上一章我们从统计学角度学习了贝叶斯网络中点与点的关系,并没有真正涉及因果的重要内容,因为基于的都是条件概率,没有牵扯到干预,而干预是因果很重要的操作,这一章我们从干预开始,进一步学习如何识别因果图中的因果量。
首先让我们回顾并正式定义第一章中提到的干预–do操作。
The do-operator

如图1所示,conditioning和intervening是不同的操作。conditioning on T=t(在T=t条件下)表示我们只关注数据中T=t的 子集 ,而intervening指对整个数据进行T=t的处理,即do(T=t),在do(T=t)时,潜在结果分布满足以下等式:
P ( Y ( t ) = y ) ≜ P ( Y = y ∣ d o ( T = t ) ) ≜ P ( y ∣ d o ( t ) ) P(Y(t)=y)\triangleq P(Y=y|do(T=t)) \triangleq P(y|do(t)) P(Y(t)=y)≜P(Y=y∣do(T=t))≜P(y∣do(t))
因此在干预下,ATE可以写作:
E [ Y ∣ d o ( T = 1 ) ] − E [ Y ∣ d o t ( T = 0 ) ] E[Y|do(T=1)]-E[Y|dot(T=0)] E[Y∣do(T=1)]−E[Y∣dot(T=0)]。
The Main Assumption:Modularity
模块化。
定义因果中独特的干预操作后,仿照上一章贝叶斯图的思路,如果我们想分析因果中复杂的关系,我们先需要一个局部假设,Modularity(模块化):
如果干预集合 S S S,将S内节点固定为常量,则对于因果图中的点i,
- 如果 i ∉ S i \notin S i∈/S, P ( x i ∣ p a i ) P(x_i|pa_i) P(xi∣pai)保持不变。
- 如果 i ∈ S i \in S i∈S,且 x i x_i xi与干预之前的值 x i ′ x_i' xi′相同,则 P ( x i ∣ p a i ) = 1 P(x_i|pa_i)=1 P(xi∣pai)=1,否则 P ( x i ∣ p a i ) = 0 P(x_i|pa_i)=0 P(xi∣pai)=0
通俗来说,modularity确保因果图中对于变量 X i X_i Xi的干预只会改变 X i X_i Xi本身的概率(类比local Markov assumption),如图2所示。等价于移除所有指向 X i X_i Xi的因果边。如果干预X=1,则 P ( X = 1 ∣ p a i ) = 0 , P ( X ≠ 1 ∣ p a i ) = 0 P(X=1|pa_i)=0, P(X\neq 1|pa_i)=0 P(X=1∣pai)=0,P(X=1∣pai)=0,我们称被移除了边的图为manipulated graph。

有了Modularity假设之后,我们可以在一个因果图中嵌入多个分布,比如 P ( Y ) , P ( Y ∣ d o ( T = t ) ) , P ( Y ∣ d o ( T = t ′ ) ) 和 P ( Y ∣ d o ( T 2 = t 2 ) ) P(Y), P(Y|do(T=t)),P(Y|do(T=t'))和P(Y|do(T_2=t_2)) P(Y),P(Y∣do(T=t)),P(Y∣do(T=t′))和P(Y∣do(T2=t2))。如果没有假设,这些分布就需要构造多个图去表示,当满足Markov assumption 和 Modularity 假设 时,便得到了causal Bayesian networks。
Truncated Factorization
继续跟着上一章的思路,现在我们有了因果图的局部假设:Modularity,于是可以推出因果图的分解方法:Truncated Factorization(截断分解)。首先回顾贝叶斯网络分解公式,如果P关于G是马尔科夫的,则P可分解为:
P ( x 1 , . . . , x n ) = ∏ i P ( x i ∣ p a i ) P(x_1,...,x_n)=\prod_iP(x_i|pa_i) P(x1,...,xn)=∏iP(xi∣pai)
再进一步,假定P关于满足Markov assumption和Modularity,给定干预集合S,如果x与干预值一致(Modularity第二点),则
P ( x 1 , . . . , x n ∣ d o ( S = s ) ) = ∏ i ∉ S P ( x i ∣ p a i ) P(x_1,...,x_n|do(S=s))=\prod_{i\notin S}P(x_i|pa_i) P(x1,...,xn∣do(S=s))=∏i∈/SP(xi∣pai),否则, P ( x 1 , . . . , x n ∣ d o ( S = s ) ) = 0 P(x_1,...,x_n|do(S=s))=0 P(x1,...,xn∣do(S=s))=0
利用Truncated Factorization便可以进行causal identification,比如对于图3识别P(y|do(t)):
贝叶斯网络分解: P ( y , t , x ) = P ( x ) P ( t ∣ x ) P ( y ∣ t , x ) P(y, t, x)=P(x)P(t|x)P(y|t,x) P(y,t,x)=P(x)P(t∣x)P(y∣t,x)
Truncated Factorization: P ( y , x ∣ d o ( t ) ) = P ( x ) P ( y ∣ t , x ) P(y,x|do(t))=P(x)P(y|t,x) P(y,x∣do(t))=P(x)P(y∣t,x)
Marginalize: P ( y ∣ d o ( t ) ) = ∑ x P ( y ∣ t , x ) P ( x ) ≠ ∑ x P ( y ∣ t , x ) P ( x ∣ t ) = ∑ x P ( y , x ∣ t ) = P ( y ∣ t ) P(y|do(t))=\sum_x P(y|t, x)P(x)\neq \sum_x P(y|t, x)P(x|t)=\sum_x P(y, x|t)=P(y|t) P(y∣do(t))=∑xP(y∣t,x)P(x)=∑xP(y∣t,x)P(x∣t)=∑xP(y,x∣t)=P(y∣t)
通过这三步可以识别出P(y|do(t))的因果量,还证明了其与统计量P(y|t)之间的区别。
Backdoor Adjustment
后门调整。
继续回忆上一章,我们根据点与点的关系提出了blocked概念,对于单条路径,如果:
- 路径中存在chain …->W->…或者fork…<-W->…结构, W ∈ Z W\in Z W∈Z
- 路径中存在collider …->W<-…, W ∉ Z W \notin Z W∈/Z且W的子孙 d e ( W ) ∉ Z de(W)\notin Z de(W)∈/Z
则称X和Y之间的这条路径被条件集Z blocked(阻断),条件集Z可以是空集。与之相对,unblocked路径便是不满足blocked条件的路径。
我们将目光聚焦于T和Y之间的关系,定义T和Y间除了直连路径的unblocked路径为backdoor paths(后门路径),如图3中的T<-X->Y路径,像是在T->Y路径之外开了“后门”一样。
再基于后门路径,得到定义backdoor criterion(后门准则):关于T和Y,如果一组变量集合W满足:
- W blocks 所有从T到Y的 backdoor paths
- W 中不包括任何 T 的子孙
则W满足后门准则。满足后门准则的变量集合被称为sufficient set(充分集)。给定sufficient set W,可以识别:
P ( y ∣ d o ( t ) ) = ∑ w P ( y ∣ d o t ( t ) , w ) P ( w ∣ d o ( t ) ) P(y|do(t))=\sum_wP(y|dot(t),w)P(w|do(t)) P(y∣do(t))=∑wP(y∣dot(t),w)P(w∣do(t))(positivity)
= ∑ w P ( y ∣ t , w ) P ( w ∣ d o ( t ) ) =\sum_wP(y|t,w)P(w|do(t)) =∑wP(y∣t,w)P(w∣do(t))(后门准则)
= ∑ w P ( y ∣ t , w ) P ( w ) =\sum_wP(y|t,w)P(w) =∑wP(y∣t,w)P(w)(do操作的性质,移除所有指向t的边)
根据这个识别过程,便得到了backdoor adjustment,即
给定Modularity assumption,positivity assumption 且 W 满足backdoor criterion,我们可以识别T到Y的因果效应为:
P ( y ∣ d o ( t ) ) = ∑ w P ( y ∣ t , w ) P ( w ) P(y|do(t))=\sum_wP(y|t,w)P(w) P(y∣do(t))=∑wP(y∣t,w)P(w)
Relation to d-separation
我们比较上一章的d-separation和本章的backdoor adjustment,可以发现backdoor adjustment其实就是对后门路径的d-separation。
Relation to Potential outcome
本章的后面调整和第二章潜在结果框架中提到的后门公式极为相似,后门公式如下:
E [ Y ( 1 ) − Y ( 0 ) ] = E W [ E [ Y ∣ T = 1 , W ] − E [ Y ∣ T = 0 , W ] E[Y(1)-Y(0)]=E_W[E[Y|T=1, W]-E[Y|T=0, W] E[Y(1)−Y(0)]=EW[E[Y∣T=1,W]−E[Y∣T=0,W]
后门调整为:
P ( y ∣ d o ( t ) ) = ∑ w P ( y ∣ t , w ) P ( w ) P(y|do(t))=\sum_wP(y|t,w)P(w) P(y∣do(t))=∑wP(y∣t,w)P(w)
我们对后门调整公式的y求期望,得到:
E [ Y ∣ d o ( t ) ] = ∑ w E [ Y ∣ t , w ] P ( w ) = E W E [ Y ∣ t , W ] E[Y|do(t)]=\sum_wE[Y|t,w]P(w)=E_WE[Y|t,W] E[Y∣do(t)]=∑wE[Y∣t,w]P(w)=EWE[Y∣t,W],然后对T=1和T=0的期望求差:
E [ Y ∣ d o ( T = 1 ) ] − E [ Y ∣ d o ( T = 0 ) ] = E W [ E [ Y ∣ T = 1 , W ] − E [ Y ∣ T = 0 , W ] ] E[Y|do(T=1)]-E[Y|do(T=0)]=E_W[E[Y|T=1,W]-E[Y|T=0,W]] E[Y∣do(T=1)]−E[Y∣do(T=0)]=EW[E[Y∣T=1,W]−E[Y∣T=0,W]],得到后门公式,可见二者等价。
与潜在结果框架不同的是,因果图框架给出了数据顶点间的关系,根据这些关系我们可以直观地挑选W以满足后门准则。
至此,我们仿照第三章学习了因果贝叶斯网络的识别过程,下面我们再进一步,学习更纯粹的因果图。
Structural Causal Models(SCMs)
结构因果模型。潜在结果模型和结构因果模型是因果推理的两大主要模型。
我们先从学习模型的基本术语开始。
Structural Equations
结构等式。
首先,常规的“=”并不能满足因果的需求,因为常规的“=”是都城,“A=B"就等价于“B=A”,这其中并没法嵌入A和B的因果关系,因此我们需要一个能嵌入因果信息的“=”,即Structural Equations:
B:=f(A)
“:=”是非对称的,意味着A是B的因。f表示A到B的函数,函数f不需要被指定,当f不被指定时,函数处于无参的领域,因为我们没有针对参数形式设定任何假设。
结构因果模型还引入了我们之前一直没有深究的未观测变量,得到结构等式:
B : = f ( A , U ) B:=f(A,U) B:=f(A,U)
U是指未观测变量,也可以理解为A到B因果关系外的背景噪音。有了U,就可以用结构等式表示任何概率关系,比如之前我们经常使用的 P ( x i ∣ p a i ) P(x_i|pa_i) P(xi∣pai)。
借助结构等式,我们可以重新定义因果机制,
direct cause(直接原因):X直接出现在Y的结构等式的右侧,比如 B : = f ( A , U ) B:=f(A,U) B:=f(A,U)中的A。
cause(原因):X是Y的直接原因,或者是Y的原因的原因。
有了以上定义,我们可以得到结构因果模型的定义,一个结构因果模型就是由下列集合构成:
- endogenous variables(内生变量)集合 V
- exogenous variables(外生变量)集合 U
- 函数集合f,生成每一个内生变量作为其他变量的函数

B : = f B ( A , U B ) B:=f_B(A,U_B) B:=fB(A,UB)
C : = f C ( A , B , U C ) C:=f_C(A,B,U_C) C:=fC(A,B,UC)
D : = f D ( A , C , U D ) D:=f_D(A,C,U_D) D:=fD(A,C,UD)
对于结构等式中的因果图,如果它是DAG且噪音变量U是独立的,则该因果图是马尔科夫的,分布P是关于该图马尔科夫的。如果它是DAG但噪音变量不独立,则称该模型为semi-Markov(半马尔科夫)。最后,如果图中有环(不满足DAG)且噪音变量U不独立,则模型是非马尔科夫的。
Interventions
干预在SCM中的表示很简单,干预do(T=t)就等于将T的结构等式定义为T:=t。
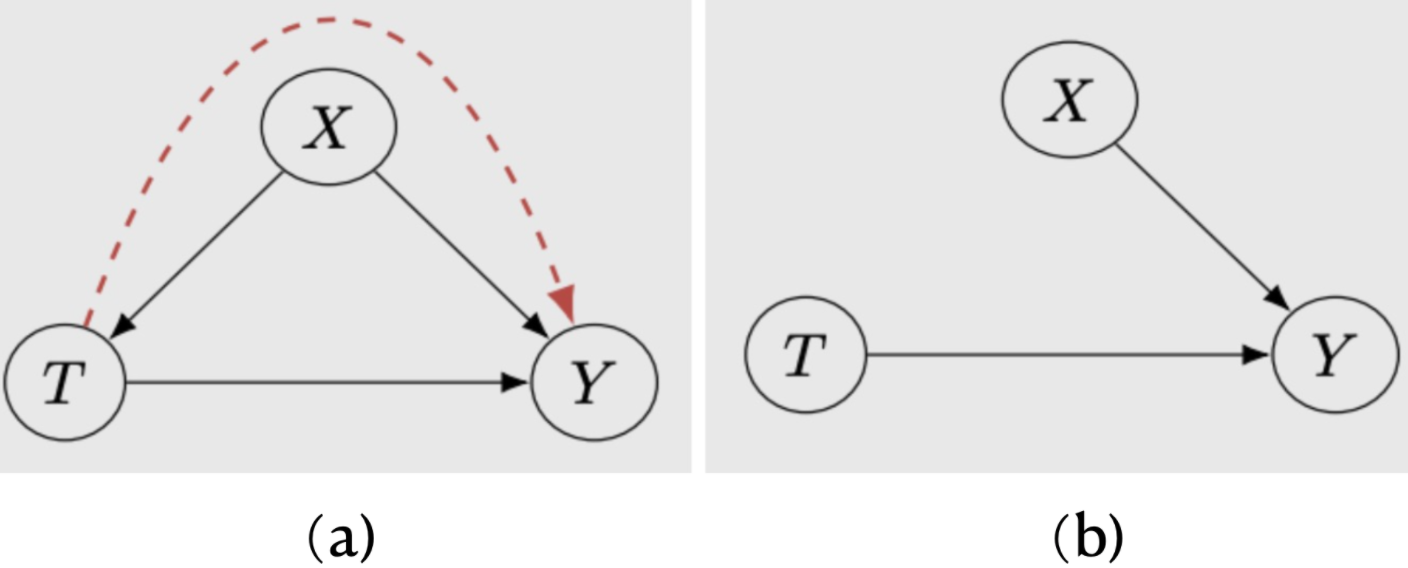
T : = f T ( X , U T ) T:=f_T(X,U_T) T:=fT(X,UT)
Y : = f Y ( X , T , U Y ) Y:=f_Y(X,T,U_Y) Y:=fY(X,T,UY)
干预T为t,得到图5b的因果图, M t M_t Mt:
T : = t T:=t T:=t
Y : = f Y ( X , T , U Y ) Y:=f_Y(X,T,U_Y) Y:=fY(X,T,UY)
由M和 M t M_t Mt,可以定义SCMs中的Modularity assumption:
对于一个 SCM M 和 do(T=t) 干预后的 SCM M t M_t Mt,Modularity assumption 表示 M 和 M t M_t Mt 共享除了T以外的结构等式,且T在 M t M_t Mt中的结构等式为T:=t。
最后我们再学习一个重要定义,反事实法则。刚开始不理解其用处没有关系,我们后面会逐渐加深对其的理解。
The Law of Counterfactuals (and Interventions)
反事实(和干预)法则。
在因果推理中,我们可以使用很多方式表达单位潜在结果,比如在潜在结果模型中,我们使用 Y i ( t ) Y_i(t) Yi(t),我们还可以使用 Y i t , Y t ( u ) Y^t_i, Y_t(u) Yit,Yt(u)。在SCM中,我们可以用 Y t ( u ) Y_t(u) Yt(u)表示单位u在处理t下的观测结果,在干预后的SCM M t M_t Mt中,用 Y M t ( u ) Y_{M_t}(u) YMt(u)表示如果对M执行干预t后Y的潜在结果。
我们定义The Law of Counterfactuals (and Interventions) 为:
Y t ( u ) = Y M t ( u ) Y_t(u)=Y_{M_t}(u) Yt(u)=YMt(u)
如果大家还记得第0章的因果之梯,那么可以察觉到,从这个法则开始i,我们已经登上了由第二层干预到第三层反事实的阶梯。
conclusion
关于因果图我们学习了两类假说,
-
The Modularity Assumption,包括三种形式
- Modularity assumption for Causal Bayesian Networks
- Modularity assumption for SCMs
- The Law of Counterfactuals
-
The Markov Assumption,包括三种等价形式
- Local Markov assumption
- Bayesian network factorization
- Global Markov assumption
给定上述两类假说和positivity,如果因果图还满足后门准则,则该图有可识别性。(no interference 和 consistency 假设都暗藏在因果图的定义中。
这一章我们不断引入假设和符号,思路由贝叶斯网络学到因果贝叶斯网络再到结构因果模型,除了更加了解因果模型本身之外,我想更重要的是学到了前人的思考方式。如果大家感兴趣的话,可以推一推这两章我们不断前进的思路,相信会对初学者有一定的启发。