一.单项冒泡排序
单向冒泡排序从左到右遍历列表,比较每对相邻的元素,如果它们的顺序不正确,则交换它们。在第一轮迭代之后,最大的元素就会被放置在列表的最后面。然后,算法继续进行下一轮迭代,但这次只需要比较和交换前n-1个元素,因为列表的最后一个元素已经确定了。如此反复进行,直到所有元素都被排好序。
它的时间复杂度为O(n^2)
创建一个数组(这里的单向冒泡排序我利用哨兵的写法讲解)
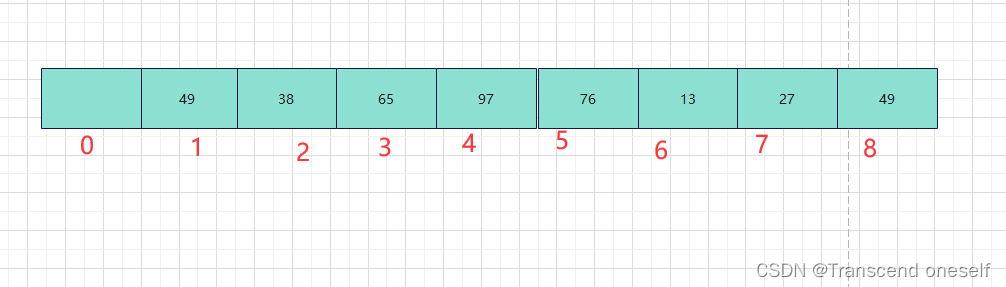
进行排序
像这种冒泡排序是通过比较数组相邻元素的值进行比较然后交换元素的位置从而达到排序的效果,所以我们会多次使用的交换这个操作,我们此处可以实例化一个swap函数用来交换,但是一定要记住用指针的形式传参,这样才可以在另一个函数里面改变冒泡排序里面面要改变的元素
void swap(int* x, int* y)
{
int temp = *x;
*x = *y;
*y = temp;
}
1.算法思路
先将整个数组从第二个元素开始遍历,然后第二层循环就是让外层数组的每一个元素跟内层循环遍历的元素一一进行比较,然后根据条件进行交换从而达到排序的效果
2.循环流程
第一趟循环
就是让38和49比较,这里38小于49所以进行交换操作得到下面数组

第二趟循环
本次循环时65和49比较,这里65大于49,符合我们升序的标准,自然这里不会进入交换的函数,直接进入下一趟循环

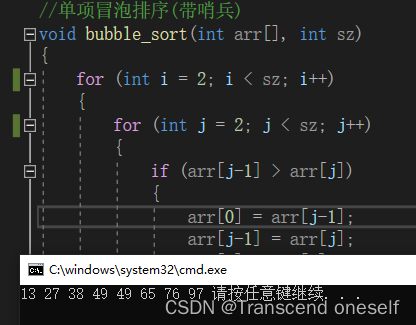
3.伪代码实现
void bubble_sort(int arr[], int sz)
{
for (int i = 2; i < sz; i++)
{
for (int j = 2; j < sz; j++)
{
if (arr[j-1] > arr[j])
{
arr[0] = arr[j-1];
arr[j-1] = arr[j];
arr[j] = arr[0];
}
}
}
}
其他循环也是以此类推
最终运行结果
二.双向冒泡排序
1.双向冒泡排序的概念
双向冒泡排序(也称为鸡尾酒排序或定向冒泡排序)是一种变体的冒泡排序算法。该算法从列表的两端开始分别进行冒泡排序,每次将最大值和最小值分别放置在列表的两端。这样可以减少排序的总轮数,但并不能优化排序的时间复杂度,仍然为O(n^2)。
2.双向冒泡排序流程
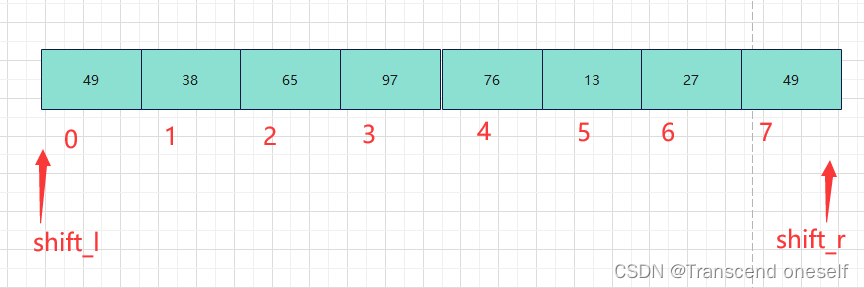
创建好一个数组,定义两个变量来控制排序的终止
从下图可以可看出,当shift_l和shift_r相交时表示排序完成
所以我们不难知道外层循环判断的条件就是shift_l<shift_r
第一躺排序
从左边开始排序
让38和49进行比较,38小于49,两个元素进行交换
跳出循环,让shift_r-1,为了后面的右侧循环让它用倒数第二个元素和倒数第一个元素比较
第二趟循环,右侧循环,让27和49进行比较,27小于49,两个元素符合升序的标准,不需要进行交换.

让shift_l+1,让它进行下一趟的单项循环
其他循环也是和上述一样的操作,直到shift_l和shift_r相交,说明排序完成.
3.双向冒泡排序伪代码
void swap(int* x, int* y)
{
int temp = *x;
*x = *y;
*y = temp;
}
//双向冒泡排序
void doublebubble_sort(int arr2[], int sz)
{
int i = 0;
int shift_l = 0;
int shift_r = sz - 1;
while (shift_l < shift_r)
{
for (i=shift_l; i < shift_r; i++)
{
if (arr2[i] > arr2[i+1])
{
swap(&arr2[i], &arr2[i+1]);
}
}
shift_r--;//让右侧排序从倒数第二个开始与它右侧元素比较
for (i = shift_r;i> shift_l; i--)
{
if (arr2[i] < arr2[i-1])
{
swap(&arr2[i], &arr2[i-1]);
}
}
shift_l++;
}
}
三.总结
冒泡排序是一种简单的排序算法,它重复地遍历要排序的数组,比较每对相邻的元素,并按照顺序交换它们的位置,直到没有任何一对元素需要交换为止。冒泡排序的时间复杂度为O(n^2),其中n为要排序的元素个数。虽然冒泡排序的效率不是很高,但是它的实现简单易懂,适合排序元素个数较少的数组,适用场景与我上期的希尔排序恰恰相反,如果对希尔排序有疑问,请看我上期希尔排序.
希尔排序链接:http://t.csdn.cn/6BGXf