摘要:
目前只实现了基2的算法,当数据长度不是2的n次方时,我用截断和补零两种实现方式,补零的操作起码在频谱上没看出太大的差异,但直接截断的操作相当于加了矩形窗,所以对最终频谱的代码存在异常;
基2的推导:
【这里有图】【等我把笔记本从公司拿回来拍个照再上传(上班时间推得)】
蝶形运算的过程:
这里给出第一列排序的推导,如果想不明白为什么这样做,不妨试试将这个图上的结果倒着看,是不是就豁然开朗,守得云开见月明了~~

这个图网上搜一下蝶形运算一大堆,我放上这么丑的图,完全是为了自己以后看的时候能记得!图上还有圈出来一大堆东西是写代码实现的时候分析的~
代码实现:
数据构造:
import numpy as np
import matplotlib.pyplot as plt
import os
import math
import scipy.signal as sig
def cac_db(data):
return 20*np.log10(abs(data))
# 构造数据
noise_data = np.random.uniform(low=-1,high=1,size=8192) + np.random.uniform(low=-1,high=1,size=8192) * 1j
flt_coef = sig.remez(150,[0,50,100,491.52],[1,0],fs=983.04)
data_org = np.convolve(noise_data,flt_coef)
plt.psd(data_org,NFFT=1024,Fs=491.52)
# 参考结果
# data_fft = np.fft.fft(data[:8192],)
# data_fft = np.roll(data_fft,len(data_fft)//2)
# plt.plot(cac_db(data_fft),'*-')
# plt.grid(True)
实现DFT的结果,从这个计算时间上可以看出来,DFT是多么的费时~
# 手写DFT
def Fun_DFT(data):
data = np.array(data)
data_len = data.shape[0]
data_fft = np.zeros_like(data)
# 循环的公共部分
W_n = -1j * 2 * np.pi / data_len * np.arange(data_len)
for n in range(data_len):
print('=====正在第{:}个点的DFT结果====='.format(n))
data_fft_temp = data * np.exp(W_n)**n
data_fft_i = np.sum(data_fft_temp)
data_fft[n] = data_fft_i
return data_fft
data_dft = Fun_DFT(data_org)
data_dft = np.roll(data_dft,len(data_dft)//2)
plt.plot(cac_db(data_dft),'*-')
plt.grid(True)
实现基2的FFT,这个运算时间比DFT少的不是一点点~
# 手写FFT
# 第一层数据重组
def Fun_fft_datareshape(data,base=2):
data = np.array(data)
data_len = data.shape[0]
# 一开始就重组数据,这样之后就可以不用重组数据;原则:一直对半,直到最小半个长度为base
data_reshape = np.zeros_like(data)
data_reshape_temp = data.copy()
current_half_len = data_len
while current_half_len > base:
cur_blk_start_index = 0
next_blk_len = current_half_len // 2
next_blk_start_index = -next_blk_len
# end_index = int(current_half_len//2)
while cur_blk_start_index < data_len:
cur_blk_end_index = cur_blk_start_index + current_half_len
# while next_blk_start_index < current_half_len:
next_blk_start_index += next_blk_len
next_blk_end_index = next_blk_start_index + next_blk_len
data_reshape[next_blk_start_index:next_blk_end_index] \
= data_reshape_temp[cur_blk_start_index:cur_blk_end_index:2]
next_blk_start_index += next_blk_len
next_blk_end_index = next_blk_start_index + next_blk_len
data_reshape[next_blk_start_index:next_blk_end_index] \
= data_reshape_temp[cur_blk_start_index + 1:cur_blk_end_index:2]
cur_blk_start_index += current_half_len
data_reshape_temp = data_reshape.copy()
current_half_len = int(current_half_len // 2)
return data_reshape
# data_reshape_test = np.arange(16)
# a = Fun_fft_datareshape(data_reshape_test)
def Fun_FFT(data, Fun_pad_method, base=2, ):
data = np.array(data)
# todo:需要考虑数据长度不是base的整数倍
data = Fun_pad_method(data, base)
fft_deep = int(math.log(len(data), base)) # 蝶形计算层数
# 对第一级数据进行重组
data_reshape = Fun_fft_datareshape(data, base)
data_len = data.shape[0]
# 记录每一层的结果
data_fft_temp = np.zeros([data_len, fft_deep+1],'complex')
data_fft_temp[:,0] = data_reshape
for deep_i in range(1,fft_deep+1): # 从1开始的原因是:第一层的结果已经给出
distance = 2**(deep_i-1) # 当前层蝶形计算两个点的间距
# 初始化w:每个blk的w取值是一样,所以在此初始化
temp = np.arange(distance)
W_N = np.exp(-1j * 2 * np.pi / 2 ** deep_i * temp)
butterfly_blk_start_index = 0 # 初始化blk循环
# 循环blk
while butterfly_blk_start_index < data_len: # 判断当前blk的起始索引是否是最后一个索引,blk的起始索引超限就说明blk的循环完成
# blk内节点循环:每次完成连续几个值的循环
for i in range(distance): # 间距是几 就连续取几个值
# 蝶形运算
butterfly_data0_index = butterfly_blk_start_index + i
butterfly_data1_index = butterfly_data0_index + distance # 下一层的deep索引正好是蝶形运算两点的间距
butterfly_data0 = data_fft_temp[butterfly_data0_index,deep_i-1] # 取蝶形计算的两个节点
butterfly_data1 = data_fft_temp[butterfly_data1_index,deep_i-1]
# todo:w_i的值需要提前存储
w_i = W_N[i] # 取当前蝶形计算的w值
data_fft_temp[butterfly_data0_index,deep_i] = butterfly_data0 + w_i * butterfly_data1 # 蝶形计算
data_fft_temp[butterfly_data1_index,deep_i] = butterfly_data0 - w_i * butterfly_data1
butterfly_blk_start_index = butterfly_data1_index + 1 # 下一个blk的起始索引等于当前blk的截止索引+1
data_fft = data_fft_temp[:,-1]
return data_fft
# data_fft_hands = Fun_FFT(data)
# data_fft_hands = np.roll(data_fft_hands,len(data_fft_hands)//2)
# plt.plot(cac_db(data_fft_hands),'*-')
# plt.grid(True)
对非2的n次方的处理
# todo:非2的整数倍时FFT怎么处理
# 方法1:补零,会出现断点,所以理论上需要加窗
def Fun_pad_method(data, base=2):
data = np.array(data)
data_len_org = data.shape[0]
deep_num = np.ceil(math.log(data_len_org, base)).astype('int')
data_pad = np.zeros(base**deep_num, 'complex')
data_pad[:data_len_org] = data
return data_pad
主函数:
if __name__ == "__main__":
# data = data_org[:8192]
data = data_org
plt.figure()
# 参考结果
data_fft = np.fft.fft(data, )
data_fs = np.fft.fftfreq(len(data), 983.04)
data_fft = np.roll(data_fft, len(data_fft) // 2)
data_fs = np.roll(data_fs, len(data_fs) // 2)
plt.plot(data_fs, cac_db(data_fft), '*-')
plt.grid(True)
# DFT
data_dft = Fun_DFT(data)
data_dft = np.roll(data_dft, len(data_dft) // 2)
plt.plot(data_fs, cac_db(data_dft), '*-')
plt.grid(True)
# FFT
data_fft_hands = Fun_FFT(data,Fun_pad_method,base=2)
data_fs = np.fft.fftfreq(len(data_fft_hands), 983.04)
data_fft_hands = np.roll(data_fft_hands, len(data_fft_hands) // 2)
data_fs = np.roll(data_fs, len(data_fs) // 2)
plt.plot(data_fs, cac_db(data_fft_hands), '*-')
# plt.plot(cac_db(data_fft_hands), '*-')
plt.grid(True)
plt.legend(['org', 'DFT_hands', 'FFT_hands'])
结果:
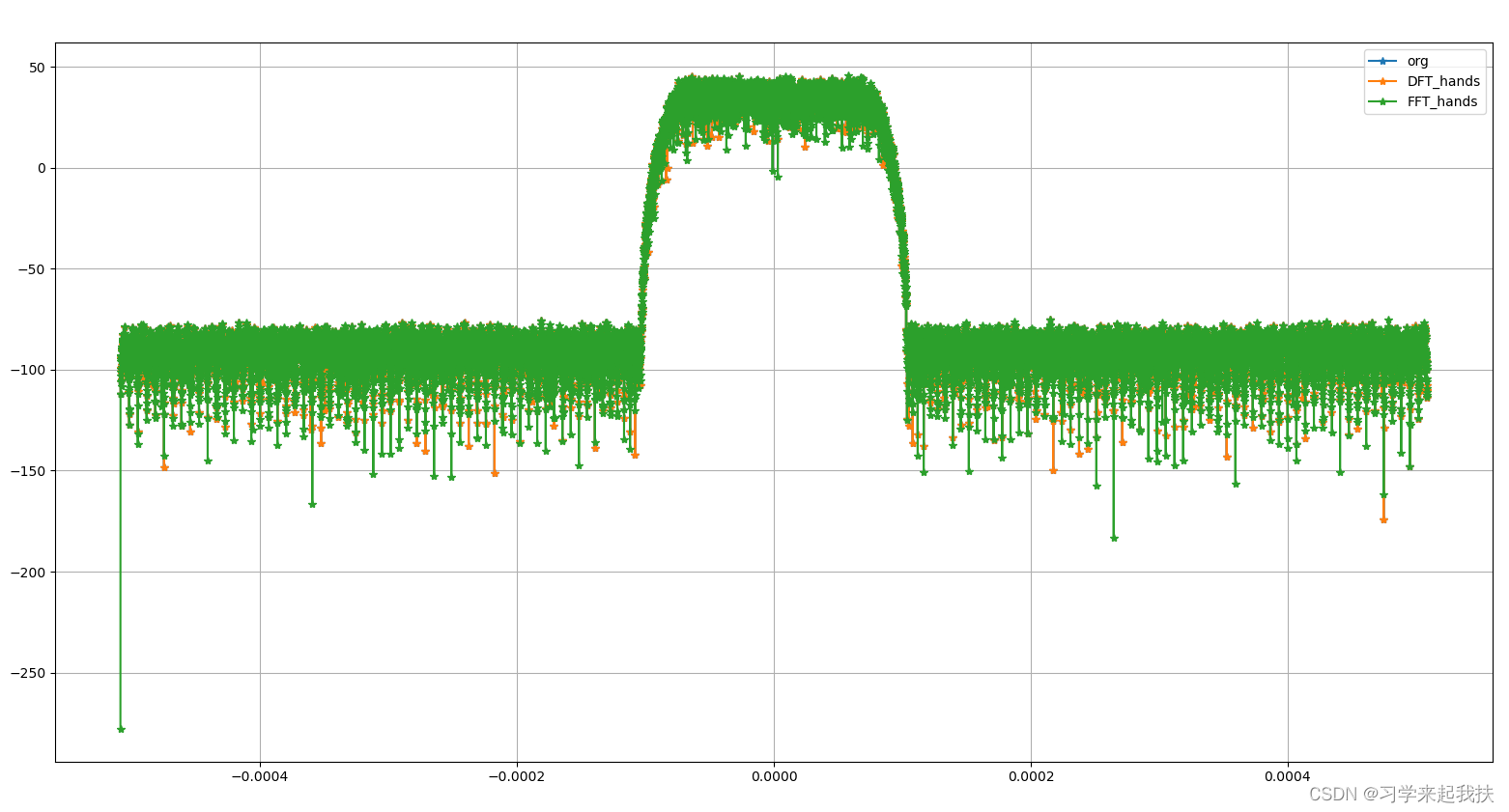
非2**n长度数据的fft推导实现
【正在推导,目前推导和别的结果不一致,问题排查中~】
后续计划:
todo:直接拿原始8314长度数据画出来的频谱和截取8192画出来的差距为什么这么大??
todo:从实现的角度对fft_hand进行优化,比如旋转因子W的实现???