前言
BLIP相关资料
-
-
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding&Generation 油管yk视频讲解
BLIP2相关资料
BLIP
我对于BLIP的论文还没读通,所以以下内容如有纰漏,恳请读者指正。
以我理解,BLIP论文的实现可以分为三副图叙述:
- Caption和Filter的作用
- 论文基于CapFilter架构的训练流程
- Caption和Filter的模型结构
Caption和Filter
首先,论文会预训练两个组件,Captioner用于为图片生成文本标注,Filter用于过滤噪声的文本标注。观察图片可知,网络上有很多图像-文本对,但由于存在噪声,那些文本不一定能准确描述对应的图片。
图片中,左侧是一张来自网络的蛋糕图片。Captioner为该图片生成了文本,该文本被Filter接受了,它将被加入数据集。而该图片的网络文本被Filter判定为拒绝,它将被剔除。
继续理解可知:
- Captioner和Filter都是可训练的深度模型。它们在执行功能前,要在某个小数据集上先微调一下。
- Filter会做一个二分类任务,判断文本是否能接受,如果能接受,则该图像-文本对会被加入数据集;如果被拒绝,则该图像-文本对会被剔除数据集。

CapFilter架构的训练流程
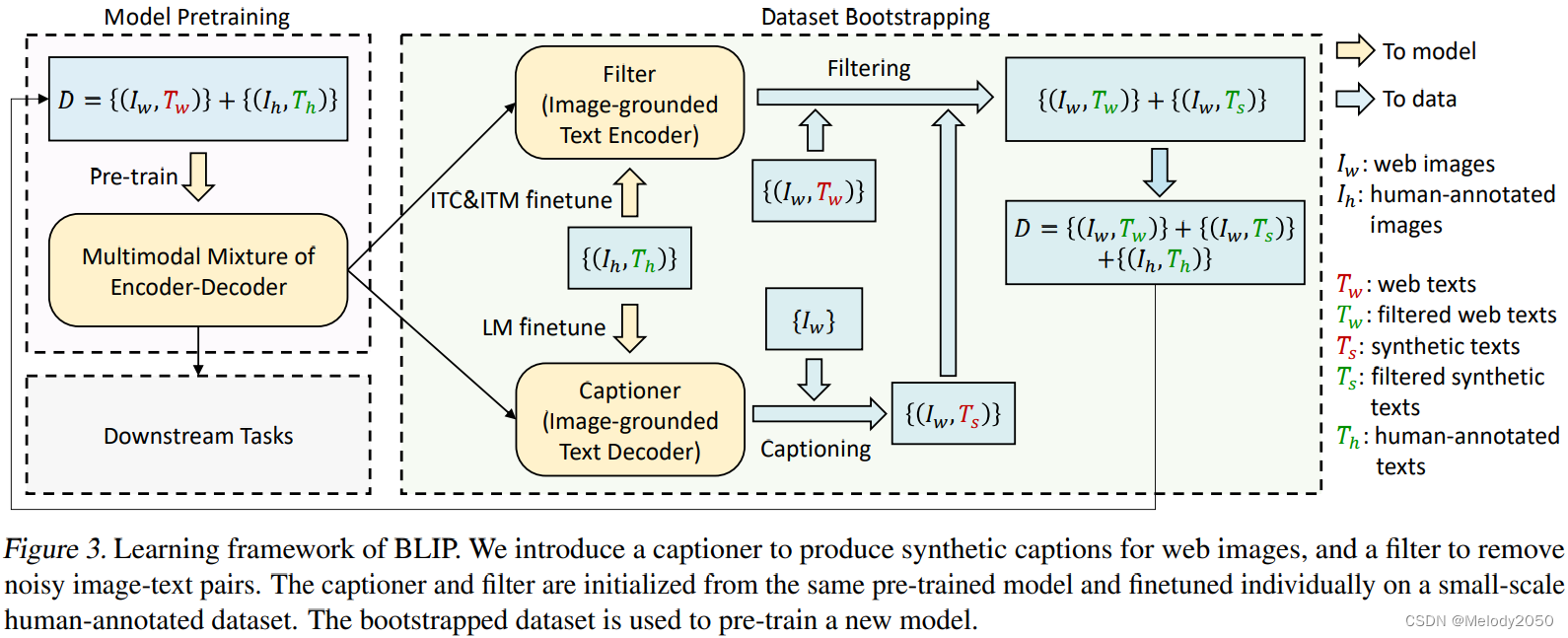
首先,模型的一个Loop可以分为Model Pretraining和Datset Bootstrapping先后的两部分,在完成了若干个Loop后,模型将能用于Downstream Tasks。黄色箭头代表数据流向了模型,代表数据会用于模型的训练。蓝色箭头代表数据流向了数据集,代表数据会拓展数据集。
首先,数据集由图像-文本标注对组成。存在人工精确标注的小数据集 ( I h , T h ) (I_h, T_h) (Ih,Th),网络的大数据集 ( I w , T w ) (I_w,T_w) (Iw,Tw)。前者的文本很精确,但数量少,后者的文本存在噪音,但数量大。
如果将存在噪音的数据直接用于训练模型,那效果可能不好,模型会被"教坏"。所以怎么办呢?
- 我们先在人工标注数据集上微调一个图文匹配判别器Filter以及一个文本标注生成器Captioner,由于这个小数据集是相对纯洁的,教出来的模型表现会稳定,只是泛化性能不够。
- 然后我们要筛选网络数据集。
- 用微调后的Captioner为网络图片生成文本,这样每个网络图片都对应一条网络文本和一条生成文本。
- 用微调后的Filter判断以下两个图文对(网络图片,网络文本)和(网络图片,生成文本)中谁要被拒绝,谁要被接受。
- 将上一步中被接受的图文对,与初始的人工数据集合并,组合成新的大数据集。
- 最后,新的大数据集将能用于新一轮Loop的模型训练。
以下是笔者没弄明白的地方:
- Filter只判断图文是否匹配,那如果网络文本和合成文本同时被拒绝,或者同时被接受,怎么办?取匹配分数较高的那个吗?
- 这种训练只有一轮Loop,还是有多轮Loop?
- 到第二轮Loop时,数据集D已经是人工+网络数据,哪些数据会用于finetune,又有哪些更多的数据用于Filter?
- 有没有可能,论文用了Boosting的做法,网络数据集被分为多份,每轮Loop都会新增一份网络数据集,用于扩充D,并用于下一轮Loop的微调。
Caption和Filter的模型结构

Caption和Filter的模型结构如图所示。有一个Image Encdoer,和三个Text Encoder。它们被组合用于三个目标函数ITC、ITM和LM。
- Filter使用了ITC和ITM目标函数来微调。其目的在于判断图文是否匹配。
- Caption使用了LM目标函数来微调。其目的在于生成文本。
两个模型存在很多共用参数的部分:
- 两者的Image Encoder是共享参数的。
- 两者的Text Encoder中的Cross Attention和Feed Forward部分都是共享参数的。
所以,据我理解,在一个训练迭代中,一个图像文本对能同时用于计算在三个训练损失。
可阅读原文“Pre-training Objectives”