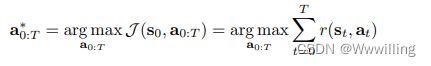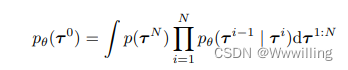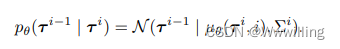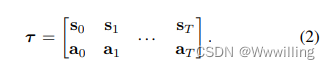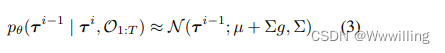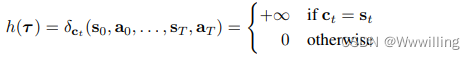考虑一个由离散时间动态 s t + 1 = f ( s t , a t ) s_{t+1} = f(s_t, a_t) st+1=f(st,at) 控制的系统,在状态 s t s_t st 给定一个动作 a t a_t at。 轨迹优化指的是找到一系列动作 a 0 : T ∗ a^*_{0:T} a0:T∗ 最大化(或最小化)目标 J J J 分解为每个时间步长的奖励(或成本) r ( s t , a t ) r(s_t, a_t) r(st,at):
其中 T T T 是规划范围。 我们使用缩写 τ = ( s 0 , a 0 , s 1 , a 1 , . . , s T , a T ) τ = (s_0, a_0, s_1, a_1, . . , s_T , a_T ) τ=(s0,a0,s1,a1,..,sT,aT) 来指代交错状态和动作的轨迹,并使用 J ( τ ) J (τ ) J(τ) 来表示该轨迹的目标值。
扩散概率模型
扩散概率模型(Sohl-Dickstein 等人,2015 年;Ho 等人,2020 年)将数据生成过程视为迭代去噪过程 p θ ( τ i − 1 ∣ τ i ) p_θ(τ^{i−1}|τ^i) pθ(τi−1∣τi)。 这种去噪是前向扩散过程 q ( τ i ∣ τ i − 1 ) q(τ^i| τ^{i−1}) q(τi∣τi−1) 的逆过程,前向扩散过程 q ( τ i ∣ τ i − 1 ) q(τ^i| τ^{i−1}) q(τi∣τi−1) 通过添加噪声慢慢破坏数据中的结构。模型引起的数据分布由下式给出:
其中 p ( τ N ) p(τ^N ) p(τN) 是标准高斯先验, τ 0 τ^0 τ0 表示(无噪声)数据。 通过最小化反向过程的负对数似然的变分界限来优化参数 θ θ θ: θ ∗ = a r g m i n θ − E τ 0 [ l o g p θ ( τ 0 ) ] θ^∗ = arg min_θ −E_{τ^0}[logp_θ(τ^0)] θ∗=argminθ−Eτ0[logpθ(τ0)]。 逆向过程通常被参数化为具有固定时间步长相关协方差的高斯分布:
正向过程 q ( τ i ∣ τ i − 1 ) q(τ^i| τ^{i−1}) q(τi∣τi−1) 通常是预先指定的。
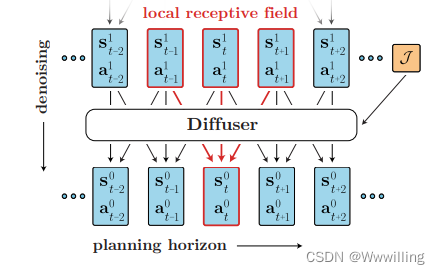
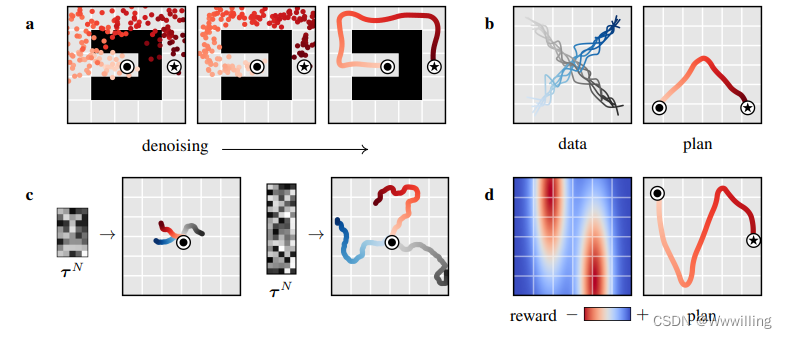
符号。 在这项工作中有两个“时间”在起作用:扩散过程的时间和规划问题的时间。 我们使用上标(未指定时为 i i i)表示扩散时间步长,使用下标(未指定时为 t t t)表示规划时间步长。 例如, s t 0 s^0_t st0 指的是无噪声轨迹中的第 t t t 个状态。 当上下文明确时,省略无噪声量的上标: τ = τ 0 τ = τ^0 τ=τ0。 我们通过将轨迹 τ τ τ 中的第 t t t 个状态(或动作)称为 τ s t τ_{s_t} τst(或 τ a t τ_{a_t} τat)来稍微重载符号。
扩散规划
使用轨迹优化技术的一个主要障碍是它们需要了解环境动力学 f f f。 大多数基于学习的方法都试图通过训练近似动力学模型并将其插入常规规划程序来克服这一障碍。 然而,学习模型通常不太适合设计时考虑到真实模型的规划算法类型,导致规划者通过寻找对抗性示例来利用学习模型。
在一般的强化学习环境中,为了编写动态规划递归的目的,对未来的条件化源于对未来最优性的假设。 具体而言,这表现为行动分布 l o g p ( a t ∣ s t , O t : T ) logp(a_t | s_t, O_{t:T}) logp(at∣st,Ot:T) 中的未来最优变量 O t : T O_{t:T} Ot:T (Levine, 2018)。
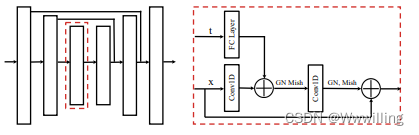
训练。 我们使用 Diffuser 参数化轨迹去噪过程的学习梯度 ε θ ( τ i , i ) \varepsilon_θ(τ^i, i) εθ(τi,i),从中可以以封闭形式求解平均 μ θ μ_θ μθ (Ho et al., 2020)。 我们使用简化的目标来训练 ε \varepsilon ε-模型,由下式给出:
其中 i ∼ U { 1 , 2 , . . . , N } i ∼ U\{1, 2, . . . , N\} i∼U{
1,2,...,N} 是扩散时间步长, ε ∼ N ( 0 , I ) \varepsilon ∼ N (0, I) ε∼N(0,I) 是噪声目标, τ i τ^i τi 是被噪声 ε \varepsilon ε 破坏的轨迹 τ 0 τ^0 τ0。 逆过程协方差 Σ i Σ^i Σi 遵循 Nichol & Dhariwal (2021) 的余弦时间表。
强化学习作为引导抽样
为了用 Diffuser 解决强化学习问题,我们必须引入奖励的概念。 我们呼吁控制作为推理图形模型(Levine,2018)这样做。 令 O t O_t Ot 为二元随机变量,表示轨迹的时间步长 t t t 的最优性,其中 p ( O t = 1 ) = e x p ( r ( s t , a t ) ) p(O_t = 1) = exp(r(s_t, a_t)) p(Ot=1)=exp(r(st,at))。 我们可以通过在等式 1 中设置 h ( τ ) = p ( O 1 : T ∣ τ ) h(τ ) = p(O_{1:T} | τ ) h(τ)=p(O1:T∣τ) 从一组最优轨迹中采样:
我们已经将强化学习问题换成了条件抽样之一。 值得庆幸的是,之前已经有很多关于使用扩散模型进行条件抽样的工作。 虽然很难从该分布中精确采样,但当 p ( O 1 : T ∣ τ i ) p(O_{1:T} | τ^i ) p(O1:T∣τi) 足够平滑时,反向扩散过程转换可以近似为高斯分布(Sohl-Dickstein 等人,2015 年):
其中 µ , Σ µ, Σ µ,Σ 是原始逆过程转换的参数 p θ ( τ i − 1 ∣ τ i ) p_θ(τ^{i−1}| τ^i) pθ(τi−1∣τi) 和