写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Spark 3.x各模式部署 - Ubuntu
本文关键字:Spark、单机模式、为分布式、全分布式、Ubuntu
文章目录
一、Spark介绍
Spark是一种计算框架,可以使用简单的编程模型对大型数据集进行快速、通用、分布式处理。
1. Spark发展史及生态圈
- 2009年,Spark项目在加州大学伯克利分校AMPLab实验室诞生。
- 2010年,Spark被开源,并在GitHub上发布。
- 2013年,Spark成为Apache项目的孵化器项目。
- 2014年2月,Spark成为Apache顶级项目。
- 2014年,Databricks公司成立,致力于支持和发展Spark生态系统。
- 2015年,Spark 1.0.0版本发布。
- 2016年,Spark 2.0.0版本发布。
- 2018年,Spark 2.3.0版本发布。
- 2020年,Spark 3.0.0版本发布。
2. Spark核心功能及优势
- 通用计算引擎
Spark作为一个通用计算引擎,可以支持批处理、流处理、交互式查询和机器学习等多种数据处理场景。
- 弹性分布式数据集:RDD
RDD(Resilient Distributed Dataset)是Spark中的基本数据结构,它是一个不可变的分布式对象集合。RDD具有容错、并行处理等特点,是Spark中数据处理的核心概念。
- 高性能
Spark使用内存计算,相比于Hadoop的MapReduce,Spark可以大幅提高数据处理速度。同时,Spark还支持数据存储格式优化、查询优化等功能,进一步提高计算性能。
- 易用性
Spark支持Scala、Java、Python和R等多种编程语言,用户可以选择自己熟悉的语言进行开发。同时,Spark提供了丰富的API和库,降低了开发难度。
- 生态系统
Spark拥有丰富的生态系统,包括Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图计算库)等组件,可以方便地处理各种类型的数据和应用场景。
3. 部署方式介绍
- 本地模式
本地模式是一个最简的安装模式,在这种模式下,Spark可以在单机上运行,适合学习和测试。
- 伪分布式模式
伪分布式模式也是学习阶段较常用的模式,在这种模式下,所有的Spark进程都运行在同一台机器上。这种模式可以模拟分布式模式下的运行状态,基本上可以完成分布式模式下的所有操作。
- 全布式模式
在分布式模式下,Spark可以在集群中部署,将计算任务分布在多个节点上进行处理。分布式模式可以充分利用集群资源,提高计算性能和容错能力。在企业中主要采用的都是分布式模式,节点从数十个到上百个不等。在学习阶段,如果个人PC的性能足够强劲,也可以使用多台虚拟机代替。
二、Spark下载
1. 下载地址
在百度中搜索Spark,第一条就会显示我们需要的网站,目前Spark属于Apache基金会,所以我们打开网址时注意一下是apache.org。
进入后来到Spark的官网,点击Download就可以打开下载界面:https://spark.apache.org/downloads.html。

2. 版本选择
现在我们使用的是开源社区版,目前的主流版本为2.x.y和3.x.y。
在选择Hadoop的版本时,我们应该考虑到与其他生态圈软件的兼容问题。通常的组建方式有以下几种:
- 根据各组件的兼容性要求手动选择版本并搭建
- 使用CDH(Cloudera’s Distribution Including Apache Hadoop)自动选择版本并解决兼容问题
- 使用Databricks(Databricks Unified Analytics Platform)自动选择版本并解决兼容问题
在学习阶段,由于进行的操作比较简单,不需要特别的在意版本的兼容问题,但是建议对各种方式都能有所了解。
3. 安装包下载
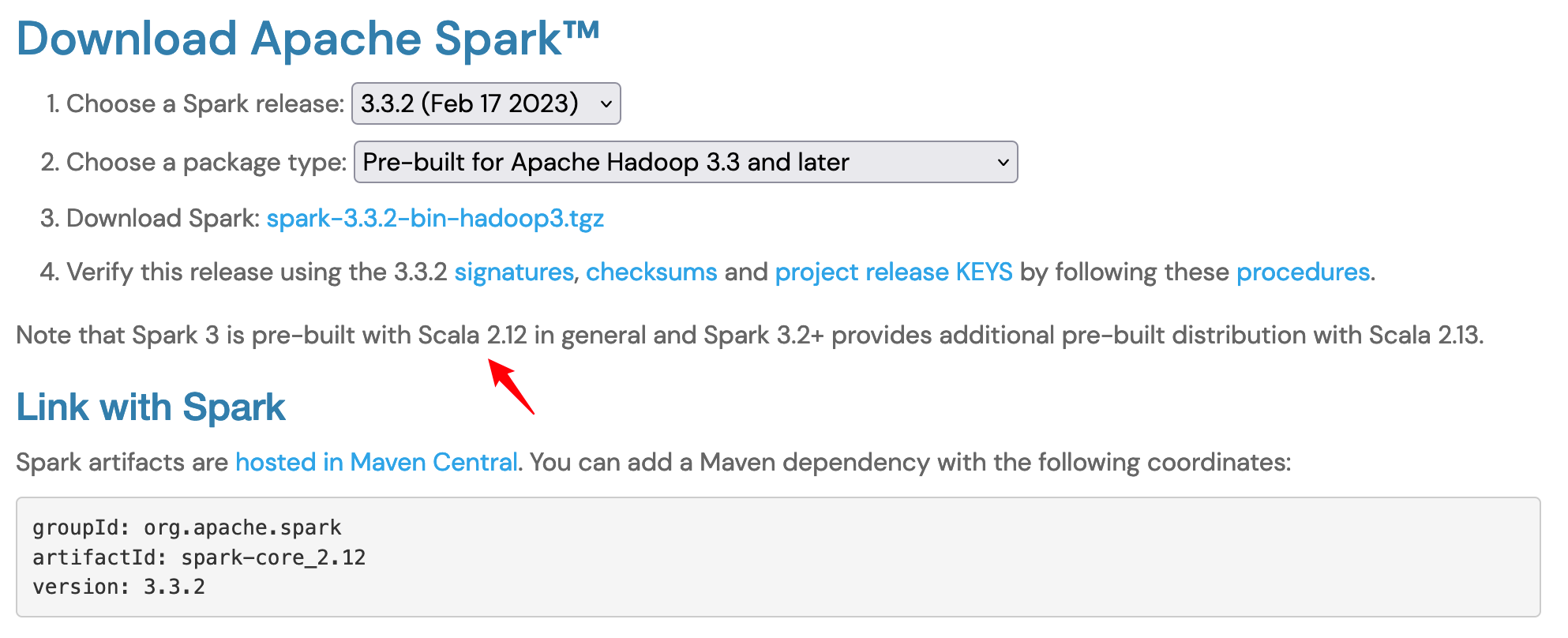
目前的3.x版本中对于不同版本的scala进行了支持,默认使用2.12,这会直接影响到计算程序运行时的兼容性,选择时请尤为注意。本文以3.3.2为例:

点击选项3中的链接进入镜像选择页面,直击链接:https://www.apache.org/dyn/closer.lua/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz。
可以直接使用wget命令下载到Linux系统。

三、前置环境
Spark需要Scala环境才能够运行,Scala依赖Java虚拟机,所以需要预先配置好JDK和Scala。
1. JDK安装
- 检查已有JDK环境
update-java-alternatives --list

使用该命令时需要预先安装java-common:sudo apt install java-common
- 卸载不需要的版本
如果已经安装的版本不是所需要的,可以先进行卸载,软件名称就是上文中查询到的。
sudo apt remove java-1.8.0-openjdk-arm64
- 安装对应版本的JDK
目前Spark 3.x的主要兼容版本为Scala 2.12.x和2.13.x,使用JDK 1.8就可以很好的兼容。
sudo apt remove java-1.8.0-openjdk-arm64
安装完成后可以使用java -version命令进行验证。

- 配置环境变量

使用apt的方式安装JDK后,环境变量中并没有JAVA_HOME,需要手动配置一下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64
export PATH=$PATH:$JAVA_HOME/bin
2. Scala安装
如果使用apt工具进行Scala的安装需要添加软件源,并且同样需要配置环境变量,所以这里我们使用解压安装的方式。
- 下载地址
我们以Scala 2.12版本为例,目前的最新版为2.12.17,复制tgz软件包下载链接。
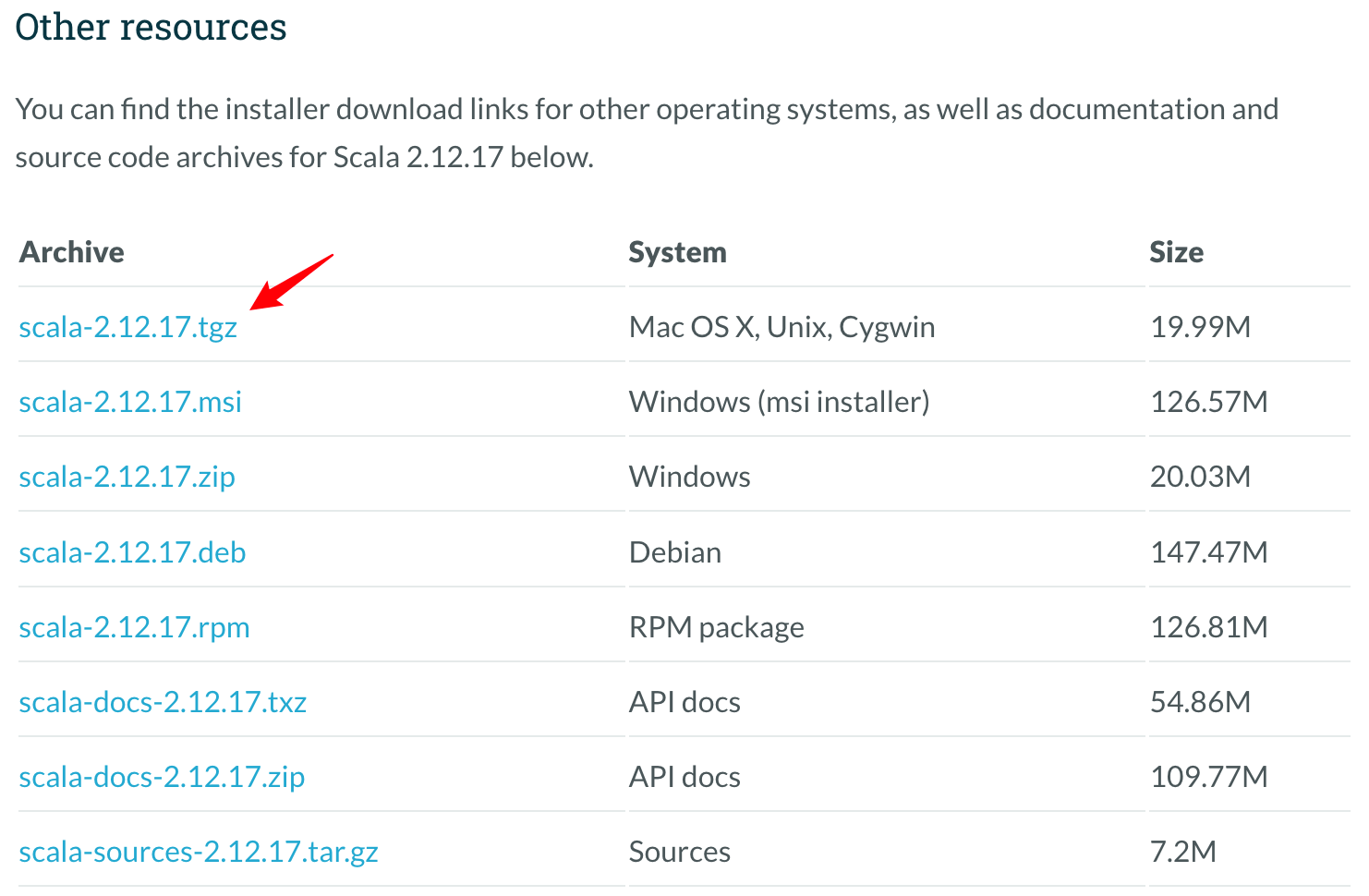
- 解压安装
使用wget命令下载,并解压缩
wget https://downloads.lightbend.com/scala/2.12.17/scala-2.12.17.tgz
tar -zvxf scala-2.12.17.tgz

- 环境变量配置
编辑.bashrc文件,添加Scala相关路径。
vi ~/.bashrc
# 文件结尾添加以下内容
export SCALA_HOME=/home/hadoop/scala-2.12.17
export PATH=$PATH:$SCALA_HOME/bin
配置完成后保存退出,并使用命令进行版本验证。
source .bashrc
scala -version

3. 创建单独账户
使用大数据生态圈组件,建议创建一个单独的用户,如:hadoop。
sudo adduser hadoop
可以将hadoop用户添加到sudo组,使其拥有更高的权限:
sudo usermod -aG sudo hadoop
修改Spark软件压缩包的所属为hadoop:
sudo chown hadoop:hadoop hadoop-3.3.5-aarch64.tar.gz
移动软件包至hadoop用户家目录,并切换到hadoop用户:
sudo mv /path/to/spark-3.3.2-bin-hadoop3.tgz /home/hadoop/
su - hadoop
四、本地模式
Spark的本地模式不需要启动任何进程,主要为了方便验证算法的可行性,能够启用的资源有限,可以使用多线程。
1. 解压安装
- 解压缩
tar -zxvf tar -zvxf spark-3.3.2-bin-hadoop3.tgz
- 环境变量配置
在.bashrc文件结尾添加以下内容:
export SPARK_HOME=/home/hadoop/spark-3.3.2-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
- 刷新测试
配置完成后使其立即生效,并通过spark-shell命令进行测试【使用:q退出】:
source ~/.bashrc
spark-shell

2. 运行测试
如果你能够正常的使用spark-shell,已经足以说明安装过程已经完成了,在spark-shell输出的日志中,可以清楚的看到,开启了一个本地模式master = local并创建了Spark Context对象,可以在交互环境里直接使用sc。
- 找到自带案例
这里我们去运行一个自带的程序,当然你也可以继续在spark-shell里面玩耍。进入到Spark的examples路径下,可以看到一个jar包:spark-examples_2.12-3.3.2.jar,我们将其作为一个计算任务提交。

- 提交计算任务
使用spark-submit提交一个最简单的圆周率输出任务,命令如下:
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /home/hadoop/spark-3.3.2-bin-hadoop3/examples/jars/spark-examples_2.12-3.3.2.jar 10
执行后,将以本地模式开启两个线程,参数10为样本个数,也可以理解为精度。如果我们使用1000将会运行更长的时间,但是结果会更加精确,如图:

五、伪分布模式
对于Spark来说,需要修改的配置文件比较少,只需要指定好端口号以及相关的环境、分配的资源即可。
配置文件路径:$SPARK_HOME/conf
1. spark-env.sh
- 重命名文件
mv spark-env.sh.template spark-env.sh
- 修改配置
编辑spark-env.sh文件,找到对应配置打开注释或者直接添加新的一行:
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64
SPARK_MASTER_HOST=hadoop
SPARK_MASTER_PORT=7077
# 默认为8080,如果有冲突可以修改
SPARK_MASTER_WEBUI_PORT=18080
# 如果已经配置好Hadoop【非必需】
HADOOP_CONF_DIR=/home/hadoop/hadoop-3.3.5/etc/hadoop
2. spark-defaults.conf
- 重命名文件
mv spark-defaults.conf.template spark-defaults.conf
- 修改配置
在这个配置文件中可以修改一些在运行过程中的默认设置,也可以在提交计算任务时手动指定,可根据需要进行配置。
# Spark 主节点的地址和端口号
spark.master spark://hadoop:7077
# Spark Driver内存分配
spark.driver.memory 1g
# Spark Executor内存分配
spark.executor.memory 1g
# Spark Executor内核分配
spark.executor.cores 1
3. workers
- 重命名文件
mv workers.template workers
- 修改配置
在伪分布模式下,只需要将原有的localhost改为当前主机名即可。
4. SSH免密登录
在使用Hadoop集群时,建议使用主机名称,这样即使ip地址发生变化,也不需要去修改相关的配置文件,只需要去修改一下主机名映射文件就可以了。上文的配置文件中都使用了hadoop作为主机名,以此为例进行演示。
- Ubuntu修改主机名
在root用户下修改主机名设置文件:
sudo hostnamectl set-hostname hadoop

此时已经修改成功,打开一个新的回话和终端时将看到变化。
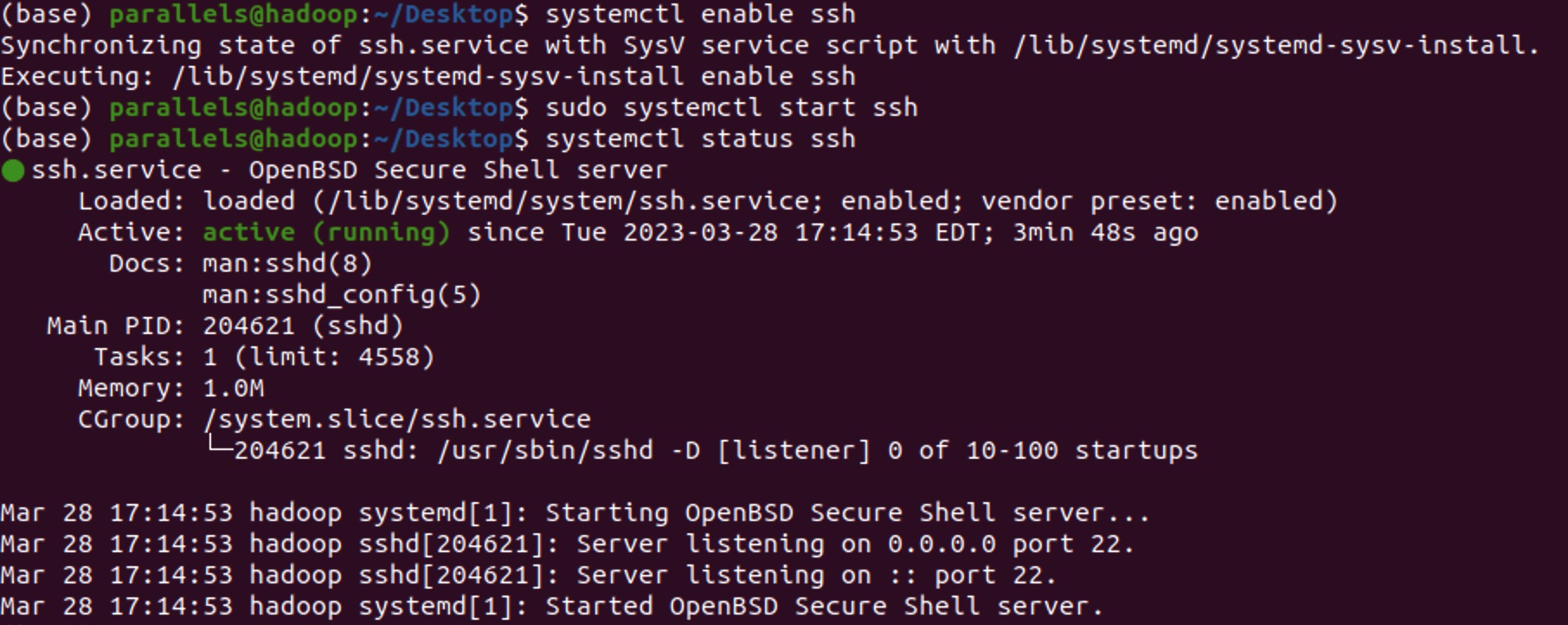
- 开启SSH服务
首先确认SSH服务状态:
systemctl status ssh
如果没有安装使用以下命令:
apt-get install openssh-server
启动SSH服务:
sudo systemctl enable ssh
sudo systemctl start ssh
systemctl status ssh
- 生成密钥
# 切换到hadoop用户下执行
su - hadoop
# 整个过程一直回车即可
ssh-keygen -t rsa
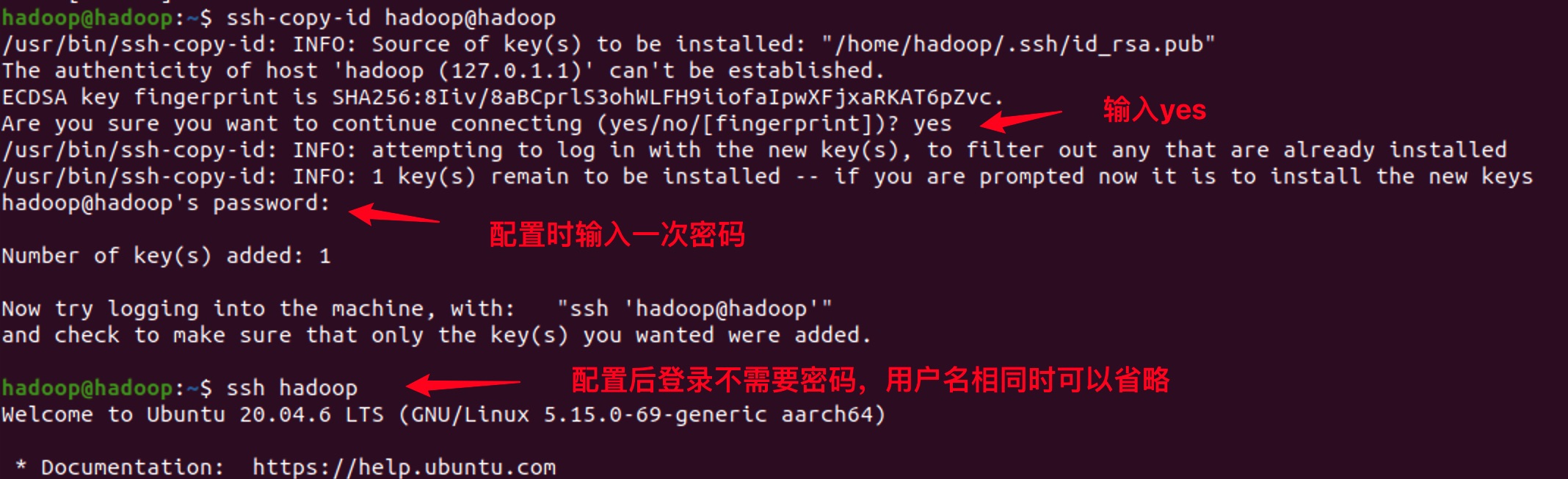
- 配置免密登录
Hadoop启动时,会逐一登录到worker节点去启动相应的进程,对于伪分布模式来说,相当于自己登录自己。配置免密登录后,不再需要密码,而是通过密钥进行认证。
ssh-copy-id hadoop@hadoop
ssh hadoop
5. 集群启动
现在所有的配置已经完成,进入到Spark的sbin目录,启动集群。
cd $SPARK_HOME/sbin
./start-all.sh
# 使用jps验证
jps
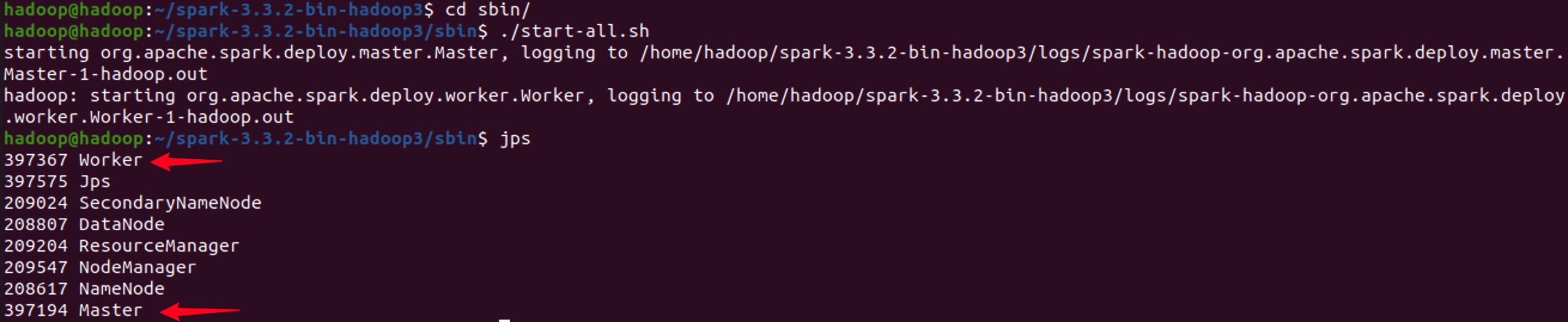
如果出现Master和Worker证明成功。
六、全分布模式
全分布模式的配置方式和步骤其实与伪分布式没有任何差别,在一台机器上配置好所有的配置文件后,分发到其它机器即可,核心步骤如下:
1. 前置环境
- 部署安装JDK【三台机器】
- 创建单独用户【三台机器】
- 解压安装Scala【主节点】
- 解压安装Spark【主节点】
- 配置环境变量【主节点】
2. 配置免密登录
假设我们有3台机器:hadoop01、hadoop02、hadoop03,每一台机器都执行如下操作:
# 在hadoop用户下执行
ssh-keygen -t rsa
ssh-copy-id hadoop@hadoop01
ssh-copy-id hadoop@hadoop02
ssh-copy-id hadoop@hadoop03
这样执行完成后,三台机器都可以免密互相登录,这样以后我们可以在任意一台机器上控制集群状态或者提交任务。
3. 文件分发
现在我们将已经安装好的软件和配置分发到另外两台机器,保证三台机器的配置文件和环境是完全一致的,如果配置文件发生修改,也要记得手动同步覆盖。
scp -r /home/hadoop/scala-2.12.17 hadoop@hadoop02:/home/hadoop
scp -r /home/hadoop/scala-2.12.17 hadoop@hadoop03:/home/hadoop
scp -r /home/hadoop/spark-3.3.2-bin-hadoop3@hadoop02:/home/hadoop
scp -r /home/hadoop/spark-3.3.2-bin-hadoop3@hadoop03:/home/hadoop
scp -r /home/hadoop/.bashrc hadoop@hadoop02:/home/hadoop
scp -r /home/hadoop/.bashrc hadoop@hadoop03:/home/hadoop
由于我们已经配置了免密登录,整个过程不需要密码。
4. 集群启动
集群的启动和停止与伪分布模式相同,可以在任一节点上执行启动脚本:
cd $SPARK_HOME/sbin
./start-all.sh
如果在workers文件中填写了主节点,则在主节点中会出现Master和Worker进程,从节点上会出现Worker进程。
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~
