写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Hadoop 3.x各模式部署 - Ubuntu
本文关键字:Hadoop、单机模式、为分布式、全分布式、Ubuntu
一、Hadoop介绍
Hadoop软件库是一个计算框架,可以使用简单的编程模型以集群的方式对大型数据集进行分布式处理。
1. Hadoop发展史及生态圈
- Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一。
- 2006年2月,成为一套完整而独立的软件,并被命名为Hadoop。
- 2008年1月,Hadoop成为Apache顶级项目。
- 2009年7月,MapReduce和HDFS成为Hadoop的独立子项目。
- 2010年5月,Avro脱离Hadoop项目,成为Apache顶级项目。
- 2010年5月,HBase脱离Hadoop项目,成为Apache顶级项目。
- 2010年9月,Hive脱离Hadoop项目,成为Apache顶级项目。
- 2010年9月,Pig脱离Hadoop项目,成为Apache顶级项目。
- 2011年1月,Zookeeper脱离Hadoop项目,成为Apache顶级项目。
- 2011年12月,Hadoop 1.0.0版本发布。
- 2012年10月,Impala加入Hadoop生态圈。
- 2013年10月,Hadoop 2.0.0版本发布。
- 2014年2月,Spark成为Apache顶级项目。
- 2017年12月,Hadoop 3.0.0版本发布。
- 2023年3月,Hadoop 3.3.5版本发布。
2. Hadoop核心功能及优势
- 分布式存储系统:HDFS
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的简称,是Hadoop生态系统中的核心项目之一,也是分布式计算中数据存储管理的基础。
- 分布式计算框架:MR
MapReduce是一种计算模型,核心思想就是“分而治之”,可以用于TB级的大规模并行计算。Map阶段处理后形成键值对形式的中间结果;Reduce对中间结果相同的“键”对应的“值”进行处理,得到最终结果。
- 资源管理平台:YARN
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,可以为上层应用提供统一的资源管理和调度,为集群的资源利用率、统一管理、数据共享等方面提供了便利。
- 高扩展
Hadoop是一个高度可扩展的存储平台,可以存储和分发超数百个并行操作的廉价的服务器集群。能够打破传统的关系数据库无法处理大量数据的限制,Hadoop能够提供TB级别数据的运算能力。
- 成本低
Hadoop可以将廉价的机器组成服务器集群来分发处理数据,成本较低,学习者及普通用户也能够很方便的在自己的PC上部署Hadoop环境。
- 高效率
Hadoop能够并发的处理数据任务,并且能够在不同的节点之间移动数据,可以保证各个节点的动态平衡。
- 容错性
Hadoop可以自动维护多份数据的副本,如果计算任务失败,Hadoop能够针对失败的节点重新处理。
3. 部署方式介绍
- 单机模式
单机模式是一个最简的安装模式,因为Hadoop本身是基于Java编写的,所以只要配置好Java的环境变量就可以运行了。在这种部署方式中我们不需要修改任何的配置文件,也不需要启动任何的服务,只需要解压缩、配置环境变量。
虽然配置很简单,但是能做的事情也是很少的。因为没有各种守护进程,所以分布式数据存储以及资源调度等等服务都是不能使用的,但是我们可以很方便的测试MapReduce程序。
- 伪分布模式
伪分布模式是学习阶段最常用的模式,可以将进程都运行在同一台机器上。在这种模式下,可以模拟全分布模式下的运行状态,基本上可以完成全分布模式下的所有操作,伪分布模式是全分布模式的一个特例。
- 全分布模式
在全分布模式下,会在配置文件中体现出主节点与分节点,可以指定哪些机器上运行哪些服务以达到的成本与效率的平衡。在企业中主要采用的都是全分布式模式,节点从数十个到上百个不等。在学习阶段,如果个人PC的性能足够强劲,也可以使用多台虚拟机代替。
二、Hadoop下载
1. 下载地址
在百度中搜索Hadoop,前两条就会显示我们需要的网站,目前Hadoop属于Apache基金会,所以我们打开网址时注意一下是apache.org。
进入后来到Hadoop的官网,点击Download就可以打开下载界面:https://hadoop.apache.org/releases.html。

2. 版本选择
现在我们使用的是开源社区版,目前的主流版本为2.x.y和3.x.y。

在选择Hadoop的版本时,我们应该考虑到与其他生态圈软件的兼容问题。通常的组建方式有两种:
- 根据各组件的兼容性要求手动选择版本并搭建
- 使用CDH(Cloudera’s Distribution Including Apache Hadoop)自动选择版本并解决兼容问题
在学习阶段,由于进行的操作比较简单,不需要特别的在意版本的兼容问题,但是建议两种方式大家都能够去进行了解和实践。
3. 安装包下载
目前的3.x版本中已经支持了对于不同系统架构的支持,但是对于安装过程和使用都无影响,本文以3.3.5为例。source为软件源码,binary为所需,根据系统架构点击链接进入:

点击任意一个镜像地址开始下载,直击链接:
- 【x64】https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
- 【arm】https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5-aarch64.tar.gz
可以直接使用wget命令下载到Linux系统。

三、前置环境
Hadoop的运行需要Java环境,先确保已经正确安装配置JDK。
1. 检查已有JDK环境
可以使用java -version来验证已经安装的版本,也可以使用以下命令:
update-java-alternatives --list

使用该命令时需要预先安装java-common:sudo apt install java-common
2. 卸载不需要的版本
如果已经安装的版本不是所需要的,可以先进行卸载,软件名称就是上文中查询到的。
sudo apt remove java-1.8.0-openjdk-arm64
3. 安装对应版本的JDK
JDK 1.8版本基本可以和所有的大数据生态圈组件很好的兼容,如果需要也可以换成其它版本,建议提前确认好版本兼容性。
sudo apt install openjdk-8-jdk
安装完成后可以使用java -version命令进行验证。

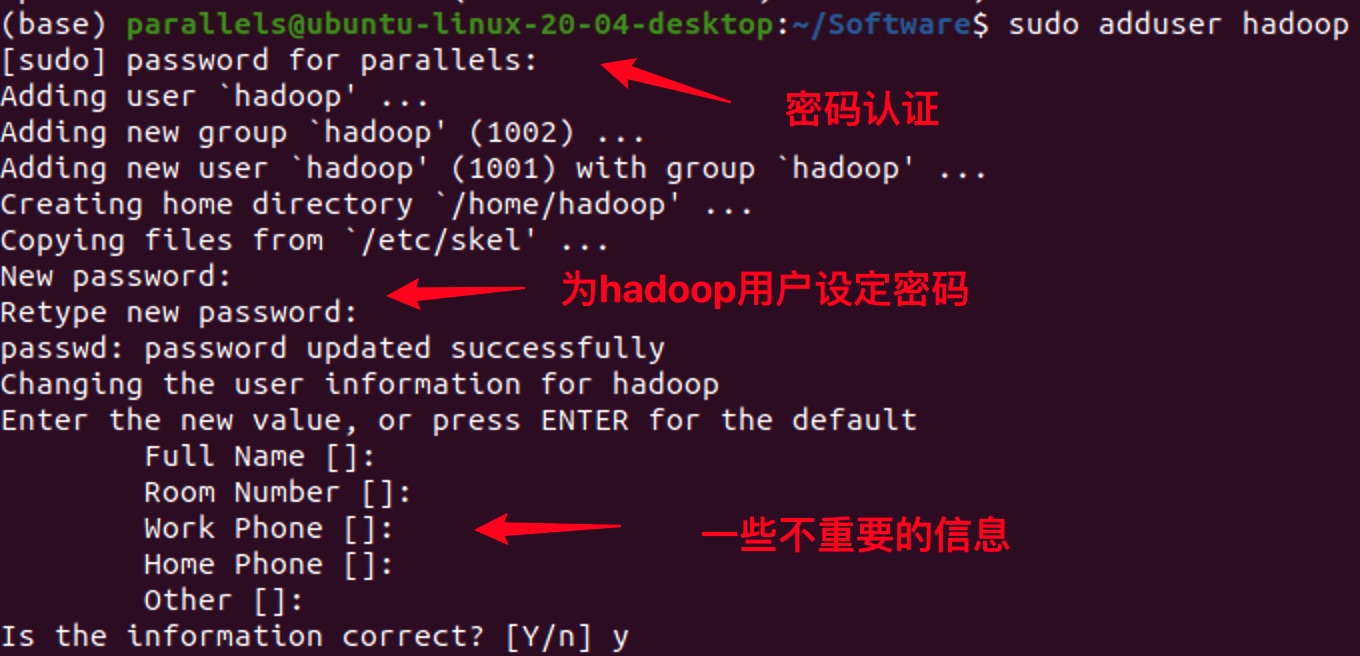
4. 创建Hadoop用户
使用大数据生态圈组件,建议创建一个单独的用户,如:hadoop。
sudo adduser hadoop
可以将hadoop用户添加到sudo组,使其拥有更高的权限:
sudo usermod -aG sudo hadoop
修改Hadoop软件压缩包的所属为hadoop:
sudo chown hadoop:hadoop hadoop-3.3.5-aarch64.tar.gz

移动软件包至hadoop用户家目录,并切换到hadoop用户:
sudo mv ~/Software/hadoop-3.3.5-aarch64.tar.gz /home/hadoop/
su - hadoop

四、本地模式
Hadoop的本地模式即不需要启动任务服务进程,仅仅通过携带的软件环境运行计算任务,可以方便的进行程序测试。
1. 解压安装
- 解压缩
tar -zvxf hadoop-3.3.5-aarch64.tar.gz
- 环境变量配置
由于使用的是apt安装的JDK,系统当中并没有配置JAVA_HOME变量,可以通过上文提到的命令查看安装位置。

编辑家目录下的.bashrc文件,可在文件结尾写入以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/home/hadoop/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 刷新测试
配置完成后使其立即生效,并通过hadoop命令进行测试:
source ~/.bashrc
hadoop version

2. 运行测试
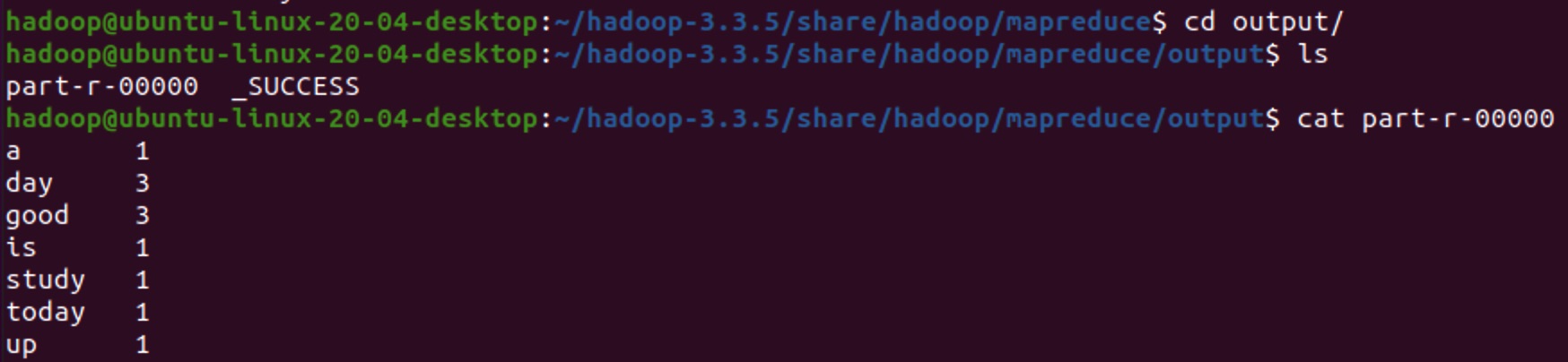
Hadoop本身自带了一个案例jar包,可以让我们直接执行一个Hello World,路径为share/hadoop/mapreduce。

- 测试数据准备
新建一个txt文件,注意保存的路径【可以直接在jar包所在路径下创建】,读取时需要用到。
touch data.txt
vi data.txt
# 在文件中写入以下内容
good good study
day day up
today is a good day
- 运行计算任务
- wordcount:jar包中自带的一个可执行类
- data.txt:数据输入文件路径
- output:结果输出文件夹名称【需要指定一个还不存在的目录】
进入到example的jar包所在路径,执行以下命令:
hadoop jar hadoop-mapreduce-examples-3.3.5.jar wordcount data.txt output
五、伪分布模式
伪分布模式的实现方式是只使用一台机器,启动所有进程,可以进一步模拟集群运行时的任务状态,部署更加简单。【解压安装步骤同上】
配置文件路径:$HADOOP_HOME/etc/hadoop
1. hadoop-env.sh
在文件第37行打开注释【去掉开头的#】,配置JAVA_HOME:
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64
2. core-site.xml
官方文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
<configuration>
<!-- Hadoop临时文件存放路径,默认在/tmp目录下 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.3.5/data</value>
</property>
<!-- NameNode结点的URI(包括协议、主机名称、端口号) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:8020</value>
</property>
<!-- 设置文件文件删除后,被完全清空的时间,默认为0,单位为分钟 -->
<property>
<name>fs.trash.interval</name>
<value>60</value>
</property>
</configuration>
3. hdfs-site.xml
<configuration>
<!-- 块存储份数,默认为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭权限校验,开发学习时可开启,默认为true -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- namenode的http访问地址和端口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop:50070</value>
</property>
</configuration>
4. mapred-site.xml
<configuration>
<!-- 设置运行MapReduce任务方式为yarn,默认为local,可选项还有classic -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5. yarn-site.xml
官方文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
<configuration>
<!-- resourcemanager的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- 分配给容器的物理内存量,单位是MB,设置为-1则自动分配,默认8192MB -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>vi
<value>1536</value>
</property>
<!-- NodeManager上运行的服务列表,可以配置成mapreduce_shuffle,多个服务使用逗号隔开 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6. workers
工作节点的主机名列表,默认为localhost,建议修改为自定义的主机名并绑定,详情见下一步骤。
hadoop
7. SSH免密登录
在使用Hadoop集群时,建议使用主机名称,这样即使ip地址发生变化,也不需要去修改相关的配置文件,只需要去修改一下主机名映射文件就可以了。上文的配置文件中都使用了hadoop作为主机名,以此为例进行演示。
- Ubuntu修改主机名
在root用户下修改主机名设置文件:
sudo hostnamectl set-hostname hadoop

此时已经修改成功,打开一个新的回话和终端时将看到变化。
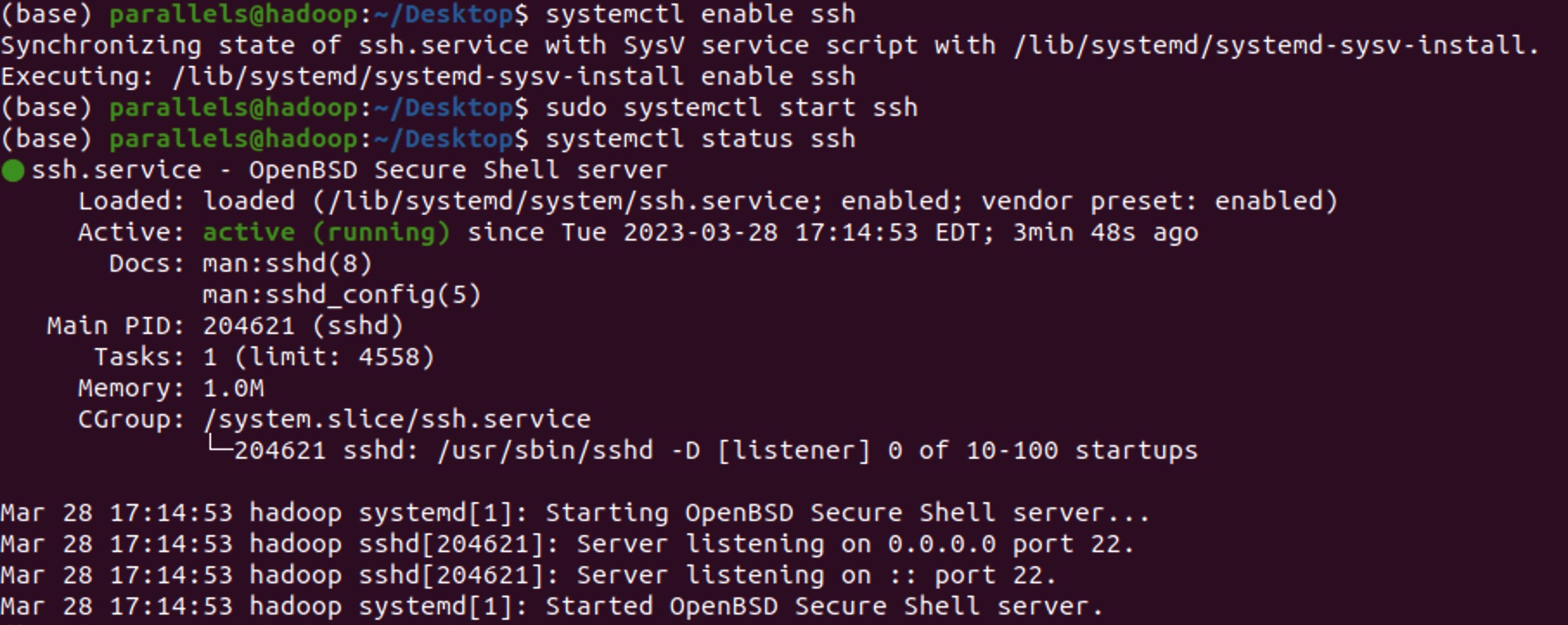
- 开启SSH服务
首先确认SSH服务状态:
systemctl status ssh
如果没有安装使用以下命令:
apt-get install openssh-server
启动SSH服务:
sudo systemctl enable ssh
sudo systemctl start ssh
systemctl status ssh
- 生成密钥
# 切换到hadoop用户下执行
su - hadoop
# 整个过程一直回车即可
ssh-keygen -t rsa
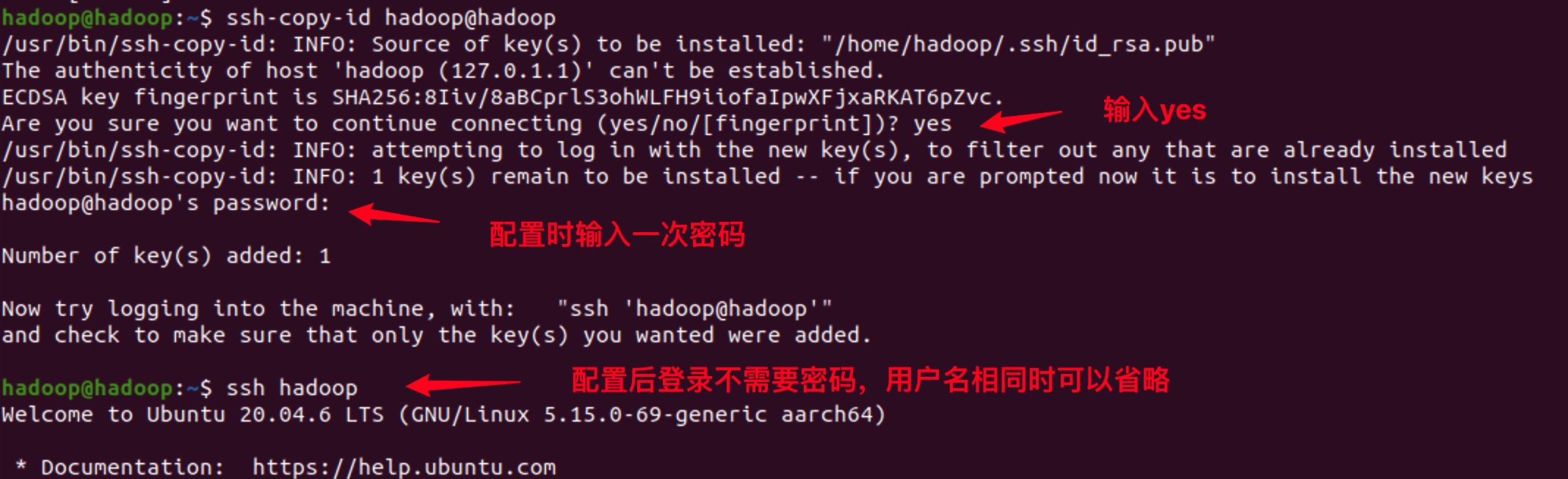
- 配置免密登录
Hadoop启动时,会逐一登录到worker节点去启动相应的进程,对于伪分布模式来说,相当于自己登录自己。配置免密登录后,不再需要密码,而是通过密钥进行认证。
ssh-copy-id hadoop@hadoop
ssh hadoop
8. 集群启动
至此,所有的安装配置步骤都已完成,接下来准备启动Hadoop。
- 首次格式化
第一次启动前需要进行格式化,用以生成集群UUID等核心信息。
hdfs namenode -format
- 启动Hadoop
执行start-all.sh即可启动集群,遇到的警告忽略即可【10秒后会自动启动】,也可以按顺序启动dfs和yarn。
start-all.sh
- 进程验证
启动成功后,使用jps命令查看各java进程:

出现5个进程证明成功【不包括jps】,如果缺少某个进程请返回检查配置文件,停止所有进程后【stop-all.sh】再次重新启动。
六、全分布模式
全分布模式的配置方式和步骤其实与伪分布式没有任何差别,在一台机器上配置好所有的配置文件后,分发到其它机器即可,核心步骤如下:
1. 前置环境
- 部署安装JDK【三台机器】
- 解压安装Hadoop【主节点】
- 创建hadoop用户【三台机器】
- 配置环境变量【主节点】
2. 修改配置文件
有部分核心配置文件需要修改:
- core-site.xml
修改其中的fs.defaultFS:主机名的部分设置为主节点的主机名
- hdfs-site.xml
修改其中的dfs.replication:设置为实际的数据存储节点个数
- yarn-site.xml
修改其中的yarn.resourcemanager.hostname:设置为主节点的主机名
- workers
将所有的worker节点的主机名列在这个文件中,每行一个。
3. 配置免密登录
假设我们有3台机器:hadoop01、hadoop02、hadoop03,每一台机器都执行如下操作:
# 在hadoop用户下执行
ssh-keygen -t rsa
ssh-copy-id hadoop@hadoop01
ssh-copy-id hadoop@hadoop02
ssh-copy-id hadoop@hadoop03
这样执行完成后,三台机器都可以免密互相登录,这样以后我们可以在任意一台机器上控制集群状态或者提交任务。
4. 文件分发
以上的步骤只需要在主节点做一次即可,然后我们将配置文件分发到另外两台机器。也就是说,三台机器的配置文件和环境是完全一致的,如果配置文件发生修改,也要记得手动同步覆盖。
scp -r /home/hadoop/hadoop-3.3.5 hadoop@hadoop02:/home/hadoop
scp -r /home/hadoop/hadoop-3.3.5 hadoop@hadoop03:/home/hadoop
scp -r /home/hadoop/.bashrc hadoop@hadoop02:/home/hadoop
scp -r /home/hadoop/.bashrc hadoop@hadoop03:/home/hadoop
由于我们已经配置了免密登录,整个过程不需要密码。
5. 集群启动
剩下的启动步骤与伪分布式相同,先进行一次格式化,然后执行启动脚本。
- 格式化namenode
在主节点上执行以下命令:
hdfs namenode -format
- 启动Hadoop进程:
在主节点上执行,会根据workers文件的配置逐一去启动各个节点上的进程。
start-all.sh
如果在workers文件中填写了主节点,则在主节点中应该出现5个进程(不包括jps本身),否则为3个:NameNode、SecondaryNameNode、ResourceManager。
从节点上会出现两个进程:DataNode、NodeManager,如果以上进程都成功启动,那么你的集群配置已经完成了。
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~
