生物学中的注意力提示
非自主性提示:
在没有主观意识的干预下,眼睛会不自觉地注意到环境中比较突出和显眼的物体。
比如我们自然会注意到一堆黑球中的一个白球,马路上最酷的跑车等。
自主性提示:
在主观意识的干预下,眼睛带有一定目的性地(可以是模糊的也可以是很具体的目的)注意环境中的某些物体。
比如你想喝水,你就会更加关注水杯、饮水机等物体(哪怕这些东西在平时并不起眼),对电视机等其他物体的关注度就会有所减弱。
注意力机制框架
如果只使用非自主性提示,我们可以使用简单的参数化全连接层,甚至是非参数化的Max Pooling或者Average Pooling来实现。
但如果要包含自主性提示,简单使用全连接或者池化就实现不了了。
所以,“是否包含自主性提示”将注意力机制与全连接层或池化层区别开来。
注意力机制框架包含三个部分:
查询(query): 自主性提示信息
键(key): 非自主性提示信息
值(value): 感官输入
在注意力机制的背景下,给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入,这些感官输入被称为值。
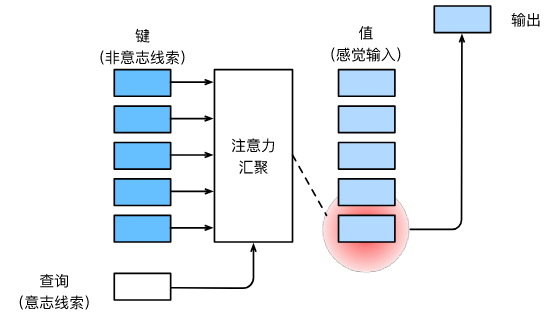
更通俗的解释,每个值都与一个键配对, 在无自主性提示信息的情况下,键自然地映射到值。而引入查询(自主性提示信息)后,系统将会考虑查询和每个键之间的关联性或者相似度(即注意力分数,后面会讲),通过注意力汇聚,引导键值形成更优的映射。
所谓”更优的映射“具有以下特点:如果一个键越是接近给定的查询, 那么分配给这个键对应值的注意力权重就会越大, 也就”获得了更多的注意力“。
注意力汇聚:Nadaraya-Watson 核回归
非参数注意力汇聚
Nadaraya和Watson提出了一个注意力汇聚的方法,根据输入的位置对输出 y i y_i yi进行加权:
f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i , (1) f(x) = \sum_{i=1}^n \frac{K(x - x_i)}{\sum_{j=1}^n K(x - x_j)} y_i,\tag{1} f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi,(1)
其中 K K K是核(kernel),暂且不深入讨论其细节。
从注意力机制框架的角度,我们可以将上式重写为一个更加通用的注意力汇聚(attention pooling)公式:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i , (2) f(x) = \sum_{i=1}^n \alpha(x, x_i) y_i,\tag{2} f(x)=i=1∑nα(x,xi)yi,(2)
其中 x x x是查询, ( x i , y i ) (x_i,y_i) (xi,yi)是键值对。 α ( x , x i ) \alpha(x, x_i) α(x,xi)就是注意力权重(attention weight)。
如果我们使用的核函数为高斯核:
K ( u ) = 1 2 π exp ( − u 2 2 ) . (3) K(u) = \frac{1}{\sqrt{2\pi}} \exp(-\frac{u^2}{2}).\tag{3} K(u)=2π1exp(−2u2).(3)
带入 ( 1 ) (1) (1)得到:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( x − x i ) 2 ) ∑ j = 1 n exp ( − 1 2 ( x − x j ) 2 ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( x − x i ) 2 ) y i . (4) \begin{split}\begin{aligned} f(x) &=\sum_{i=1}^n \alpha(x, x_i) y_i\\ &= \sum_{i=1}^n \frac{\exp\left(-\frac{1}{2}(x - x_i)^2\right)}{\sum_{j=1}^n \exp\left(-\frac{1}{2}(x - x_j)^2\right)} y_i \\&= \sum_{i=1}^n \mathrm{softmax}\left(-\frac{1}{2}(x - x_i)^2\right) y_i. \end{aligned}\end{split}\tag{4} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21(x−xj)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi.(4)
带参数注意力汇聚
如果想让注意力汇聚可学习,也比较好修改,将注意力权重乘上可学习参数即可,注意和 ( 4 ) (4) (4)对比:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( ( x − x i ) w ) 2 ) ∑ j = 1 n exp ( − 1 2 ( ( x − x j ) w ) 2 ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( ( x − x i ) w ) 2 ) y i . (5) \begin{split}\begin{aligned}f(x) &= \sum_{i=1}^n \alpha(x, x_i) y_i \\&= \sum_{i=1}^n \frac{\exp\left(-\frac{1}{2}((x - x_i)w)^2\right)}{\sum_{j=1}^n \exp\left(-\frac{1}{2}((x - x_j)w)^2\right)} y_i \\&= \sum_{i=1}^n \mathrm{softmax}\left(-\frac{1}{2}((x - x_i)w)^2\right) y_i.\end{aligned}\end{split} \tag{5} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21((x−xj)w)2)exp(−21((x−xi)w)2)yi=i=1∑nsoftmax(−21((x−xi)w)2)yi.(5)