KMeans聚类
KMeans官方文档:
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
GitHub文档地址:https://github.com/gao7025/cluster_kmeans
基本思路
聚类分析是根据在数据中发现的描述对象及其关系的信息,将数据对象分组。目的是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内相似性越大,组间差距越大,说明聚类效果越好。KMeans算法,对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,是类别内数据相似度较大,而类别间相似度较小。
*class sklearn.cluster.KMeans(n_clusters=8, , init=‘k-means++’, n_init=10, max_iter=300, tol=0.0001, precompute_distances=‘deprecated’, verbose=0, random_state=None, copy_x=True, n_jobs=‘deprecated’, algorithm=‘auto’)
主要有以下几步:
- 选择数据,设定K值为m类
- 初始化中心点,随机选取n个
- 将离数据点近的点划分到相应类
- 更新类的中心
- 重新将离数据近的点划分到相应类
- 重复以上两个步骤,直到类中心不再变化
举例说明聚类过程
如下表所示,有6个样本及对应的坐标数值,并画出散点图查看可大致聚类的分组,可以看出聚成两类或三类是比较合适的,本例以聚成两类举例说明聚类过程。
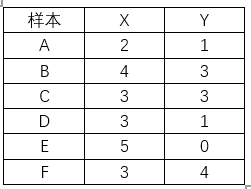
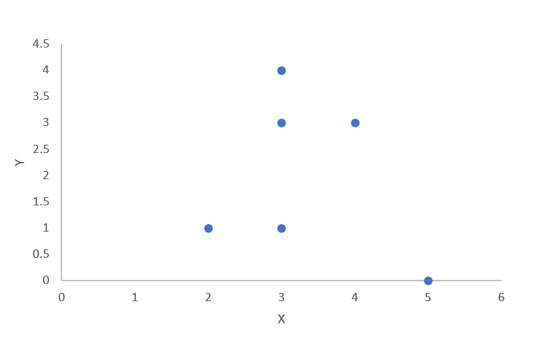
详细过程:
1.设定K=2,聚成两类
2.随机选取初始的两个点,如选取A、B
3.分别计算其他各点到A、B的距离(以欧式距离为例)
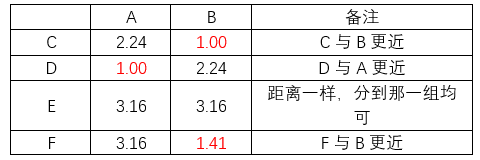
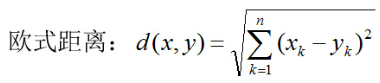
新的分组:
第一组:B、C、F
第二组:A、D、E
4.计算新的分组类中心:
第一组:( (4+3+3)/3 , (3+3+4)/3 ) = (3.33 , 3.33)
第二组:( (2+3+5)/3 , (1+1+0)/3 ) = (3.33 , 0.67)
5.再次分别计算其他各点到新的分组两个类中心的距离
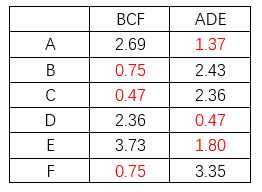
此时,我们发现,分组没有变化,聚类收敛,聚类过程结果,否则继续重复1、2、3的过程,直到收敛结束聚类。
优点:
- 算法原理简单,容易实现,小数据集运行效率高
- 可解释强,适用于高维数据的聚类
- 贪心算法策略,提高了局部最优点的质量,使收敛的速度更快
缺点:
- 也正是由于贪心算法,容易导致局部收敛,在大规模数据集上计算较大,求解较慢
- 对异常值和噪声点敏感,影响聚类的结果
效果评价
从簇内的稠密程度和簇间的离散程度来评估聚类的效果,常见的方法有轮廓系数Silhouette Coefficient和Calinski-Harabasz Index
- 轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。
- 类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数会高。
代码示例
def kmeans_clusters(X, n, y):
np.random.seed(123)
if y == 'y':
scaler = MinMaxScaler()
scaler.fit(X.astype(float))
X = scaler.transform(X)
est = KMeans(n_clusters=n)
est.fit(X)
return X, est
效果示例
