一、引入
我们在训练模型的过程中,需要用未知的数据集(为被训练过的)送入训练好的模型进行验证,来检测该模型是否适用于该项目。哪该如何来进行判断呢?这个就需要评价指标了。模型的评价指标有很多,比如:精确率(查准率)、F1-Score、召回率(查全率)、准确率、P-R曲线、ROC曲线等。我们这里就主要介绍精确率(查准率)、F1-Score、召回率(查全率)、准确率。
二、评价指标介绍
不同的分类指标有不同的含义,比如在商品推荐系统中,希望更精准的了解客户需求,避免推送用户不感兴趣的内容,精确率就更加重要;在疾病检测的时候,不希望查漏任何一项疾病,这时查全率就更重要。当两者都需要考虑时,F1-Score就是一种参考指标。
注意:评价模型过程中,需要不同的评价指标从不同角度对模型进行全面的评价,在诸多的评价指标中,大部分指标只能片面的反应模型的一部分性能,如果不能合理的运用评估指标,不仅不能发现模型本身的问题,而且会得出错误的结论。
精确率(查准率)、F1-Score、召回率(查全率)、准确率 是我们在分类模型中用到的最多的四个评价指标,不同的评价指标有不同的计算公式。
accuracy = 预测正确的/预测的总数
哪在这些公式里面的TP、TN、FP、FN是什么意思呢?哪请看下面的内容:
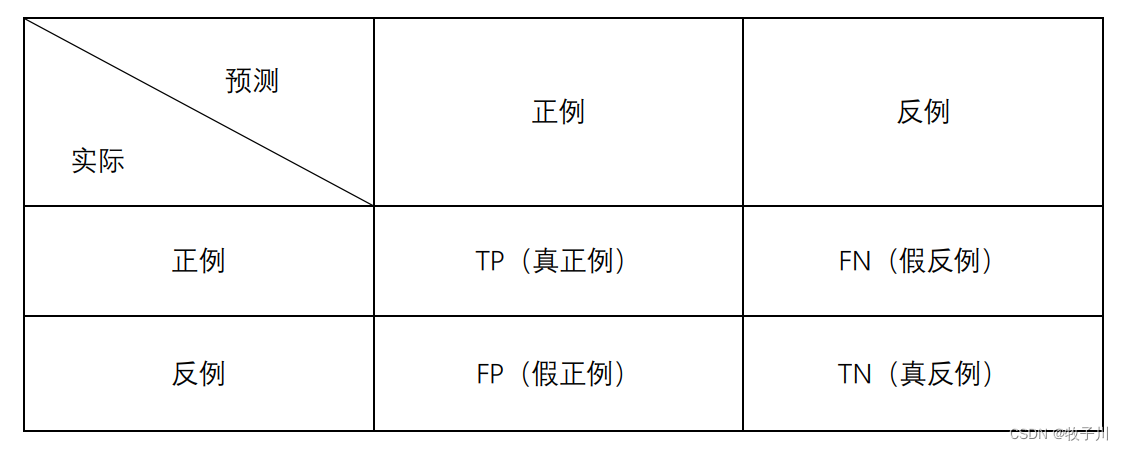 真正例(True Positive,TP):表示实际为正被预测为正的样本数量
真正例(True Positive,TP):表示实际为正被预测为正的样本数量
真反例(True Negative,TN):表示实际为负被预测为负的样本的数量
假正例(False Positive,FP):表示实际为负但被预测为正的样本的数量
假反例(False Negative,FN):表示实际为正但被预测为负的样本数量
三、二分类
什么是二分类?二分类就是我们的预测结果就只有两类,并且这两类是可以用数值来表示的。
假设我们现在有关需求,要来正确判断出猫和狗这两类,于是我们训练的一个模型,现在需要来评判该模型能否在实际中正常使用,于是我们把未知数据集 [猫,猫,狗,狗,猫] 送入模型得到预测结果为 [猫,狗,狗,猫,猫]。
y_true = [猫,猫,狗,狗,猫]
y_pred = [猫,狗,狗,猫,猫]
TP = 1
TN = 2
FP = 1
FN = 1
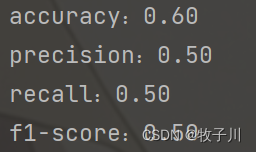
accuracy = 3/5 = 0.6
precision = 2/(2+1) = 05
recall = 2/(1+1) = 0.5
F1 = (2*0.5*0.5)/(0.5+0.5) = 0.5
from sklearn.metrics import recall_score, f1_score, precision_score, accuracy_score
# [猫,猫,狗,狗,猫]
y_true = [0, 0, 1, 1, 0]
# [猫,狗,狗,猫,猫]
y_pred = [0, 1, 1, 0, 0]
print("accuracy:%.2f" % accuracy_score(y_true, y_pred))
print("precision:%.2f" % precision_score(y_true, y_pred))
print("recall:%.2f" % recall_score(y_true, y_pred))
print("f1-score:%.2f" % f1_score(y_true, y_pred))
四、多分类
多分类就是模型的预测结果不止有两类,有多类,比如说,三类,四类等。那么这时我们该如何求指标呢?
假设现在有三类,真实值为 [猫,狗,狗,鼠,猫,鼠],预测值为 [鼠,猫,狗,猫,猫,鼠]。
我们可以将其看成 3(3类) 个二分类。
第一个:[猫,other]
y_true = [猫,other,other,other,猫,other]
y_pred = [other,猫,other,猫,猫,other]
TP = 1 TN = 2 FP = 2 FN = 1
precision = 1/3 = 0.33
recall = 1/2 = 0.5
F1 = (2 * precision * recall )/(precision + recall ) = 0.40
第二个:[狗,other]
y_true = [other,狗,狗,other,other,other]
y_pred = [other,other,狗,other,other,other]
TP = 1 TN = 4 FP = 0 FN = 1
precision = 1/1 = 1
recall = 1/2 = 0.5
F1 = (2 * precision * recall )/(precision + recall ) = 0.67
第三个:[鼠,other]
y_true = [other,other,other,鼠,other,鼠]
y_pred = [鼠,other,other,other,other,鼠]
TP = 1 TN = 3 FP = 1 FN = 1
precision = 1/2 = 0.5
recall = 1/2 = 0.5
F1 = (2 * precision * recall )/(precision + recall ) = 0.5
将上面三类进行求平均:
accuracy = 3/6 = 0.5
precision = (0.33+1+0.5)/3 = 0.61
recall = (0.5+0.5+0.5)/3 = 0.5
F1 = (0.4+0.67+0.5)/3 = 0.52
from sklearn.metrics import recall_score, f1_score, precision_score, accuracy_score
from sklearn.metrics import classification_report
# [猫,狗,狗,鼠,猫,鼠]
y_true = [0, 1, 1, 2, 0, 2]
# [鼠,猫,狗,猫,猫,鼠]
y_pred = [2, 0, 1, 0, 0, 2]
measure_result = classification_report(y_true, y_pred)
print('measure_result = \n', measure_result)
print("accuracy:%.2f" % accuracy_score(y_true, y_pred))
print("precision:%.2f" % precision_score(y_true, y_pred, labels=[0, 1, 2], average='macro'))
print("recall:%.2f" % recall_score(y_true, y_pred, labels=[0, 1, 2], average='macro'))
print("f1-score:%.2f" % f1_score(y_true, y_pred, labels=[0, 1, 2], average='macro'))
