背景:
一、 先谈 ASCII码
// java 代码打印字符的ASCII码值
public static void main(String[] args) {
int A='A';
int B='B';
int a='a';
int b='b';
int temp=',';
System.out.println(A);//65
System.out.println(B);//66
System.out.println(a);//97
System.out.println(b);//98
System.out.println(temp);//44
}二、 GBK 和UTF-8
随着计算机的普及,像中国等一些使用象形文字的国家加入,这个时候一个字节根本不可能满足了,因为2的8次方等于256 ,而汉字的总数已经超过了8万,常用的也有3500字左右,所以256 根本不够了,于是就发明了GB2312[加强版GBK]这些汉字编码,典型的用2个字节来表示绝大部分的常用汉字,最多可以表示256*256=65536个汉字字符,但是世界那么多种文字呢,这只是解决了每个国家自己的编码问题,各用各的字符集编码并不能通用,所以字符集Unicode横空出世了,将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码 比如 中国 对应的Unicode为 \u4e2d\u56fd
然而,Unicode虽然统一了全世界字符的二进制编码,但没有规定如何存储啊,Unicode 就相当于一张表,建立了字符与编号之间的联系,它是一种规定,Unicode 本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
utf-8就是Unicode最重要的实现方式之一。另外还有utf-16、utf-32等。UTF-8不是固定字长编码的,而是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。这是种比较巧妙的设计,如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode符号范围 (十六进制) | UTF-8编码方式(二进制) |
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
注意Unicode的字符编码和utf-8的存储编码表示是不同的,例如"严"字的Unicode码是4E25(100111000100101),UTF-8编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5,所以需要我们的计算机程序进行转换。
| 一个字符占多少字节 | UTF-8 | GBK | GB2312 | UTF-16 |
| 中文 | 3 | 2 | 2 | 4 |
| 英文 | 1 | 1 | 1 | 4 |
小结:
Unicode 是字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
UTF-8 是编码规则: 将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)强调:UTF-8 是 Unicode 的实现方式之一。
GBK:是指中国的中文字符,其它它包含了简体中文与繁体中文字符,另外还有一种字符“gb2312”,这种字符仅能存储简体中文字符
ASCII,GB2312本身既指一种字符集,也是一种编码,因为早期字符集和编码是绑定的,是一整套方案
中文一个字符占2个字节(GBK)或者3个字节(UTF-8)
Unicode是16进制的要存储在计算机需要根据规则UTF-8转换成二进制的来存储
Unicode汉字对应表 http://www.chi2ko.com/tool/CJK.htm
三、中文bytes为啥是负数
public static void main(String[] args) {
// 将中字转换成byte数组
byte[] bytes = "我".getBytes();
// 控制台得到[-26, -120, -111]
System.out.println(Arrays.toString(bytes));
}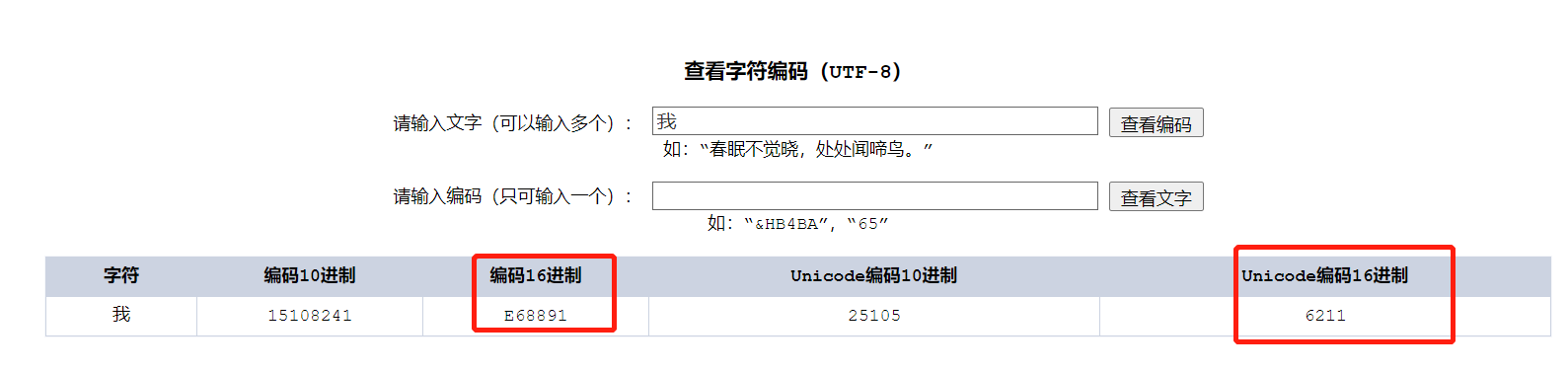
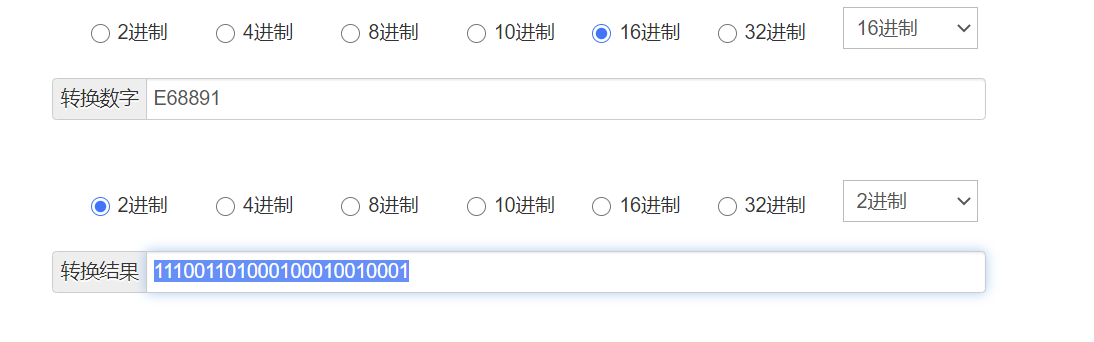
| 16进制 | E6 | 88 | 91 |
| 2进制 | 11100110 | 10001000 | 10010001 |
| 去掉补码 | 11100101 | 10000111 | 10010000 |
| 反码 | 00011010 | 01111000 | 01101111 |
| 十进制 | 26 | 120 | 111 |