1 基本使用方法
sklearn.cluster.DBSCAN(
eps=0.5,
*,
min_samples=5,
metric='euclidean',
metric_params=None,
algorithm='auto',
leaf_size=30,
p=None,
n_jobs=None)2 主要参数介绍
| eps | 邻域半径 |
| Min_samples | 最少点数目 |
3 属性
| core_sample_indices_ | 核心点的index |
| components_ | 核心点的复制 |
| labels_ | 每个样本的类别label,noise是-1 |
4 举例
4.1 简单的例子
from sklearn.cluster import DBSCAN
import numpy as np
X = np.array([[1, 2], [2, 2], [2, 3],
[8, 7], [8, 8], [25, 80]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
#array([ 0, 0, 0, 1, 1, -1], dtype=int64)4.2 带可视化的例子
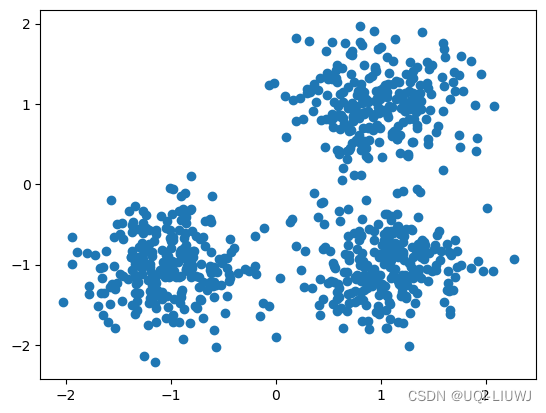
4.2.1 数据集
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(
n_samples=750, centers=centers, cluster_std=0.4, random_state=0
)
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1])
plt.show()sklearn 笔记:make_blobs 生成聚类数据_random_state=3_UQI-LIUWJ的博客-CSDN博客
4.2.2 DBSCAN预测
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
labels = db.labels_
#-1是noise
n_clusters_ = len(set(labels))-1
#不考虑noise的情况下,类别数量
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
'''
Estimated number of clusters: 3
Estimated number of noise points: 22
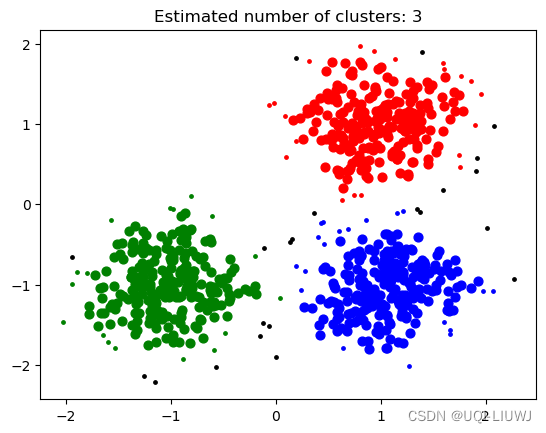
'''4.2.3 可视化
unique_labels = set(labels)
core_samples_mask = np.zeros_like(labels, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
#表示样本是否是核心点的mask 向量
colors = ['black','red','green','blue']
for k, col in zip(unique_labels, colors):
color=colors[k+1]
class_member_mask = (labels == k)
#哪些样本是类别k 的mask矩阵
xy = X[class_member_mask & core_samples_mask]
plt.scatter(
xy[:, 0],
xy[:, 1],
s=40,
c=color)
xy = X[class_member_mask & ~core_samples_mask]
plt.scatter(
xy[:, 0],
xy[:, 1],
s=6,
c=color)
#核心点,非核心点分开画
plt.title(f"Estimated number of clusters: {n_clusters_}")
plt.show()