写在前面
在前面一篇文章:【GAN】一、利用keras实现DCGAN生成手写数字图像中我们利用keras实现了简单的DCGAN,并生成了手写数字图像。程序结果让我们领略了GAN的强大,接下来我们开始一步一步地介绍各种GAN模型。那么我们首先从最基础的GAN开始说起。
一、GAN简介
GAN(Generative Adversarial Network)全名叫做对抗生成网络或者生成对抗网络。GAN这一概念是由Ian Goodfellow于2014年提出,并迅速成为了非常火热的研究话题。目前,GAN的变种更是有上千种,2019年计算机界的诺贝尔奖“图灵奖”得主,深度学习先驱之一的Yann LeCun也曾说:“GAN及其变种是数十年来机器学习领域最有趣的想法。”
原始GAN的论文连接为:Generative Adversarial Nets
首先我们用一句话来概括下原始GAN。原始GAN由两个有机中整体构成——生成器 G G G和判别器 D D D,生成器的目的就是将随机输入的高斯噪声映射成图像(“假图”),判别器则是判断输入图像是否来自生成器的概率,即判断输入图像是否为假图的概率。
GAN的训练也与CNN大不相同,CNN是定义好特定的损失函数,然后利用梯度下降及其改进算法进行优化参数,尽可能用局部最优解去逼近全局最优解。但是GAN的训练是个动态的过程,是生成器 G G G与判别器 D D D两者之间的相互博弈过程。通俗点讲,GAN的目的就是无中生有,以假乱真。即要使得生成器 G G G生成的所谓的"假图"骗过判别器 D D D,那么最优状态就是生成器 G G G生成的所谓的"假图"在判别器 D D D的判别结果为0.5,不知道到底是真图还是假图。
接下来我们要对GAN中相关术语进行解释。首先给出解释的是生成器 G G G。生成器 G G G用于捕获输入高斯噪声的数据分布,产生"假图"。接下来即使的是判别器。判别器 D D D则是评估输入样本是来自训练集而非生成器的概率。训练生成器 G G G是为了最大化判别器 D D D犯错的概率。原始GAN整个框架是生成器 G G G与判别器 D D D两者之间的相互博弈的动态过程。
二、GAN训练
接下来我们来介绍GAN的训练。首先我们给出原始GAN的目标函数(损失函数),损失函数表入下所示:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p d a t a ( z ) [ log ( 1 − D ( G ( z ) ) ) ] (1) \underset{G}{\mathop{\min }}\,\underset{D}{\mathop{\max }}\,V(D,G)={
{\mathbb{E}}_{x\sim {
{p}_{data}}(x)}}[\log D(x)]+{
{\mathbb{E}}_{z\sim {
{p}_{data}}(z)}}[\log (1-D(G(z)))]\tag1 GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pdata(z)[log(1−D(G(z)))](1)
其中, G G G代表生成器, D D D代表判别器, x x x代表真实数据, p d a t a p_{data} pdata代表真实数据概率密度分布, z z z代表了随机输入数据,该数据是随机高斯噪声。
从上式可以看出,从判别器 D D D角度来看判别器 D D D希望能尽可能区分真实样本 x x x和虚假样本 G ( z ) G(z) G(z),因此 D ( x ) D(x) D(x)必须尽可能大, D ( G ( z ) ) D(G(z)) D(G(z))尽可能小, 也就是 V ( D , G ) V(D,G) V(D,G)整体尽可能大。从生成器 G G G的角度来看,生成器 G G G希望自己生成的虚假数据 G ( z ) G(z) G(z)可以尽可能骗过判别器 D D D,也就是希望 D ( G ( z ) ) D(G(z)) D(G(z))尽可能大,也就是 V ( D , G ) V(D,G) V(D,G)整体尽可能小。GAN的两个模块在训练相互对抗,最后达到全局最优。
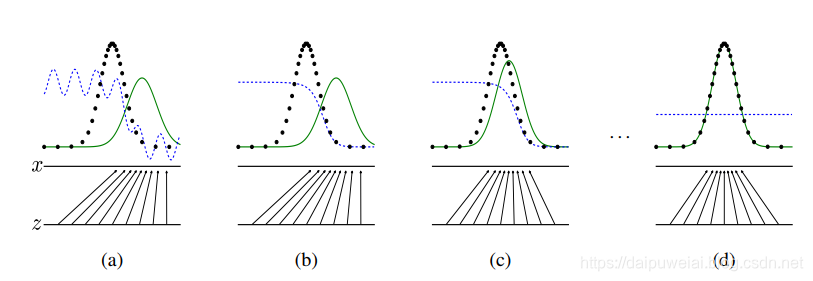
下面原始论文也给出了GAN的训练过程示意图。在上图中,平行线代表噪声 z z z,它映射到了 x x x,蓝色点线代表判别器 D D D的输出,黑色圆点代表真实数据分布 p d a t a p_{data} pdata,绿色实线代表生成器 G G G的虚假数据的概率分布 p g p_g pg。可以从下面图看出,在GAN的训练过程中,生成器 G G G的概率密度分布慢慢的逼近真实数据集的概率密度分布,而判别器预测值也在不断下降,当出现下图(d)的情况时, D ( G ( z ) ) = 0.5 D(G(z))=0.5 D(G(z))=0.5,即分不清输入图像到底是真实图像还是生成器伪造的假图。
接下来,我们给出GAN训练的算法,如下图所示。从下图训练算法可以看出,首先利用上述目标函数结合梯度上升训练K次判别器,之后结合梯度下降去训练1次器。

在论文中,作者也给出了GAN相关结论数学证明 ,CSDN上已经有大神给出相关详细推导过程,在此我就不给出相关证明了,若有兴趣请移步:GAN论文阅读——原始GAN(基本概念及理论推导)。不过我在此也对相关接结论进行一个归纳:
- 生成器概率密度分布 p g p_g pg与真实数据分布 p d a t a p_{data} pdata相等时,GAN的目标函数取得全局最优解。
- 最优判别器 D D D的表达式为: D G ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p G ( x ) D_{G}^{*}(x)=\frac{ { {p}_{data}}(x)}{ { {p}_{data}}(x)+{ {p}_{G}}(x)} DG∗(x)=pdata(x)+pG(x)pdata(x),那么GAN取得最优时 p g = p d a t a p_g = p_{data} pg=pdata,,那么 D G ∗ ( x ) = 0.5 D_{G}^{*}(x)=0.5 DG∗(x)=0.5
- 综合1,2两点,虽然在实际训练GAN中,我们最终不能使得 p g = p d a t a p_g = p_{data} pg=pdata,但是我们v必须尽可能去逼近这个结果,这样才能使得生成的“假图”能够以假乱真。
三、 实验结果
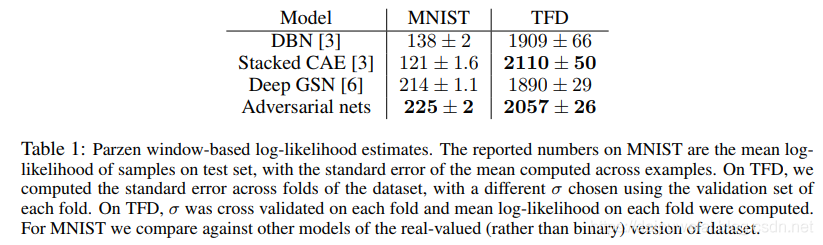
下面给出原始GAN实验结果。首先给出在MNIST数据集和TFD上对数极大似然估计,实验结果如下如所示。
接下来是是实验结果可视化,分别在mnist数据集、TFD数据集和CIFAR-10数据集进行训练,然后生成中间训练结果,如下图所示。其中图a是mnist数据集的训练结果,图b是TFD数据集的训练结果,图c是利用全连接网络的GAN在CIFAR-10数据集上的训练结果,图d是利用卷积和反卷积的GAN在CIFAR-10数据集上的训练结果。

后记
至此GAN系列第二篇——原始GAN论文详解到此结束,在下一篇博客我们将详细介绍DCGAN的。