算法练习-哈希表
1 哈希表介绍
1.1 哈希表的由来
假设又100个学生,如何根据id快速查找学生信息?
方案一:将所有的学生都存在一个数组中,查找id时遍历数组,时间复杂度:O(n)
方案二:将数组中的数据进行排序,查找时使用二分查找,时间复杂度:O(logn)
方案三:将数组下标与id一一映射 , 时间复杂度:O(1)
private int maxId = 1000; // 假设最大id为1000
private Student[] s = new Student[maxId + 1];
public int insert(Student student) {
s[student.id] = student;
}
public Student find(int id) {
return s[id];
}
但是如果id的范围很大,还是进行一一映射,空间开销就特别的大
所以可以对id进行hash处理:id 对学生的数量取余,结果为存到数组的位置
但是会产生一个问题:可能会出现多个学生取余结果相同的问题,这种情况需要解决哈希冲突
1.2 哈希冲突的解决方法
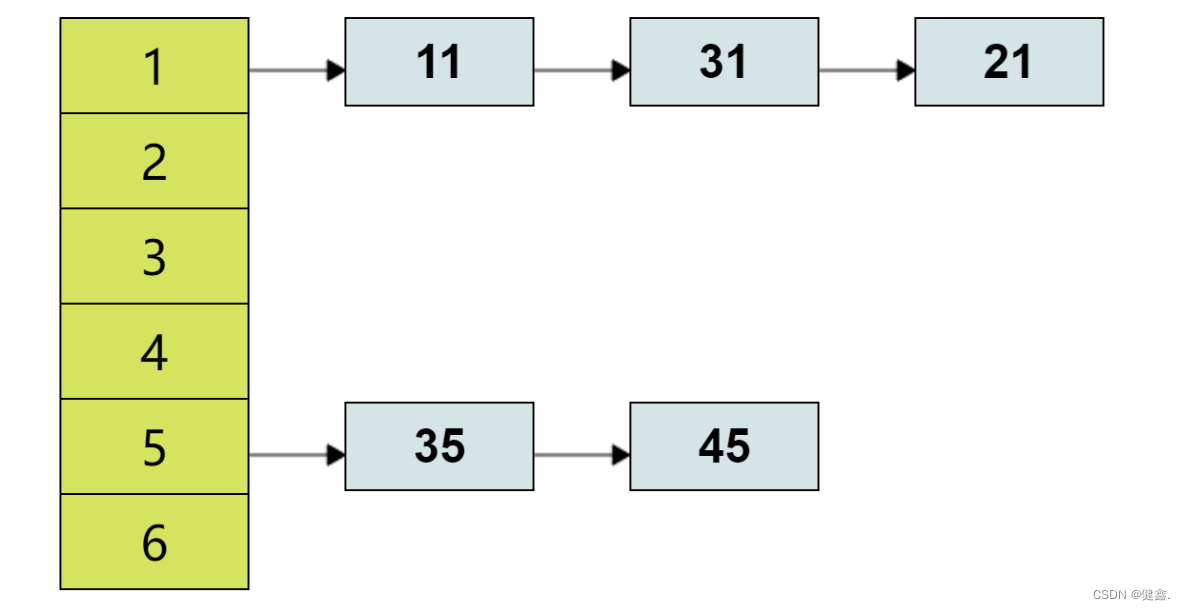
1.2.1 链表法
对于结果相同的数据,通过链表进行存储
1.2.1 开放寻址法
- 线性探测
产生冲突之后,依次查看其后的下一个位置,如果发现空位置插入新元素
- 二次探测
二次探测法在探测下一个槽位时,不是简单地加1,而是按照某个二次方程的规律计算下一个槽位的位置
next = (h + i^2) % table_size
i表示探测的次数,table_size表示哈希表的大小,%表示取余运算。二次探测法每次探测时,会根据当前探测的次数i计算下一个槽位的位置,如果该槽位已经被占用,则继续探测下一个槽位,直到找到一个空闲槽位为止。
- 双重哈希
在哈希表中使用了两个哈希函数,通过第一次哈希和第二次哈希的结果来寻找空闲槽位,解决哈希冲突
h1 = hash1(key)
h2 = hash2(key)
i = 0
while table[(h1 + i * h2) % table_size] is not None:
i += 1
next = (h1 + i * h2) % table_size
hash1和hash2是两个不同的哈希函数,table_size是哈希表的大小,i表示探测的次数。双重哈希首先使用hash1计算出关键字的哈希值h1,然后使用hash2计算出一个增量值h2。接着,双重哈希从h1开始探测槽位,每次探测跨越h2个槽位,直到找到一个空闲槽位为止。
1.3 动态扩容
不知道有多少数据会插入到哈希表的情况下,只能给哈希表预先设置一个起始大小
哈希表的性能会随着装入数据的个数而降低
当哈希表的性能下降到一定程度之后,就会触发扩容
判断性能下降到一定程度:装载因子 = 数据个数 / 槽的个数
对于开放寻址法解决哈希冲突:装载因子要小于1
对于链表发解决哈希冲突:装载因子可以大于1
1.3.1 动态扩容的实现
类似数组的扩容,申请一个更大的哈希表,将原哈希表中的数搬移到新的哈希表中
对于比较大的哈希表,重新计算哈希值和搬移比较耗时
1.3.2 避免集中扩容
为了解决扩容耗时过多的问题,可以将扩容操作穿插在多次插入操作的过程中,分批完成
也就是,新的哈希表创建之后,不立即插入数
每次插入新数据的时候,顺便将一个旧数据插入到新的哈希表中
2 例题
2.1 两数之和
链接:https://leetcode.cn/problems/two-sum
2.1.1 题目
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104
-109 <= nums[i] <= 109
-109 <= target <= 109
只会存在一个有效答案
2.1.2 题解
class Solution {
public int[] twoSum(int[] sums, int target) {
int n = sums.length;
// k为数字 v为下标
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < n ; i++) {
map.put(sums[i], i);
}
for (int i = 0; i < n; i++) {
if (map.containsKey(target - sums[i])) {
int value = map.get(target - sums[i]);
if (value != i) {
return new int[]{
i, value};
}
}
}
return new int[0];
}
}
2.2 三数之和
链接:https://leetcode.cn/problems/3sum
2.2.1 题目
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。
示例 2:
输入:nums = [0,1,1]
输出:[]
解释:唯一可能的三元组和不为 0 。
示例 3:
输入:nums = [0,0,0]
输出:[[0,0,0]]
解释:唯一可能的三元组和为 0 。
提示:
3 <= nums.length <= 3000
-105 <= nums[i] <= 105
2.2.2 题解
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> result = new ArrayList<>();
int n = nums.length;
HashMap<Integer, Integer> hashMap = new HashMap<>();
for (int i = 0; i < n; i++) {
hashMap.put(nums[i], i);
}
for (int i = 0; i < n; i++) {
if (i != 0 && nums[i] == nums[i - 1]) continue;
for (int j = i + 1; j < n; j++) {
if (j != i + 1 && nums[j] == nums[j - 1]) continue;
int target = -1 * (nums[i] + nums[j]);
if (!hashMap.containsKey(target)) continue;
int k = hashMap.get(target);
if (k > j) {
List<Integer> result0 = new ArrayList<>();
result0.add(nums[i]);
result0.add(nums[j]);
result0.add(nums[k]);
result.add(result0);
}
}
}
return result;
}
}
2.3 移除两个集合中的相同元素
2.3.1 题目
给定a1和a2两个数组,将a1中出现在a2中的数字去掉
2.3.2 题解
public int removeDup(int[] a1, int[] a2) {
HashSet<Integer> set = new HashSet<>();
int n1 = a1.length;
int n2 = a2.length;
for (int i = 0; i < n2; ++i) {
set.add(a2[i]);
}
int k = 0;
for (int i = 0; i < n1; i++) {
if (!set.contains(a1[i])) {
a1[k] = a1[i];
k++;
}
}
return k;
}
2.4 LRU缓存
链接:https://leetcode.cn/problems/lru-cache
2.4.1 题目
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
[“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 put
2.4.2题解
class LRUCache {
private class DLinkedNode {
public int key;
public int value;
public DLinkedNode prev;
public DLinkedNode next;
public DLinkedNode(int key, int value) {
this.key = key;
this.value = value;
}
}
private Map<Integer, DLinkedNode> hashtable = new HashMap<>();
private int size;
private int capacity;
private DLinkedNode head;
private DLinkedNode tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
this.head = new DLinkedNode(-1, -1);
this.tail = new DLinkedNode(-1, -1);
this.head.next = tail;
this.head.prev = null;
this.tail.prev = head;
this.tail.next = null;
}
public int get(int key) {
if (size == 0) return 0-1;
DLinkedNode node = hashtable.get(key);
if (node == null) return -1;
removeNode(node);
addNodeAtHead(node);
return node.value;
}
public void remove(int key) {
DLinkedNode node = hashtable.get(key);
if (node != null) {
removeNode(node);
hashtable.remove(key);
size--;
return;
}
}
public void removeNode(DLinkedNode node) {
node.next.prev = node.prev;
node.prev.next = node.next;
}
public void addNodeAtHead(DLinkedNode node) {
node.next = head.next;
head.next.prev = node;
head.next = node;
node.prev = head;
}
public void put(int key, int value) {
DLinkedNode node = hashtable.get(key);
if (node != null) {
node.value = value;
removeNode(node);
addNodeAtHead(node);
return;
}
if (size == capacity) {
hashtable.remove(tail.prev.key);
removeNode(tail.prev);
size--;
}
DLinkedNode newNode = new DLinkedNode(key, value);
addNodeAtHead(newNode);
hashtable.put(key, newNode);
size++;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/