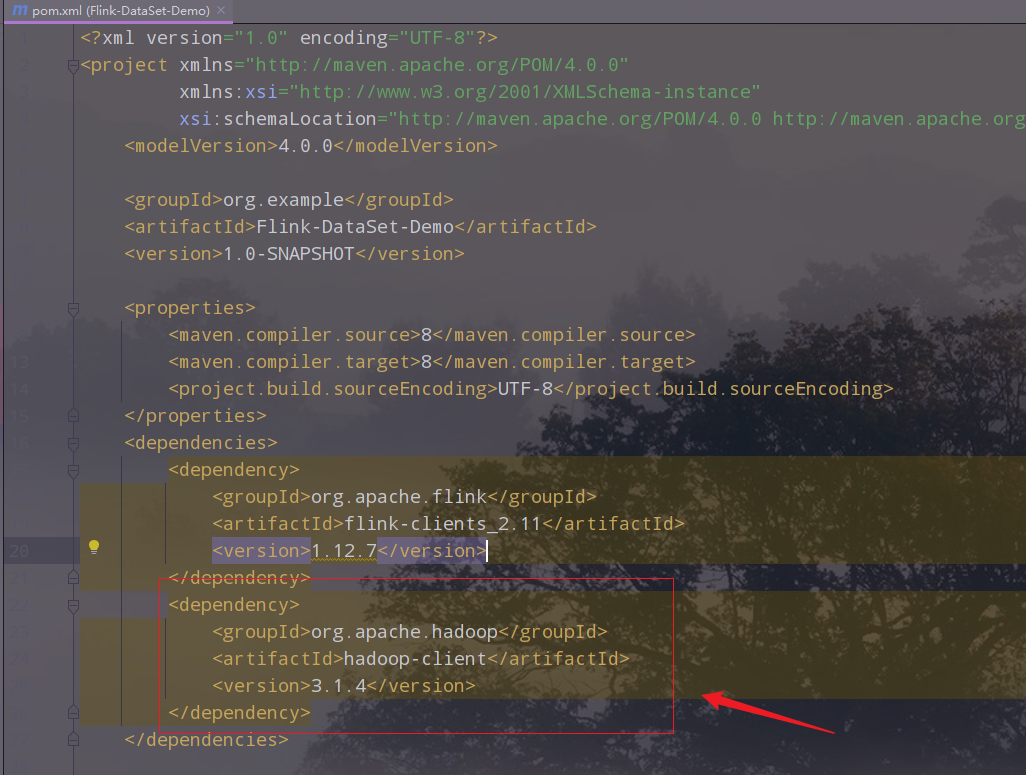
14.添加对Hadoop的支持
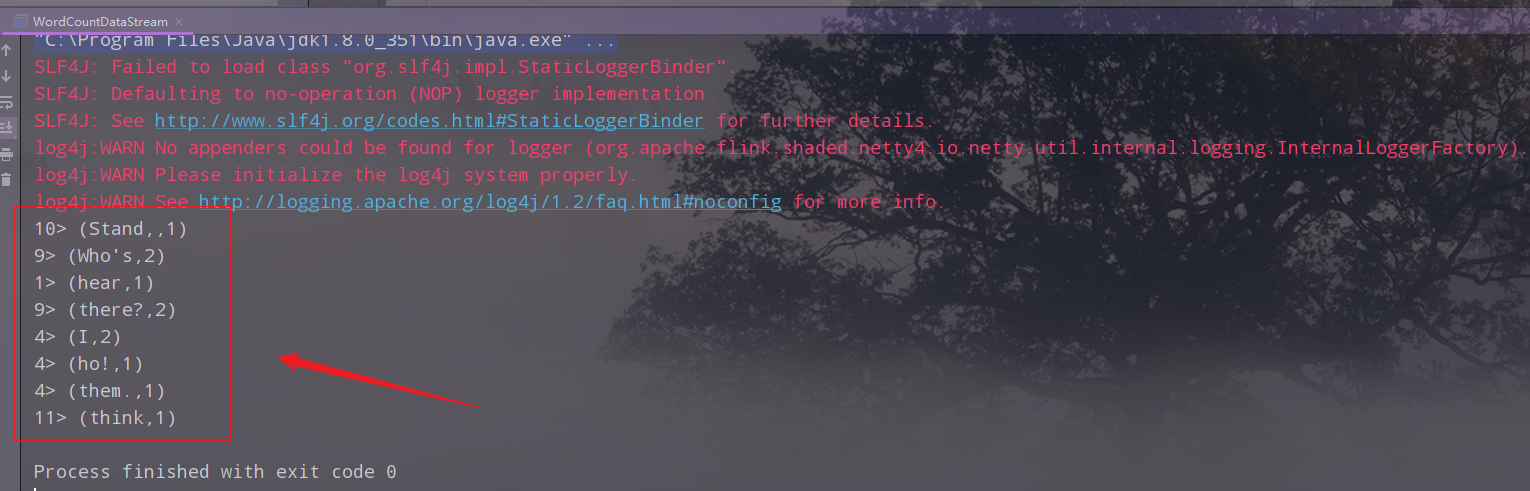
15.在本地进行测试,查看结果
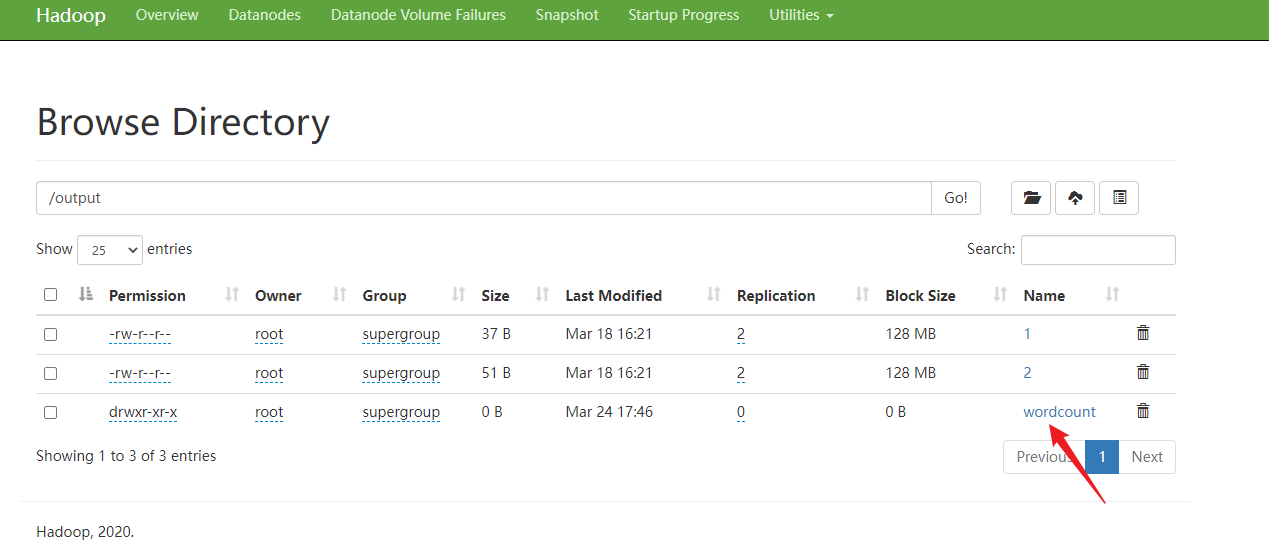
16.重新打包,上传服务器
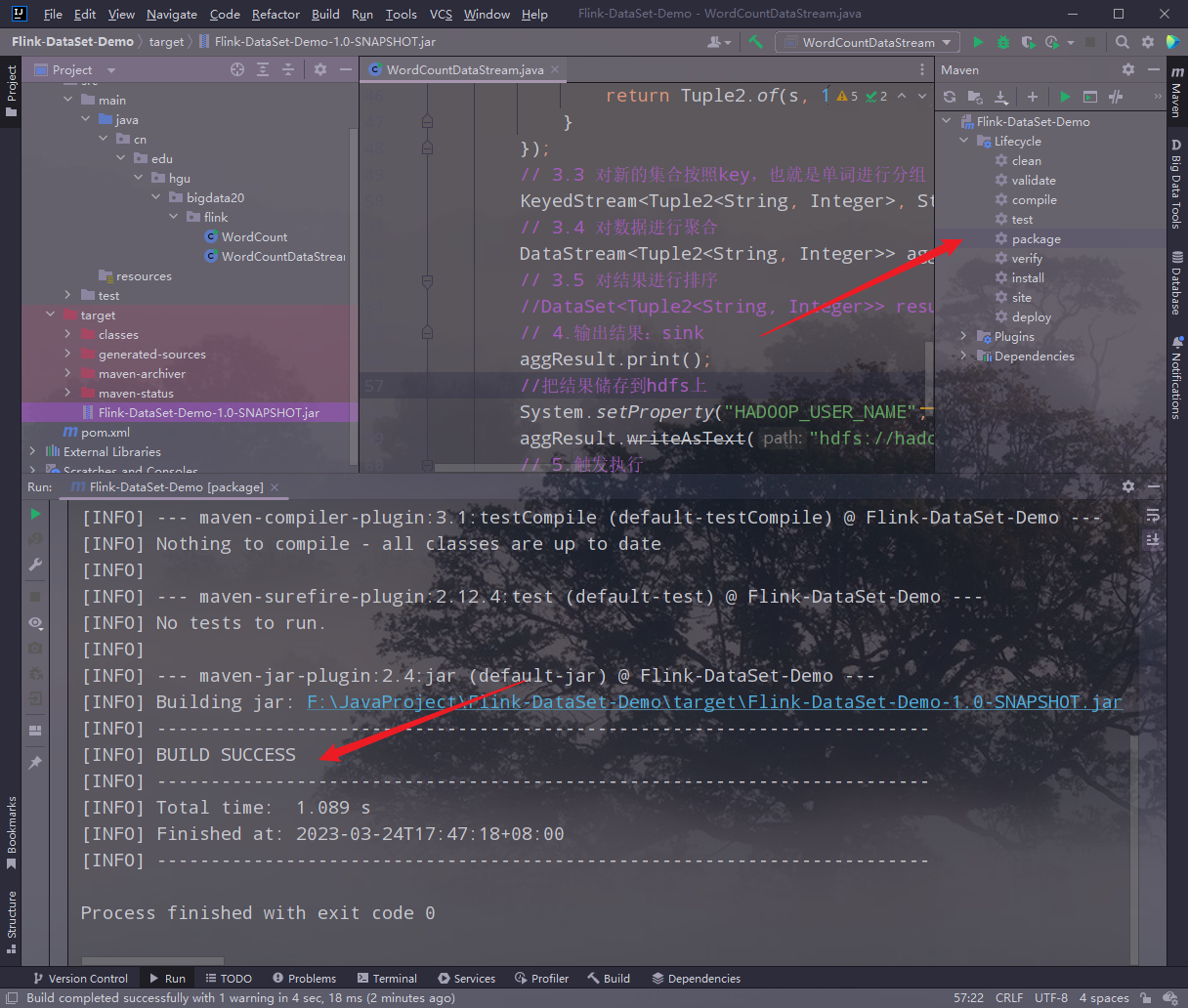
重新打包:
上传服务器:
注意:这里建议先关闭 IDEA,然后重新打开
jar包所在目录,
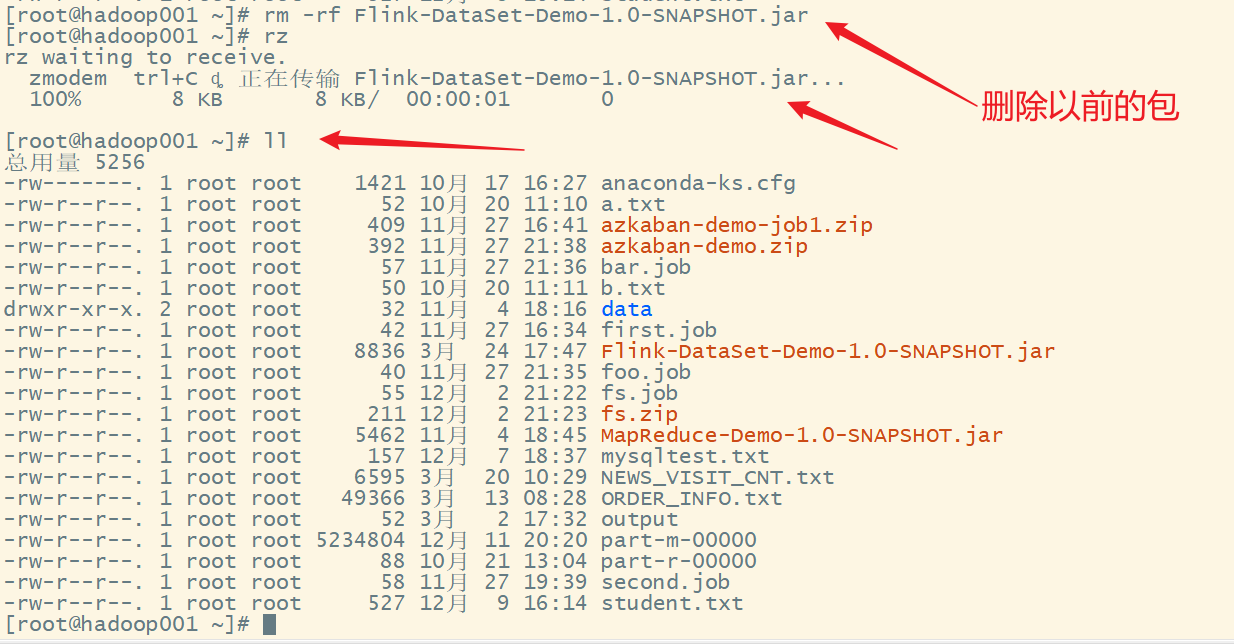
删除本地测试产生的的输出文件夹:

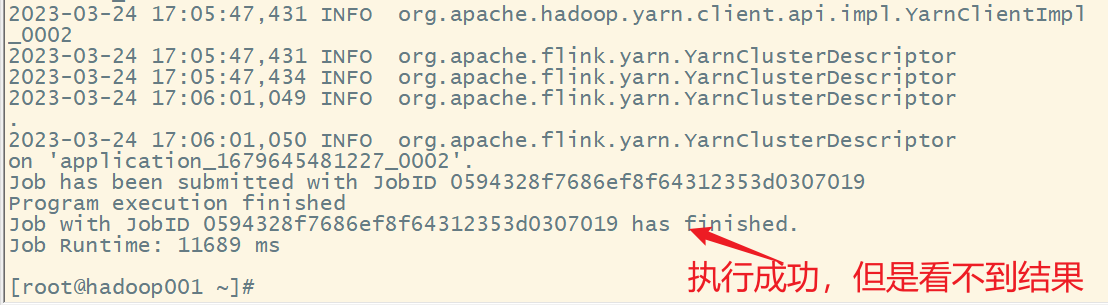
17.重新提交任务,并查看结果
flink run -m yarn-cluster -yjm 1024 -ytm 1024 -c cn.edu.hgu.bigdata20.flink.WordCountDataStream Flink-DataSet-Demo-1.0-SNAPSHOT.jar

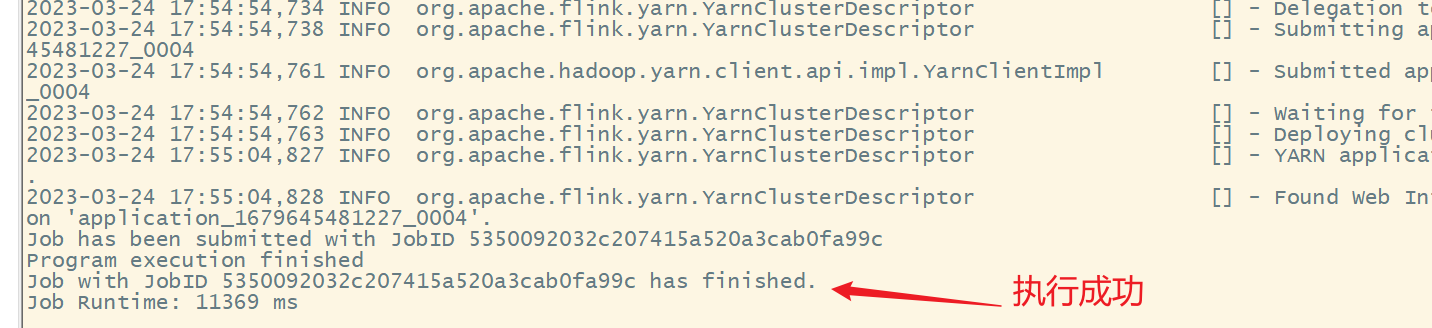
web ui查看
查看结果