目前多模态大模型的发展趋势:
- 上游,用
海量数据预训练多模态Foundation Model,一般都是自监督。 - 下游,用
特定领域任务的高质量数据微调迁移,然后部署。
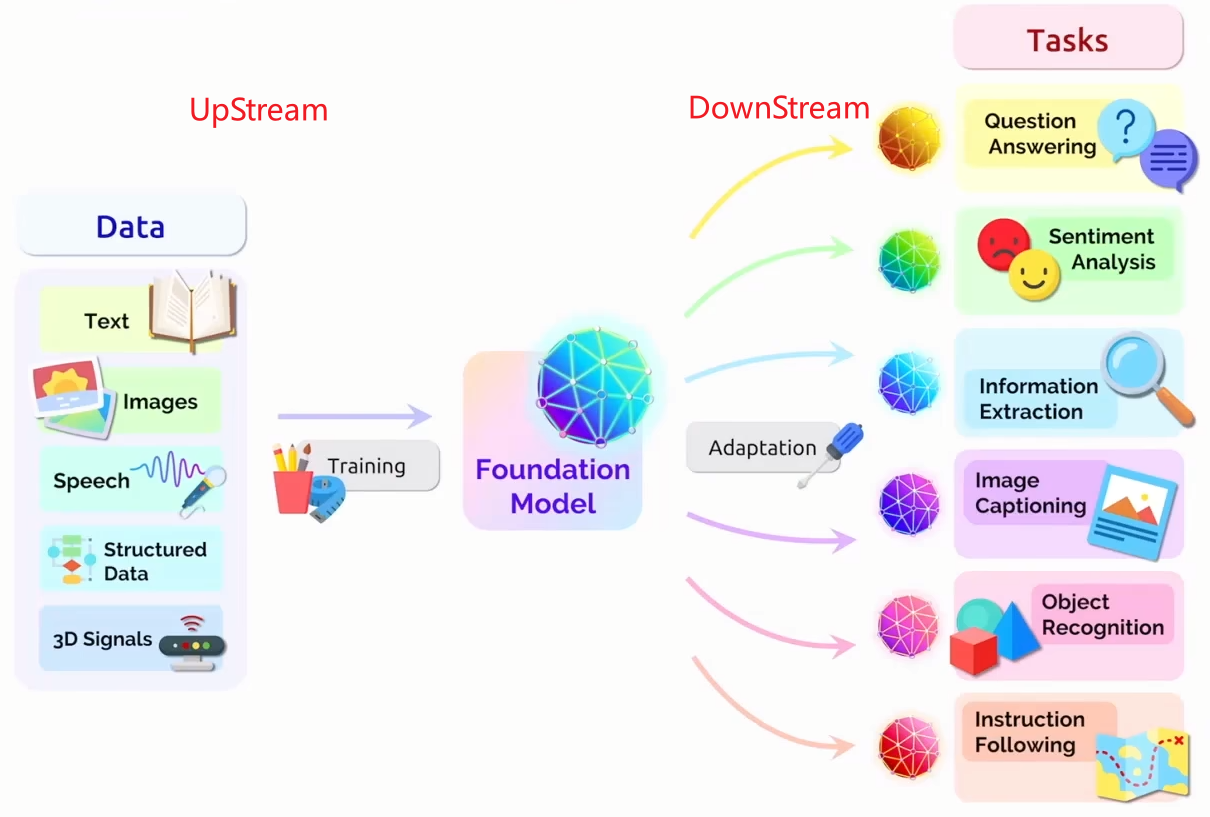
上/下游任务:上游训模型,下游做应用。
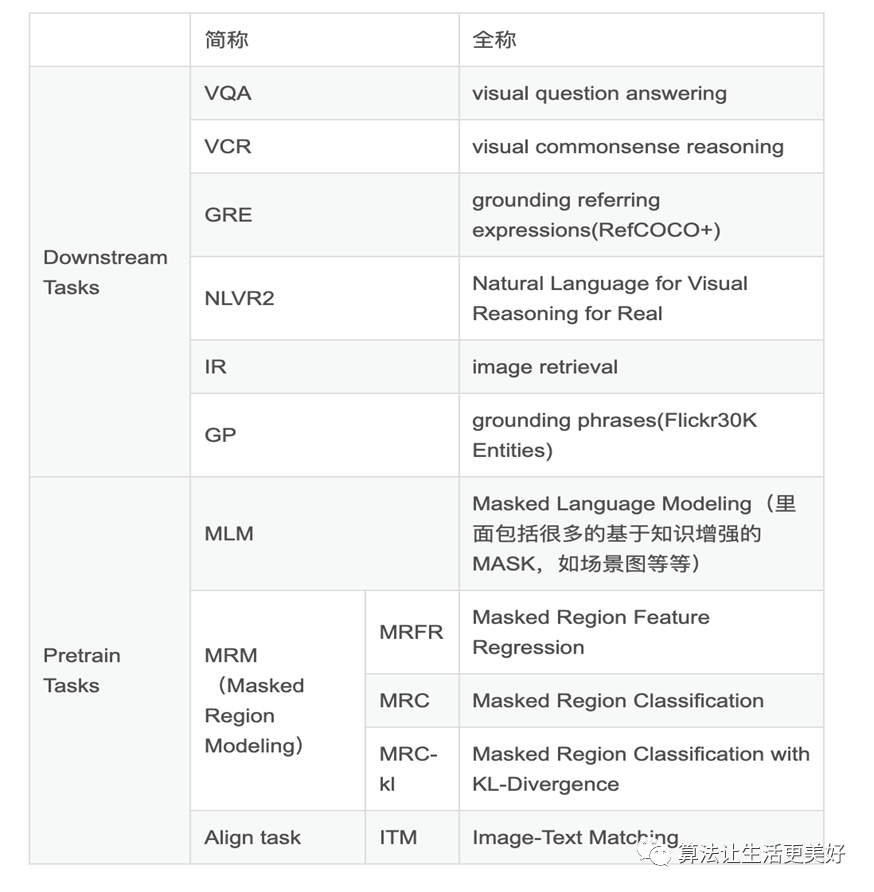
(1) IR里面包括图片检索文本任务Image Retrieval (IR) 和文本检索图片任务Text Retrieval (TR)。
(2) GRE和GP是差不多类型的任务都是根据一段文本的描述取定位到图像对应的region,使用的fintune的数据集不一样如上。
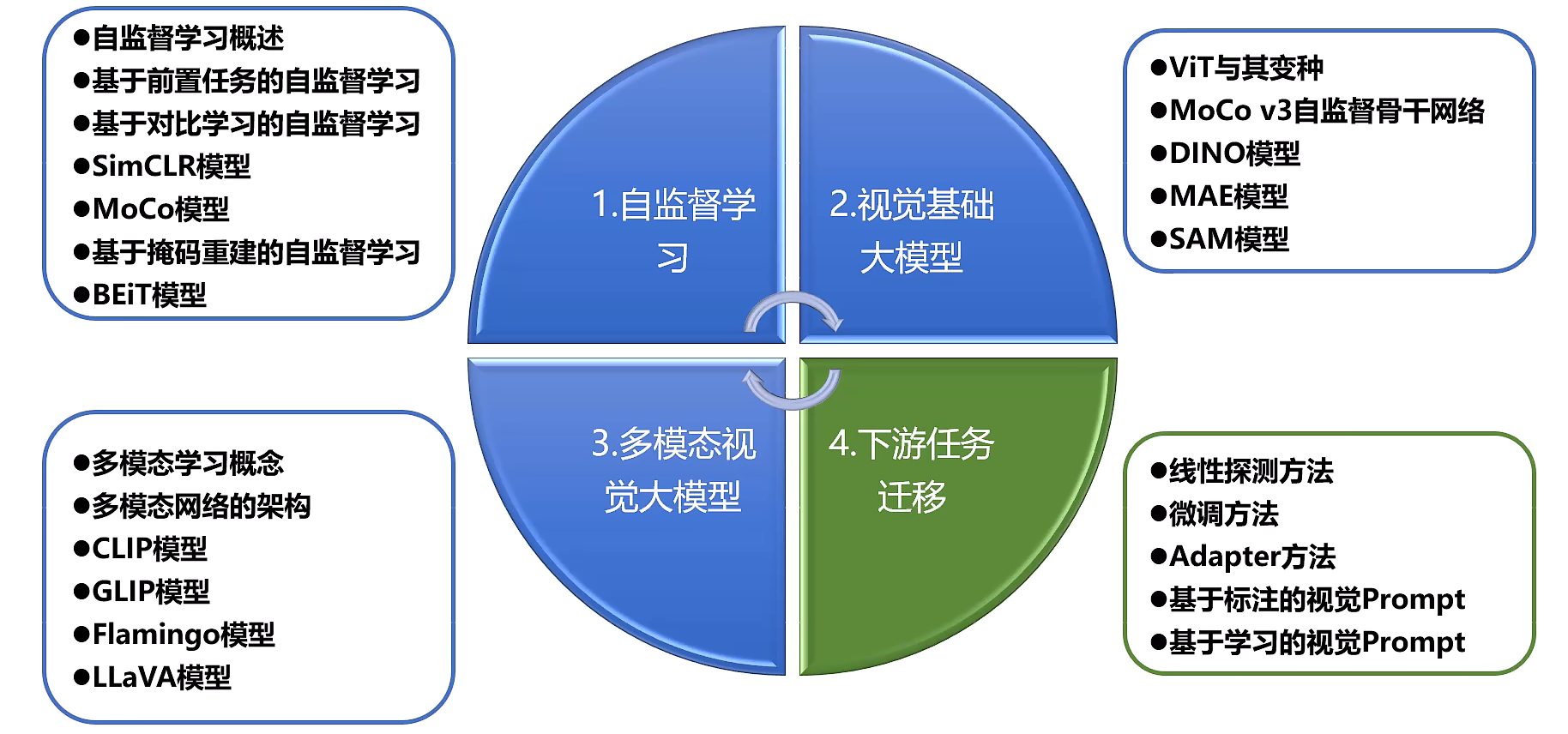
接下来将按照:自监督预训练,经典预训练方法,下游微调这3部分展开:
自监督预训练
看我知乎的文章:视觉(image)自监督预训练方案总结
经典模型
多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读
MLLM多模态(BLIP2,CLIP,LLaVA,MiniGPT4,mPLUG-Owl)

CLIP (Contrastive Language-Image Pre-training)
BLIP的 high level 理解能力比CLIP强:
-
CLIP是Contrastive Pre-training对比学习预训练(图文对比学习,本质是
understanding理解)。

-
BLIP是多任务预训练(图文对比学习+图文匹配+文本生成:本质是
understanding理解+generation生成)。不仅有image和text的encoder,还有text的decoder。其中text的编码器和解码器都是基于image的(cross attention注入了)。扫描二维码关注公众号,回复: 17331865 查看本文章
下游迁移
不再是之前有监督的Finetune,而是更加高效的迁移技术。