一、与梯度的关系:
如:y=x**2
Y.backward()
X.grad==d(y)/d(x),则说明x的梯度是反向传播函数关于x的导数,即哪个函数backward,用哪个函数进行求导。
二、与损失函数的关系:
参考资料:https://www.jianshu.com/p/964345dddb70
反向传播旨在优化权重参数,从而得到最优的全局参数矩阵,进而将多层神经网络应用到分类(前向传播)或者回归任务(权重或参数求取)中去,主要应用在包含隐藏层的情况。反向传播工作原理,当输出值与真实值不一致时,损失函数会提出一个变量的修改方向与多少,由于隐藏层的存在,无法直接根据损失函数进行输入在隐藏层中权重矩阵或参数的修改,使用反响传播可以使隐藏层间接获得修改指示。具体传播过程如下所示:
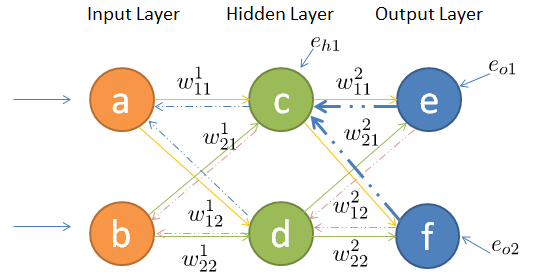

接着对输入层的w11进行参数更新,更新之前我们依然从后往前推导,直到预见第一层的w11为止(只不过这次需要往前推的更久一些):
因此误差对输入层的w11求偏导如下:
求导得如下公式(有点长(ฅ́˘ฅ̀)):
同理,输入层的其他三个参数按照同样的方法即可求出各自的偏导,在这不再赘述。在每个参数偏导数明确的情况下,带入梯度下降公式即可(不在重点介绍):
至此,需要更新的权重已经获得,其实就是原始权重加上损失函数对某一权重的偏导数乘以学习率。
Y.backward()==d
详情参考:https://gitee.com/ski133/PytorchTest/blob/master/PyTorchTest/%E4%BA%A4%E5%8F%89%E7%86%B5%E6%8D%9F%E5%A4%B1%E5%87%BD%E6%95%B0.docx