这是我老师给我的一份数据集,用于练习,我把我的心路历程push出来,也都是一些很基础的聚类方法,非常适合初学者入门。
先上数据集:
https://pan.baidu.com/s/1i5Y3_anBjsxGVird3oZyTA
提取码:iy5a
里面是一个breast的txt文件,700个样本,10维的数据,前九维是属性,最后一维是类别标签,对了这里声明一下,我后面的操作都是做的无监督的情况,也就是没有最后一维的参考之下的操作,不是什么机器学习方法,就是比较基础的聚类,然后用最后第十维的类别标签进行聚类效果的打分。(这里我使用的是比较苛刻的标准NMI)
这里我使用的python所以先把用到的库给大家:
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA,KernelPCA
from sklearn.cluster import DBSCAN
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import numpy as np
import pandas as pd
from sklearn import metrics
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
1.拿到数据,首先要观察和预处理
不过话是这么说,这次的数据在完全没有背景信息的情况下,我们甚至不知道每个属性到底代表什么意思,所以什么相关性分析完全是不靠谱的。所以
我直接用PCA降维,降到三维,用散点图进行观察,同时也可以看一下各个维度的信息量的情况。直接上代码:
#获取输入 科学计数
def getInputDatasetFloat(filePath):
with open(filePath,'r') as f:
dataSet=list()
lines=f.readlines()
for line in lines:
data0=list()
temp1=list()
line=line.strip()
temp=line.split()
for i in temp:
temp1.append(float(i))
temp=list(np.array(temp1))
temp=np.array(temp[:9])
data0.extend(temp)
dataSet.append(data0)
return dataSet
def sk_PCA3(dataSet):
PCA_modal=PCA(n_components=3)
reducedData=PCA_modal.fit_transform(dataSet)
ratio=PCA_modal.explained_variance_ratio_
sum=0.0
for i in ratio:
sum+=i
print(sum)
return reducedData
def k_mean(dataSet):
t_pred=KMeans(n_clusters=4,random_state=11,max_iter=1000,algorithm='full').fit_predict(dataSet)
# print(t_pred)
# with open(r"C:\Users\hp\Desktop\resultPCA.txt","a+") as f:
# for i in t_model.predict(dataSet):
# f.write(str(i))
# f.write("\n")
return list(t_pred)
data=getDataSetFloat(path)
_data=sk_PCA3(data)
prediction=np.array(k_mean(_data))
fig=plt.figure()
ax=Axes3D(fig)
ax.scatter3D(_data[:,0],_data[:,1],_data[:,2],c=prediction)
plt.show()
这里我先简单的使用了一下kmean进行分类,因为我知道是分成两类,所以我就先把k设置为2
得到散点图
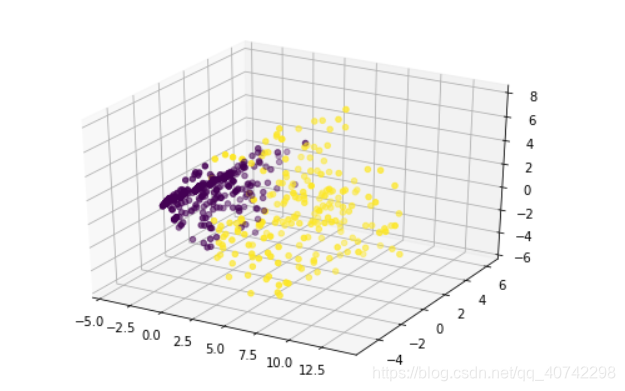
其实当我画出来这幅图了我就基本上知道这次老四会给的数据非常的规则,没有那么高的处理难度。以为可以看到噪声点比较少,而且基本上是服从高斯分布,也就是我们所说的凸数据的,所以其实简单的kMeans也会有比较好的效果。当然,我决定先用kmeans去尝试。
kmeans+PCA
首先先简单看一下kmeans的效果,这里我用的是sklearn的KMeans,当然我会在后面告诉大家PCA、Kmeans、dbscan这些方法的手动实现。这里我就偷懒了
d=getInputDataset(r"C:\Users\tianyu\Desktop\breast.txt")
pred=KMeans(n_clusters=2).fit_predict(d)
print(pred)
metrics.normalized_mutual_info_score(answers,pred)
结果:0.7360879788837636
这个NMI数值已经非常高了,大家可以去看看NMI的实现,基本上正确率已经很高了,我看到这个结果完全觉得老师给的太简单了。
不说废话我觉得9维数据维度上可以做做文章,于是我用PCA降维再去看一下结果。
def sk_PCAn(dataSet,n):
PCA_modal=PCA(n_components=n)
reducedData=PCA_modal.fit_transform(dataSet)
ratio=PCA_modal.explained_variance_ratio_
sum=0.0
for i in ratio:
sum+=i
print("剩余信息量比例:",sum)
return reducedData
这里的 print(“剩余信息量比例:”,sum)这个比较重要,一般我们选取80到92左右的信息量剩余比例应该是比较好的(这不是绝对的)
我发现降到5维和4维的数据比较好,但是KMEANs的方法也都不如0.7360879788837636。
我给一个我用5d数据Kmeans得到的结果:
kmeans_5d NMI:0.7360879788837638
dbscan+PCA
于是我改用dbscan进行尝试,因为还是回到我们的散点图,其实也同样很适合dbscan,但是我觉得它最大的缺点就是对参数的以来非常大。
上代码:
def dbscan(dataSet,eps,samples):
results=DBSCAN(eps=eps,min_samples=samples).fit_predict(dataSet)
return results
def getAnswers():
with open(r"C:\Users\Desktop\breast.txt","r") as f:
lines=f.readlines()
answer=[]
for line in lines:
line.strip()
token=line.split()
temp=token[9:]
temp=temp[0][:1]
if temp.strip()==str(4):
temp=str(1)
if temp.strip()==str(2):
temp=str(0)
temp=map(int,temp)
answer.extend(temp)
return answer
d=getInputDatasetFloat(r"C:\Desktop\breast.txt")
reduced_d=sk_PCAn(d,5)
reduced_d_4d=sk_PCAn(d,4)
kmeans_pred=KMeans(n_clusters=2).fit_predict(reduced_d)
# print(kmeans_pred)
answers=np.array(getAnswers())
dbscan_pred=dbscan(reduced_d,2.42,8)
# print(y_pred)
a=metrics.normalized_mutual_info_score(answers,dbscan_pred)
b=metrics.normalized_mutual_info_score(answers,kmeans_pred)
print("dbscan_5d NMI:"+str(a))
print("kmeans_5d NMI:"+str(b))
dbscan_pred_4d=dbscan(reduced_d_4d,2.29,33)
c=metrics.normalized_mutual_info_score(answers,dbscan_pred_4d)
print("dbscan_4d NMI:"+str(c))
这里我做了一个对比
得到结果:
剩余信息量比例: 0.9062035486892024 #降到5d
剩余信息量比例: 0.8674796154695146 #降到4d
dbscan_5d NMI:0.7938826494175377
kmeans_5d NMI:0.7360879788837638
dbscan_4d NMI:0.8057291029940312
填坑
其实整个练习非常简单,绝对适合初学者练手,老师留这种作业对我这样的本身对数据科学感兴趣的我本以为没什么用,但是做起来还是踩了一个坑。
我首先将数据集的数据用字符串的方法做切分,都变成一个数据,也就是每个数的第一个数字,然后我再把它变成float,但是这样却导致,kmeans的精度很粗糙,导致一开始的KMeans NMI只有0.53+,难过了我好几天。
给你们看看一开始我读取数据的代码:
#获取输入
def getInputDataset(filePath):
with open(filePath,'r') as f:
dataSet=list()
lines=f.readlines()
for line in lines:
data0=list()
temp1=list()
line=line.strip()
temp=line.split()
for i in temp:
temp1.append(Decimal(i[:1]))
temp=list(np.array(temp1))
temp=np.array(temp[:9])
data0.extend(temp)
dataSet.append(data0)
return dataSet
一开始我给的是对的,这个就是困扰我很久的,虽然现在我还不是特别的明白,不知道有没有知道的帮我解答一下。但是我也是亲身告诉大家下次千万别踩这个坑了。
